 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGJDNet: Robust Graph Neural Networks via Joint Disentangled Learning Against Adversarial Attacks
Jun 01, 2026Graph Neural Networks (GNNs) are vulnerable to adversarial attacks, which inherently invert connectivity patterns by introducing disassortative edges in assortative graphs and assortative edges in disassortative graphs. This structural inversion creates structure-feature mismatches that disrupt neighborhood aggregation across different graph types. However, we find that existing defenses are limited, as they either treat neighborhoods as monolithic under fixed assortativity assumptions or rely on standard softmax classifiers that fail to account for perturbation-induced representation shifts. To further exploit this observation, we adopt a robustness perspective that jointly disentangles node representations and decision spaces, isolating perturbation effects while enforcing well-separated decision regions. Based on this principle, we propose Graph Joint Disentanglement Network (GJDNet), a unified framework for robust node classification across diverse graph assortativity regimes. GJDNet enhances robustness at both representation and decision levels: it employs feature-driven soft structural disentanglement with skewness-aware neighbor filtering to suppress perturbation-induced structure-feature mismatches, and introduces a Spherical Decision Boundary (SDB) to promote intra-class compactness and inter-class separation in the embedding space, thereby stabilizing decision boundaries under perturbations. Theoretical analysis provides insights into the effectiveness of the proposed disentangled representation and decision mechanisms, while extensive experiments demonstrate that GJDNet consistently achieves strong robustness across graphs with different connectivity regimes.
Disentangled Graph Representation Based on Substructure-Aware Graph Optimal Matching Kernel Convolutional Networks
Apr 23, 2025



Graphs effectively characterize relational data, driving graph representation learning methods that uncover underlying predictive information. As state-of-the-art approaches, Graph Neural Networks (GNNs) enable end-to-end learning for diverse tasks. Recent disentangled graph representation learning enhances interpretability by decoupling independent factors in graph data. However, existing methods often implicitly and coarsely characterize graph structures, limiting structural pattern analysis within the graph. This paper proposes the Graph Optimal Matching Kernel Convolutional Network (GOMKCN) to address this limitation. We view graphs as node-centric subgraphs, where each subgraph acts as a structural factor encoding position-specific information. This transforms graph prediction into structural pattern recognition. Inspired by CNNs, GOMKCN introduces the Graph Optimal Matching Kernel (GOMK) as a convolutional operator, computing similarities between subgraphs and learnable graph filters. Mathematically, GOMK maps subgraphs and filters into a Hilbert space, representing graphs as point sets. Disentangled representations emerge from projecting subgraphs onto task-optimized filters, which adaptively capture relevant structural patterns via gradient descent. Crucially, GOMK incorporates local correspondences in similarity measurement, resolving the trade-off between differentiability and accuracy in graph kernels. Experiments validate that GOMKCN achieves superior accuracy and interpretability in graph pattern mining and prediction. The framework advances the theoretical foundation for disentangled graph representation learning.
