 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfake Audio Detection Using Self-supervised Fusion Representations
May 05, 2026This paper describes a submission to the Environment-Aware Speech and Sound Deepfake Detection Challenge (ESDD2) 2026, which addresses component-level deepfake detection using the CompSpoofV2 dataset, where speech and environmental sounds may be independently manipulated. To address this challenge, a dual-branch deepfake detection framework is proposed to jointly model speech and environmental contextual representations from input audio. Two pretrained models, XLS-R for speech and BEATs for environmental sound, are used to extract complementary contextual representations. A Matching Head is introduced to model representation differences through statistical normalization and representation interaction, enabling estimation of the original class. In parallel, multi-head cross-attention enables effective information exchange between speech and environmental components. The refined representations are processed with residual connections and layer normalization, and passed to an AASIST classifier to predict speech-based and environment-based spoofing probabilities. The model outputs original, speech, and environment predictions. On the test set, the proposed system achieves an F1-score of 70.20% and an environmental EER of 16.54%, outperforming the baseline system.
Noise-Aware In-Context Learning for Hallucination Mitigation in ALLMs
Apr 10, 2026Auditory large language models (ALLMs) have demonstrated strong general capabilities in audio understanding and reasoning tasks. However, their reliability is still undermined by hallucination issues. Existing hallucination evaluation methods are formulated as binary classification tasks, which are insufficient to characterize the more complex hallucination patterns that arise in generative tasks. Moreover, current hallucination mitigation strategies rely on fine-tuning, resulting in high computational costs. To address the above limitations, we propose a plug-and-play Noise-Aware In-Context Learning (NAICL) method. Specifically, we construct a noise prior library, retrieve noise examples relevant to the input audio, and incorporate them as contextual priors, thereby guiding the model to reduce speculative associations when acoustic evidence is insufficient and to adopt a more conservative generation strategy. In addition, we establish a hallucination benchmark for audio caption tasks including the construction of the Clotho-1K multi-event benchmark dataset, the definition of four types of auditory hallucinations, and the introduction of metrics such as hallucination type distribution to support fine-grained analysis. Experimental results show that all evaluated ALLMs exhibit same hallucination behaviors. Moreover, the proposed NAICL method reduces the overall hallucination rate from 26.53% to 16.98%.
UBMF: Uncertainty-Aware Bayesian Meta-Learning Framework for Fault Diagnosis with Imbalanced Industrial Data
Mar 14, 2025



Fault diagnosis of mechanical equipment involves data collection, feature extraction, and pattern recognition but is often hindered by the imbalanced nature of industrial data, introducing significant uncertainty and reducing diagnostic reliability. To address these challenges, this study proposes the Uncertainty-Aware Bayesian Meta-Learning Framework (UBMF), which integrates four key modules: data perturbation injection for enhancing feature robustness, cross-task self-supervised feature extraction for improving transferability, uncertainty-based sample filtering for robust out-of-domain generalization, and Bayesian meta-knowledge integration for fine-grained classification. Experimental results on ten open-source datasets under various imbalanced conditions, including cross-task, small-sample, and unseen-sample scenarios, demonstrate the superiority of UBMF, achieving an average improvement of 42.22% across ten Any-way 1-5-shot diagnostic tasks. This integrated framework effectively enhances diagnostic accuracy, generalization, and adaptability, providing a reliable solution for complex industrial fault diagnosis.
Pre-Trained Large Language Model Based Remaining Useful Life Transfer Prediction of Bearing
Jan 13, 2025



Accurately predicting the remaining useful life (RUL) of rotating machinery, such as bearings, is essential for ensuring equipment reliability and minimizing unexpected industrial failures. Traditional data-driven deep learning methods face challenges in practical settings due to inconsistent training and testing data distributions and limited generalization for long-term predictions.
LLM-R: A Framework for Domain-Adaptive Maintenance Scheme Generation Combining Hierarchical Agents and RAG
Nov 07, 2024



The increasing use of smart devices has emphasized the critical role of maintenance in production activities. Interactive Electronic Technical Manuals (IETMs) are vital tools that support the maintenance of smart equipment. However, traditional IETMs face challenges such as transitioning from Graphical User Interfaces (GUIs) to natural Language User Interfaces (LUIs) and managing complex logical relationships. Additionally, they must meet the current demands for higher intelligence. This paper proposes a Maintenance Scheme Generation Method based on Large Language Models (LLM-R). The proposed method includes several key innovations: We propose the Low Rank Adaptation-Knowledge Retention (LORA-KR) loss technology to proportionally adjust mixed maintenance data for fine-tuning the LLM. This method prevents knowledge conflicts caused by mixed data, improving the model's adaptability and reasoning ability in specific maintenance domains, Besides, Hierarchical Task-Based Agent and Instruction-level Retrieval-Augmented Generation (RAG) technologies are adopted to optimize the generation steps and mitigate the phenomenon of hallucination caused by the model's Inability to access contextual information. This enhancement improves the model's flexibility and accuracy in handling known or unknown maintenance objects and maintenance scheme scenarios. To validate the proposed method's effectiveness in maintenance tasks, a maintenance scheme dataset was constructed using objects from different fields. The experimental results show that the accuracy of the maintenance schemes generated by the proposed method reached 91.59%, indicating which improvement enhances the intelligence of maintenance schemes and introduces novel technical approaches for equipment maintenance.
An Outline of Prognostics and Health Management Large Model: Concepts, Paradigms, and Challenges
Jul 01, 2024



