 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tutorial on Fluid Antenna System for 6G Networks: Encompassing Communication Theory, Optimization Methods and Hardware Designs
Jul 03, 2024



The advent of the sixth-generation (6G) networks presents another round of revolution for the mobile communication landscape, promising an immersive experience, robust reliability, minimal latency, extreme connectivity, ubiquitous coverage, and capabilities beyond communication, including intelligence and sensing. To achieve these ambitious goals, it is apparent that 6G networks need to incorporate the state-of-the-art technologies. One of the technologies that has garnered rising interest is fluid antenna system (FAS) which represents any software-controllable fluidic, conductive, or dielectric structure capable of dynamically changing its shape and position to reconfigure essential radio-frequency (RF) characteristics. Compared to traditional antenna systems (TASs) with fixed-position radiating elements, the core idea of FAS revolves around the unique flexibility of reconfiguring the radiating elements within a given space. One recent driver of FAS is the recognition of its position-flexibility as a new degree of freedom (dof) to harness diversity and multiplexing gains. In this paper, we provide a comprehensive tutorial, covering channel modeling, signal processing and estimation methods, information-theoretic insights, new multiple access techniques, and hardware designs. Moreover, we delineate the challenges of FAS and explore the potential of using FAS to improve the performance of other contemporary technologies. By providing insights and guidance, this tutorial paper serves to inspire researchers to explore new horizons and fully unleash the potential of FAS.
An Outline of Prognostics and Health Management Large Model: Concepts, Paradigms, and Challenges
Jul 01, 2024



Prognosis and Health Management (PHM), critical for ensuring task completion by complex systems and preventing unexpected failures, is widely adopted in aerospace, manufacturing, maritime, rail, energy, etc. However, PHM's development is constrained by bottlenecks like generalization, interpretation and verification abilities. Presently, generative artificial intelligence (AI), represented by Large Model, heralds a technological revolution with the potential to fundamentally reshape traditional technological fields and human production methods. Its capabilities, including strong generalization, reasoning, and generative attributes, present opportunities to address PHM's bottlenecks. To this end, based on a systematic analysis of the current challenges and bottlenecks in PHM, as well as the research status and advantages of Large Model, we propose a novel concept and three progressive paradigms of Prognosis and Health Management Large Model (PHM-LM) through the integration of the Large Model with PHM. Subsequently, we provide feasible technical approaches for PHM-LM to bolster PHM's core capabilities within the framework of the three paradigms. Moreover, to address core issues confronting PHM, we discuss a series of technical challenges of PHM-LM throughout the entire process of construction and application. This comprehensive effort offers a holistic PHM-LM technical framework, and provides avenues for new PHM technologies, methodologies, tools, platforms and applications, which also potentially innovates design, research & development, verification and application mode of PHM. And furthermore, a new generation of PHM with AI will also capably be realized, i.e., from custom to generalized, from discriminative to generative, and from theoretical conditions to practical applications.
Explainable AI Security: Exploring Robustness of Graph Neural Networks to Adversarial Attacks
Jun 20, 2024
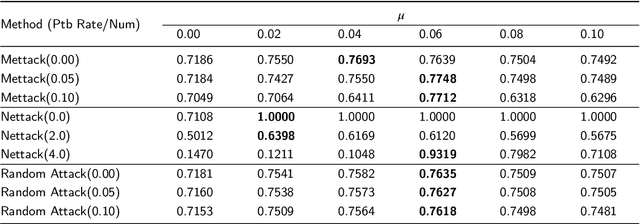
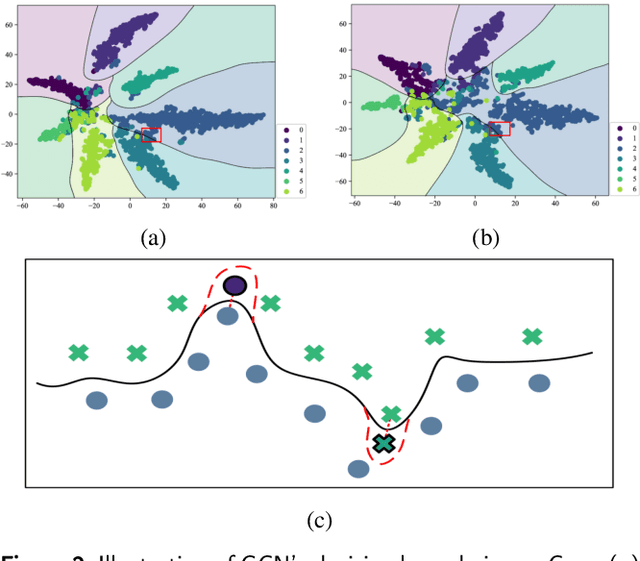
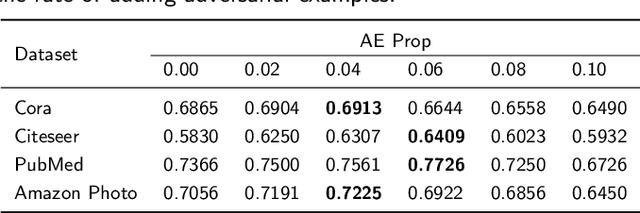
Graph neural networks (GNNs) have achieved tremendous success, but recent studies have shown that GNNs are vulnerable to adversarial attacks, which significantly hinders their use in safety-critical scenarios. Therefore, the design of robust GNNs has attracted increasing attention. However, existing research has mainly been conducted via experimental trial and error, and thus far, there remains a lack of a comprehensive understanding of the vulnerability of GNNs. To address this limitation, we systematically investigate the adversarial robustness of GNNs by considering graph data patterns, model-specific factors, and the transferability of adversarial examples. Through extensive experiments, a set of principled guidelines is obtained for improving the adversarial robustness of GNNs, for example: (i) rather than highly regular graphs, the training graph data with diverse structural patterns is crucial for model robustness, which is consistent with the concept of adversarial training; (ii) the large model capacity of GNNs with sufficient training data has a positive effect on model robustness, and only a small percentage of neurons in GNNs are affected by adversarial attacks; (iii) adversarial transfer is not symmetric and the adversarial examples produced by the small-capacity model have stronger adversarial transferability. This work illuminates the vulnerabilities of GNNs and opens many promising avenues for designing robust GNNs.
GraphMU: Repairing Robustness of Graph Neural Networks via Machine Unlearning
Jun 19, 2024