Explainable AI Security: Exploring Robustness of Graph Neural Networks to Adversarial Attacks
Jun 20, 2024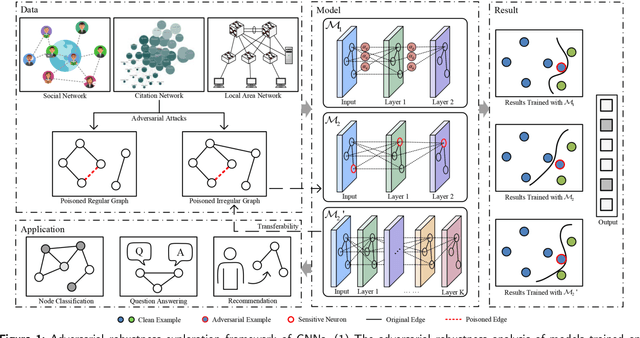
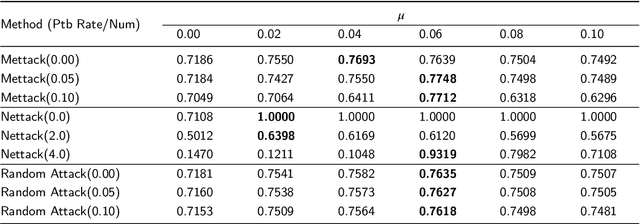
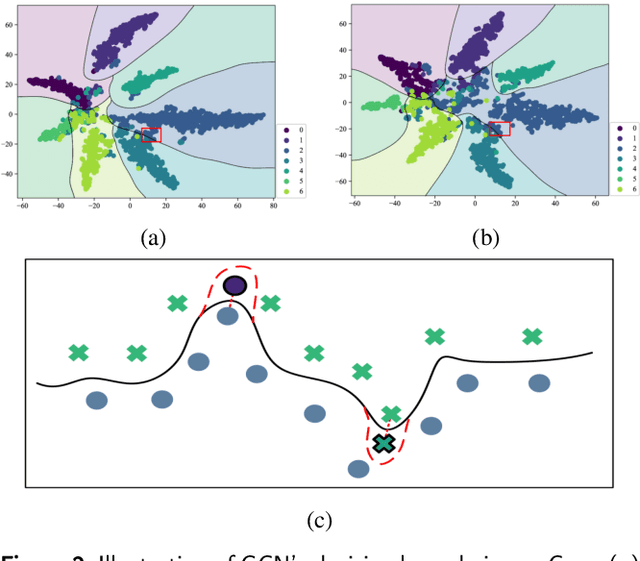
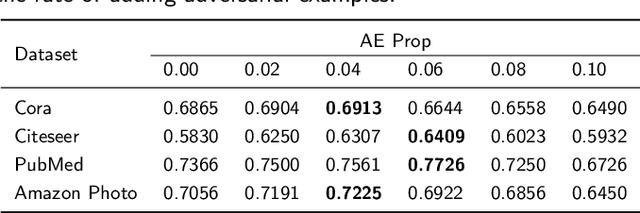
Graph neural networks (GNNs) have achieved tremendous success, but recent studies have shown that GNNs are vulnerable to adversarial attacks, which significantly hinders their use in safety-critical scenarios. Therefore, the design of robust GNNs has attracted increasing attention. However, existing research has mainly been conducted via experimental trial and error, and thus far, there remains a lack of a comprehensive understanding of the vulnerability of GNNs. To address this limitation, we systematically investigate the adversarial robustness of GNNs by considering graph data patterns, model-specific factors, and the transferability of adversarial examples. Through extensive experiments, a set of principled guidelines is obtained for improving the adversarial robustness of GNNs, for example: (i) rather than highly regular graphs, the training graph data with diverse structural patterns is crucial for model robustness, which is consistent with the concept of adversarial training; (ii) the large model capacity of GNNs with sufficient training data has a positive effect on model robustness, and only a small percentage of neurons in GNNs are affected by adversarial attacks; (iii) adversarial transfer is not symmetric and the adversarial examples produced by the small-capacity model have stronger adversarial transferability. This work illuminates the vulnerabilities of GNNs and opens many promising avenues for designing robust GNNs.
GraphMU: Repairing Robustness of Graph Neural Networks via Machine Unlearning
Jun 19, 2024



Graph Neural Networks (GNNs) have demonstrated significant application potential in various fields. However, GNNs are still vulnerable to adversarial attacks. Numerous adversarial defense methods on GNNs are proposed to address the problem of adversarial attacks. However, these methods can only serve as a defense before poisoning, but cannot repair poisoned GNN. Therefore, there is an urgent need for a method to repair poisoned GNN. In this paper, we address this gap by introducing the novel concept of model repair for GNNs. We propose a repair framework, Repairing Robustness of Graph Neural Networks via Machine Unlearning (GraphMU), which aims to fine-tune poisoned GNN to forget adversarial samples without the need for complete retraining. We also introduce a unlearning validation method to ensure that our approach effectively forget specified poisoned data. To evaluate the effectiveness of GraphMU, we explore three fine-tuned subgraph construction scenarios based on the available perturbation information: (i) Known Perturbation Ratios, (ii) Known Complete Knowledge of Perturbations, and (iii) Unknown any Knowledge of Perturbations. Our extensive experiments, conducted across four citation datasets and four adversarial attack scenarios, demonstrate that GraphMU can effectively restore the performance of poisoned GNN.