Prognosis and Health Management (PHM), critical for ensuring task completion by complex systems and preventing unexpected failures, is widely adopted in aerospace, manufacturing, maritime, rail, energy, etc. However, PHM's development is constrained by bottlenecks like generalization, interpretation and verification abilities. Presently, generative artificial intelligence (AI), represented by Large Model, heralds a technological revolution with the potential to fundamentally reshape traditional technological fields and human production methods. Its capabilities, including strong generalization, reasoning, and generative attributes, present opportunities to address PHM's bottlenecks. To this end, based on a systematic analysis of the current challenges and bottlenecks in PHM, as well as the research status and advantages of Large Model, we propose a novel concept and three progressive paradigms of Prognosis and Health Management Large Model (PHM-LM) through the integration of the Large Model with PHM. Subsequently, we provide feasible technical approaches for PHM-LM to bolster PHM's core capabilities within the framework of the three paradigms. Moreover, to address core issues confronting PHM, we discuss a series of technical challenges of PHM-LM throughout the entire process of construction and application. This comprehensive effort offers a holistic PHM-LM technical framework, and provides avenues for new PHM technologies, methodologies, tools, platforms and applications, which also potentially innovates design, research & development, verification and application mode of PHM. And furthermore, a new generation of PHM with AI will also capably be realized, i.e., from custom to generalized, from discriminative to generative, and from theoretical conditions to practical applications.
CityCraft: A Real Crafter for 3D City Generation
Jun 07, 2024



City scene generation has gained significant attention in autonomous driving, smart city development, and traffic simulation. It helps enhance infrastructure planning and monitoring solutions. Existing methods have employed a two-stage process involving city layout generation, typically using Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), or Transformers, followed by neural rendering. These techniques often exhibit limited diversity and noticeable artifacts in the rendered city scenes. The rendered scenes lack variety, resembling the training images, resulting in monotonous styles. Additionally, these methods lack planning capabilities, leading to less realistic generated scenes. In this paper, we introduce CityCraft, an innovative framework designed to enhance both the diversity and quality of urban scene generation. Our approach integrates three key stages: initially, a diffusion transformer (DiT) model is deployed to generate diverse and controllable 2D city layouts. Subsequently, a Large Language Model(LLM) is utilized to strategically make land-use plans within these layouts based on user prompts and language guidelines. Based on the generated layout and city plan, we utilize the asset retrieval module and Blender for precise asset placement and scene construction. Furthermore, we contribute two new datasets to the field: 1)CityCraft-OSM dataset including 2D semantic layouts of urban areas, corresponding satellite images, and detailed annotations. 2) CityCraft-Buildings dataset, featuring thousands of diverse, high-quality 3D building assets. CityCraft achieves state-of-the-art performance in generating realistic 3D cities.
CityGen: Infinite and Controllable 3D City Layout Generation
Dec 03, 2023City layout generation has recently gained significant attention. The goal of this task is to automatically generate the layout of a city scene, including elements such as roads, buildings, vegetation, as well as other urban infrastructures. Previous methods using VAEs or GANs for 3D city layout generation offer limited diversity and constrained interactivity, only allowing users to selectively regenerate parts of the layout, which greatly limits customization. In this paper, we propose CityGen, a novel end-to-end framework for infinite, diverse and controllable 3D city layout generation.First, we propose an outpainting pipeline to extend the local layout to an infinite city layout. Then, we utilize a multi-scale diffusion model to generate diverse and controllable local semantic layout patches. The extensive experiments show that CityGen achieves state-of-the-art (SOTA) performance under FID and KID in generating an infinite and controllable 3D city layout. CityGen demonstrates promising applicability in fields like smart cities, urban planning, and digital simulation.
Extreme Classification in Log Memory using Count-Min Sketch: A Case Study of Amazon Search with 50M Products
Oct 28, 2019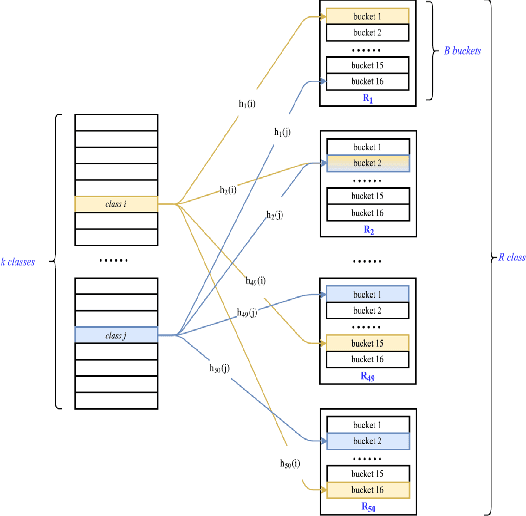