Graph Neural Networks (GNNs) have demonstrated significant application potential in various fields. However, GNNs are still vulnerable to adversarial attacks. Numerous adversarial defense methods on GNNs are proposed to address the problem of adversarial attacks. However, these methods can only serve as a defense before poisoning, but cannot repair poisoned GNN. Therefore, there is an urgent need for a method to repair poisoned GNN. In this paper, we address this gap by introducing the novel concept of model repair for GNNs. We propose a repair framework, Repairing Robustness of Graph Neural Networks via Machine Unlearning (GraphMU), which aims to fine-tune poisoned GNN to forget adversarial samples without the need for complete retraining. We also introduce a unlearning validation method to ensure that our approach effectively forget specified poisoned data. To evaluate the effectiveness of GraphMU, we explore three fine-tuned subgraph construction scenarios based on the available perturbation information: (i) Known Perturbation Ratios, (ii) Known Complete Knowledge of Perturbations, and (iii) Unknown any Knowledge of Perturbations. Our extensive experiments, conducted across four citation datasets and four adversarial attack scenarios, demonstrate that GraphMU can effectively restore the performance of poisoned GNN.
MOYU: A Theoretical Study on Massive Over-activation Yielded Uplifts in LLMs
Jun 18, 2024

Massive Over-activation Yielded Uplifts(MOYU) is an inherent property of large language models, and dynamic activation(DA) based on the MOYU property is a clever yet under-explored strategy designed to accelerate inference in these models. Existing methods that utilize MOYU often face a significant 'Impossible Trinity': struggling to simultaneously maintain model performance, enhance inference speed, and extend applicability across various architectures. Due to the theoretical ambiguities surrounding MOYU, this paper elucidates the root cause of the MOYU property and outlines the mechanisms behind two primary limitations encountered by current DA methods: 1) history-related activation uncertainty, and 2) semantic-irrelevant activation inertia. Our analysis not only underscores the limitations of current dynamic activation strategies within large-scale LLaMA models but also proposes opportunities for refining the design of future sparsity schemes.
Evolutionary Spiking Neural Networks: A Survey
Jun 18, 2024Spiking neural networks (SNNs) are gaining increasing attention as potential computationally efficient alternatives to traditional artificial neural networks(ANNs). However, the unique information propagation mechanisms and the complexity of SNN neuron models pose challenges for adopting traditional methods developed for ANNs to SNNs. These challenges include both weight learning and architecture design. While surrogate gradient learning has shown some success in addressing the former challenge, the latter remains relatively unexplored. Recently, a novel paradigm utilizing evolutionary computation methods has emerged to tackle these challenges. This approach has resulted in the development of a variety of energy-efficient and high-performance SNNs across a wide range of machine learning benchmarks. In this paper, we present a survey of these works and initiate discussions on potential challenges ahead.
Job-SDF: A Multi-Granularity Dataset for Job Skill Demand Forecasting and Benchmarking
Jun 17, 2024In a rapidly evolving job market, skill demand forecasting is crucial as it enables policymakers and businesses to anticipate and adapt to changes, ensuring that workforce skills align with market needs, thereby enhancing productivity and competitiveness. Additionally, by identifying emerging skill requirements, it directs individuals towards relevant training and education opportunities, promoting continuous self-learning and development. However, the absence of comprehensive datasets presents a significant challenge, impeding research and the advancement of this field. To bridge this gap, we present Job-SDF, a dataset designed to train and benchmark job-skill demand forecasting models. Based on 10.35 million public job advertisements collected from major online recruitment platforms in China between 2021 and 2023, this dataset encompasses monthly recruitment demand for 2,324 types of skills across 521 companies. Our dataset uniquely enables evaluating skill demand forecasting models at various granularities, including occupation, company, and regional levels. We benchmark a range of models on this dataset, evaluating their performance in standard scenarios, in predictions focused on lower value ranges, and in the presence of structural breaks, providing new insights for further research. Our code and dataset are publicly accessible via the https://github.com/Job-SDF/benchmark.
