 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileRAG: Enhancing Mobile Agent with Retrieval-Augmented Generation
Sep 04, 2025Smartphones have become indispensable in people's daily lives, permeating nearly every aspect of modern society. With the continuous advancement of large language models (LLMs), numerous LLM-based mobile agents have emerged. These agents are capable of accurately parsing diverse user queries and automatically assisting users in completing complex or repetitive operations. However, current agents 1) heavily rely on the comprehension ability of LLMs, which can lead to errors caused by misoperations or omitted steps during tasks, 2) lack interaction with the external environment, often terminating tasks when an app cannot fulfill user queries, and 3) lack memory capabilities, requiring each instruction to reconstruct the interface and being unable to learn from and correct previous mistakes. To alleviate the above issues, we propose MobileRAG, a mobile agents framework enhanced by Retrieval-Augmented Generation (RAG), which includes InterRAG, LocalRAG, and MemRAG. It leverages RAG to more quickly and accurately identify user queries and accomplish complex and long-sequence mobile tasks. Additionally, to more comprehensively assess the performance of MobileRAG, we introduce MobileRAG-Eval, a more challenging benchmark characterized by numerous complex, real-world mobile tasks that require external knowledge assistance. Extensive experimental results on MobileRAG-Eval demonstrate that MobileRAG can easily handle real-world mobile tasks, achieving 10.3\% improvement over state-of-the-art methods with fewer operational steps. Our code is publicly available at: https://github.com/liuxiaojieOutOfWorld/MobileRAG_arxiv
Addressing Graph Anomaly Detection via Causal Edge Separation and Spectrum
Aug 20, 2025


In the real world, anomalous entities often add more legitimate connections while hiding direct links with other anomalous entities, leading to heterophilic structures in anomalous networks that most GNN-based techniques fail to address. Several works have been proposed to tackle this issue in the spatial domain. However, these methods overlook the complex relationships between node structure encoding, node features, and their contextual environment and rely on principled guidance, research on solving spectral domain heterophilic problems remains limited. This study analyzes the spectral distribution of nodes with different heterophilic degrees and discovers that the heterophily of anomalous nodes causes the spectral energy to shift from low to high frequencies. To address the above challenges, we propose a spectral neural network CES2-GAD based on causal edge separation for anomaly detection on heterophilic graphs. Firstly, CES2-GAD will separate the original graph into homophilic and heterophilic edges using causal interventions. Subsequently, various hybrid-spectrum filters are used to capture signals from the segmented graphs. Finally, representations from multiple signals are concatenated and input into a classifier to predict anomalies. Extensive experiments with real-world datasets have proven the effectiveness of the method we proposed.
Agentic Graph Neural Networks for Wireless Communications and Networking Towards Edge General Intelligence: A Survey
Aug 12, 2025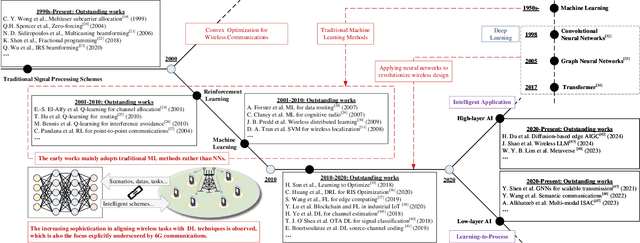
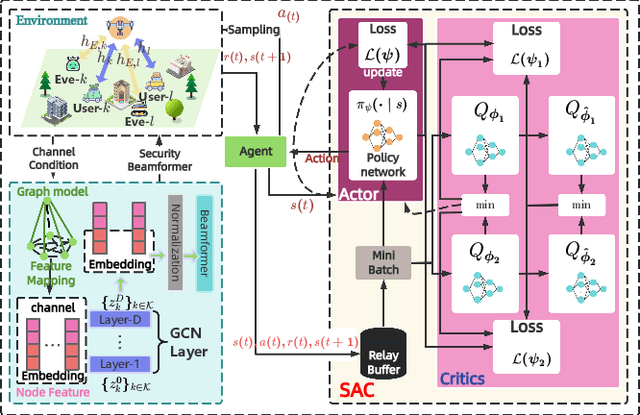
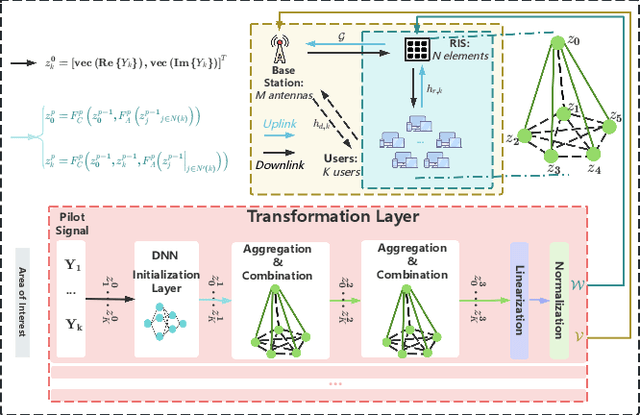
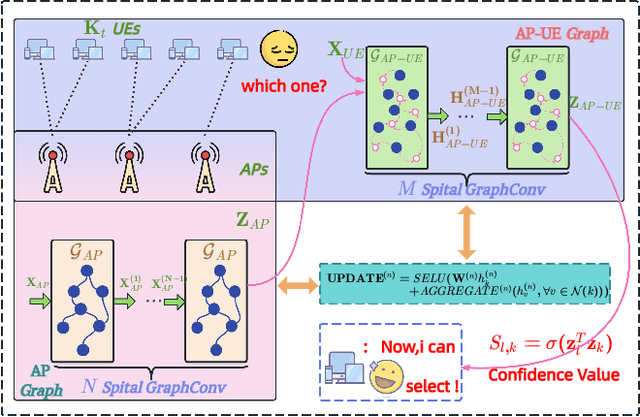
The rapid advancement of communication technologies has driven the evolution of communication networks towards both high-dimensional resource utilization and multifunctional integration. This evolving complexity poses significant challenges in designing communication networks to satisfy the growing quality-of-service and time sensitivity of mobile applications in dynamic environments. Graph neural networks (GNNs) have emerged as fundamental deep learning (DL) models for complex communication networks. GNNs not only augment the extraction of features over network topologies but also enhance scalability and facilitate distributed computation. However, most existing GNNs follow a traditional passive learning framework, which may fail to meet the needs of increasingly diverse wireless systems. This