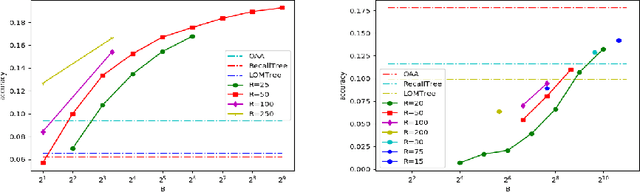
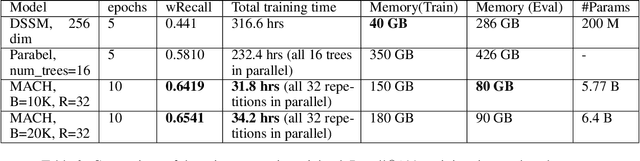
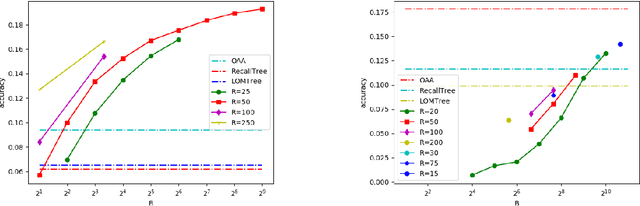
In the last decade, it has been shown that many hard AI tasks, especially in NLP, can be naturally modeled as extreme classification problems leading to improved precision. However, such models are prohibitively expensive to train due to the memory blow-up in the last layer. For example, a reasonable softmax layer for the dataset of interest in this paper can easily reach well beyond 100 billion parameters (>400 GB memory). To alleviate this problem, we present Merged-Average Classifiers via Hashing (MACH), a generic K-classification algorithm where memory provably scales at O(logK) without any strong assumption on the classes. MACH is subtly a count-min sketch structure in disguise, which uses universal hashing to reduce classification with a large number of classes to few embarrassingly parallel and independent classification tasks with a small (constant) number of classes. MACH naturally provides a technique for zero communication model parallelism. We experiment with 6 datasets; some multiclass and some multilabel, and show consistent improvement over respective state-of-the-art baselines. In particular, we train an end-to-end deep classifier on a private product search dataset sampled from Amazon Search Engine with 70 million queries and 49.46 million products. MACH outperforms, by a significant margin,the state-of-the-art extreme classification models deployed on commercial search engines: Parabel and dense embedding models. Our largest model has 6.4 billion parameters and trains in less than 35 hours on a single p3.16x machine. Our training times are 7-10x faster, and our memory footprints are 2-4x smaller than the best baselines. This training time is also significantly lower than the one reported by Google's mixture of experts (MoE) language model on a comparable model size and hardware.
Extreme Classification in Log Memory
Oct 09, 2018
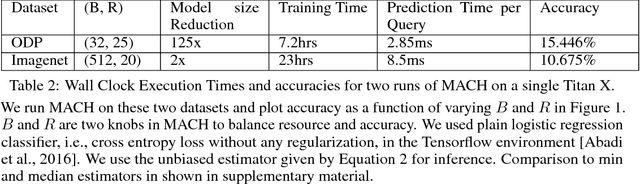
We present Merged-Averaged Classifiers via Hashing (MACH) for K-classification with ultra-large values of K. Compared to traditional one-vs-all classifiers that require O(Kd) memory and inference cost, MACH only need O(d log K) (d is dimensionality )memory while only requiring O(K log K + d log K) operation for inference. MACH is a generic K-classification algorithm, with provably theoretical guarantees, which requires O(log K) memory without any assumption on the relationship between classes. MACH uses universal hashing to reduce classification with a large number of classes to few independent classification tasks with small (constant) number of classes. We provide theoretical quantification of discriminability-memory tradeoff. With MACH we can train ODP dataset with 100,000 classes and 400,000 features on a single Titan X GPU, with the classification accuracy of 19.28%, which is the best-reported accuracy on this dataset. Before this work, the best performing baseline is a one-vs-all classifier that requires 40 billion parameters (160 GB model size) and achieves 9% accuracy. In contrast, MACH can achieve 9% accuracy with 480x reduction in the model size (of mere 0.3GB). With MACH, we also demonstrate complete training of fine-grained imagenet dataset (compressed size 104GB), with 21,000 classes, on a single GPU. To the best of our knowledge, this is the first work to demonstrate complete training of these extreme-class datasets on a single Titan X.