QQQ: Quality Quattuor-Bit Quantization for Large Language Models
Jun 14, 2024



Quantization is a proven effective method for compressing large language models. Although popular techniques like W8A8 and W4A16 effectively maintain model performance, they often fail to concurrently speed up the prefill and decoding stages of inference. W4A8 is a promising strategy to accelerate both of them while usually leads to a significant performance degradation. To address these issues, we present QQQ, a Quality Quattuor-bit Quantization method with 4-bit weights and 8-bit activations. QQQ employs adaptive smoothing and Hessian-based compensation, significantly enhancing the performance of quantized models without extensive training. Furthermore, we meticulously engineer W4A8 GEMM kernels to increase inference speed. Our specialized per-channel W4A8 GEMM and per-group W4A8 GEMM achieve impressive speed increases of 3.67$\times$ and 3.29 $\times$ over FP16 GEMM. Our extensive experiments show that QQQ achieves performance on par with existing state-of-the-art LLM quantization methods while significantly accelerating inference, achieving speed boosts up to 2.24 $\times$, 2.10$\times$, and 1.25$\times$ compared to FP16, W8A8, and W4A16, respectively.
Cinematic Gaussians: Real-Time HDR Radiance Fields with Depth of Field
Jun 11, 2024



Radiance field methods represent the state of the art in reconstructing complex scenes from multi-view photos. However, these reconstructions often suffer from one or both of the following limitations: First, they typically represent scenes in low dynamic range (LDR), which restricts their use to evenly lit environments and hinders immersive viewing experiences. Secondly, their reliance on a pinhole camera model, assuming all scene elements are in focus in the input images, presents practical challenges and complicates refocusing during novel-view synthesis. Addressing these limitations, we present a lightweight method based on 3D Gaussian Splatting that utilizes multi-view LDR images of a scene with varying exposure times, apertures, and focus distances as input to reconstruct a high-dynamic-range (HDR) radiance field. By incorporating analytical convolutions of Gaussians based on a thin-lens camera model as well as a tonemapping module, our reconstructions enable the rendering of HDR content with flexible refocusing capabilities. We demonstrate that our combined treatment of HDR and depth of field facilitates real-time cinematic rendering, outperforming the state of the art.
Statistics-Informed Parameterized Quantum Circuit via Maximum Entropy Principle for Data Science and Finance
Jun 03, 2024



Quantum machine learning has demonstrated significant potential in solving practical problems, particularly in statistics-focused areas such as data science and finance. However, challenges remain in preparing and learning statistical models on a quantum processor due to issues with trainability and interpretability. In this letter, we utilize the maximum entropy principle to design a statistics-informed parameterized quantum circuit (SI-PQC) that efficiently prepares and trains quantum computational statistical models, including arbitrary distributions and their weighted mixtures. The SI-PQC features a static structure with trainable parameters, enabling in-depth optimized circuit compilation, exponential reductions in resource and time consumption, and improved trainability and interpretability for learning quantum states and classical model parameters simultaneously. As an efficient subroutine for preparing and learning in various quantum algorithms, the SI-PQC addresses the input bottleneck and facilitates the injection of prior knowledge.