survey proposes the employment of agentic artificial intelligence (AI) to organize and integrate GNNs, enabling scenario- and task-aware implementation towards edge general intelligence. To comprehend the full capability of GNNs, we holistically review recent applications of GNNs in wireless communications and networking. Specifically, we focus on the alignment between graph representations and network topologies, and between neural architectures and wireless tasks. We first provide an overview of GNNs based on prominent neural architectures, followed by the concept of agentic GNNs. Then, we summarize and compare GNN applications for conventional systems and emerging technologies, including physical, MAC, and network layer designs, integrated sensing and communication (ISAC), reconfigurable intelligent surface (RIS) and cell-free network architecture. We further propose a large language model (LLM) framework as an intelligent question-answering agent, leveraging this survey as a local knowledge base to enable GNN-related responses tailored to wireless communication research.
MOSEv2: A More Challenging Dataset for Video Object Segmentation in Complex Scenes
Aug 07, 2025Video object segmentation (VOS) aims to segment specified target objects throughout a video. Although state-of-the-art methods have achieved impressive performance (e.g., 90+% J&F) on existing benchmarks such as DAVIS and YouTube-VOS, these datasets primarily contain salient, dominant, and isolated objects, limiting their generalization to real-world scenarios. To advance VOS toward more realistic environments, coMplex video Object SEgmentation (MOSEv1) was introduced to facilitate VOS research in complex scenes. Building on the strengths and limitations of MOSEv1, we present MOSEv2, a significantly more challenging dataset designed to further advance VOS methods under real-world conditions. MOSEv2 consists of 5,024 videos and over 701,976 high-quality masks for 10,074 objects across 200 categories. Compared to its predecessor, MOSEv2 introduces significantly greater scene complexity, including more frequent object disappearance and reappearance, severe occlusions and crowding, smaller objects, as well as a range of new challenges such as adverse weather (e.g., rain, snow, fog), low-light scenes (e.g., nighttime, underwater), multi-shot sequences, camouflaged objects, non-physical targets (e.g., shadows, reflections), scenarios requiring external knowledge, etc. We benchmark 20 representative VOS methods under 5 different settings and observe consistent performance drops. For example, SAM2 drops from 76.4% on MOSEv1 to only 50.9% on MOSEv2. We further evaluate 9 video object tracking methods and find similar declines, demonstrating that MOSEv2 presents challenges across tasks. These results highlight that despite high accuracy on existing datasets, current VOS methods still struggle under real-world complexities. MOSEv2 is publicly available at https://MOSE.video.
Multimodal Referring Segmentation: A Survey
Aug 01, 2025Multimodal referring segmentation aims to segment target objects in visual scenes, such as images, videos, and 3D scenes, based on referring expressions in text or audio format. This task plays a crucial role in practical applications requiring accurate object perception based on user instructions. Over the past decade, it has gained significant attention in the multimodal community, driven by advances in convolutional neural networks, transformers, and large language models, all of which have substantially improved multimodal perception capabilities. This paper provides a comprehensive survey of multimodal referring segmentation. We begin by introducing this field's background, including problem definitions and commonly used datasets. Next, we summarize a unified meta architecture for referring segmentation and review representative methods across three primary visual scenes, including images, videos, and 3D scenes. We further discuss Generalized Referring Expression (GREx) methods to address the challenges of real-world complexity, along with related tasks and practical applications. Extensive performance comparisons on standard benchmarks are also provided. We continually track related works at https://github.com/henghuiding/Awesome-Multimodal-Referring-Segmentation.
Bridging the Gap in Missing Modalities: Leveraging Knowledge Distillation and Style Matching for Brain Tumor Segmentation
Jul 30, 2025Accurate and reliable brain tumor segmentation, particularly when dealing with missing modalities, remains a critical challenge in medical image analysis. Previous studies have not fully resolved the challenges of tumor boundary segmentation insensitivity and feature transfer in the absence of key imaging modalities. In this study, we introduce MST-KDNet, aimed at addressing these critical issues. Our model features Multi-Scale Transformer Knowledge Distillation to effectively capture attention weights at various resolutions, Dual-Mode Logit Distillation to improve the transfer of knowledge, and a Global Style Matching Module that integrates feature matching with adversarial learning. Comprehensive experiments conducted on the BraTS and FeTS 2024 datasets demonstrate that MST-KDNet surpasses current leading methods in both Dice and HD95 scores, particularly in conditions with substantial modality loss. Our approach shows exceptional robustness and generalization potential, making it a promising candidate for real-world clinical applications. Our source code is available at https://github.com/Quanato607/MST-KDNet.
* 11 pages, 2 figures
VBCD: A Voxel-Based Framework for Personalized Dental Crown Design
Jul 23, 2025



The design of restorative dental crowns from intraoral scans is labor-intensive for dental technicians. To address this challenge, we propose a novel voxel-based framework for automated dental crown design (VBCD). The VBCD framework generates an initial coarse dental crown from voxelized intraoral scans, followed by a fine-grained refiner incorporating distance-aware supervision to improve accuracy and quality. During the training stage, we employ the Curvature and Margin line Penalty Loss (CMPL) to enhance the alignment of the generated crown with the margin line. Additionally, a positional prompt based on the FDI tooth numbering system is introduced to further improve the accuracy of the generated dental crowns. Evaluation on a large-scale dataset of intraoral scans demonstrated that our approach outperforms existing methods, providing a robust solution for personalized dental crown design.
MEDTalk: Multimodal Controlled 3D Facial Animation with Dynamic Emotions by Disentangled Embedding
Jul 08, 2025



Audio-driven emotional 3D facial animation aims to generate synchronized lip movements and vivid facial expressions. However, most existing approaches focus on static and predefined emotion labels, limiting their diversity and naturalness. To address these challenges, we propose MEDTalk, a novel framework for fine-grained and dynamic emotional talking head generation. Our approach first disentangles content and emotion embedding spaces from motion sequences using a carefully designed cross-reconstruction process, enabling independent control over lip movements and facial expressions. Beyond conventional audio-driven lip synchronization, we integrate audio and speech text, predicting frame-wise intensity variations and dynamically adjusting static emotion features to generate realistic emotional expressions. Furthermore, to enhance control and personalization, we incorporate multimodal inputs-including text descriptions and reference expression images-to guide the generation of user-specified facial expressions. With MetaHuman as the priority, our generated results can be conveniently integrated into the industrial production pipeline.
De-AntiFake: Rethinking the Protective Perturbations Against Voice Cloning Attacks
Jul 03, 2025The rapid advancement of speech generation models has heightened privacy and security concerns related to voice cloning (VC). Recent studies have investigated disrupting unauthorized voice cloning by introducing adversarial perturbations. However, determined attackers can mitigate these protective perturbations and successfully execute VC. In this study, we conduct the first systematic evaluation of these protective perturbations against VC under realistic threat models that include perturbation purification. Our findings reveal that while existing purification methods can neutralize a considerable portion of the protective perturbations, they still lead to distortions in the feature space of VC models, which degrades the performance of VC. From this perspective, we propose a novel two-stage purification method: (1) Purify the perturbed speech; (2) Refine it using phoneme guidance to align it with the clean speech distribution. Experimental results demonstrate that our method outperforms state-of-the-art purification methods in disrupting VC defenses. Our study reveals the limitations of adversarial perturbation-based VC defenses and underscores the urgent need for more robust solutions to mitigate the security and privacy risks posed by VC. The code and audio samples are available at https://de-antifake.github.io.
LASFNet: A Lightweight Attention-Guided Self-Modulation Feature Fusion Network for Multimodal Object Detection
Jun 26, 2025Effective deep feature extraction via feature-level fusion is crucial for multimodal object detection. However, previous studies often involve complex training processes that integrate modality-specific features by stacking multiple feature-level fusion units, leading to significant computational overhead. To address this issue, we propose a new fusion detection baseline that uses a single feature-level fusion unit to enable high-performance detection, thereby simplifying the training process. Based on this approach, we propose a lightweight attention-guided self-modulation feature fusion network (LASFNet), which introduces a novel attention-guided self-modulation feature fusion (ASFF) module that adaptively adjusts the responses of fusion features at both global and local levels based on attention information from different modalities, thereby promoting comprehensive and enriched feature generation. Additionally, a lightweight feature attention transformation module (FATM) is designed at the neck of LASFNet to enhance the focus on fused features and minimize information loss. Extensive experiments on three representative datasets demonstrate that, compared to state-of-the-art methods, our approach achieves a favorable efficiency-accuracy trade-off, reducing the number of parameters and computational cost by as much as 90% and 85%, respectively, while improving detection accuracy (mAP) by 1%-3%. The code will be open-sourced at https://github.com/leileilei2000/LASFNet.