 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Representation-based Reinforcement Learning
Dec 17, 2025In real-world applications with large state and action spaces, reinforcement learning (RL) typically employs function approximations to represent core components like the policies, value functions, and dynamics models. Although powerful approximations such as neural networks offer great expressiveness, they often present theoretical ambiguities, suffer from optimization instability and exploration difficulty, and incur substantial computational costs in practice. In this paper, we introduce the perspective of spectral representations as a solution to address these difficulties in RL. Stemming from the spectral decomposition of the transition operator, this framework yields an effective abstraction of the system dynamics for subsequent policy optimization while also providing a clear theoretical characterization. We reveal how to construct spectral representations for transition operators that possess latent variable structures or energy-based structures, which implies different learning methods to extract spectral representations from data. Notably, each of these learning methods realizes an effective RL algorithm under this framework. We also provably extend this spectral view to partially observable MDPs. Finally, we validate these algorithms on over 20 challenging tasks from the DeepMind Control Suite, where they achieve performances comparable or superior to current state-of-the-art model-free and model-based baselines.
MLE-Smith: Scaling MLE Tasks with Automated Multi-Agent Pipeline
Oct 08, 2025While Language Models (LMs) have made significant progress in automating machine learning engineering (MLE), the acquisition of high-quality MLE training data is significantly constrained. Current MLE benchmarks suffer from low scalability and limited applicability because they rely on static, manually curated tasks, demanding extensive time and manual effort to produce. We introduce MLE-Smith, a fully automated multi-agent pipeline, to transform raw datasets into competition-style MLE challenges through an efficient generate-verify-execute paradigm for scaling MLE tasks with verifiable quality, real-world usability, and rich diversity. The proposed multi-agent pipeline in MLE-Smith drives structured task design and standardized refactoring, coupled with a hybrid verification mechanism that enforces strict structural rules and high-level semantic soundness. It further validates empirical solvability and real-world fidelity through interactive execution. We apply MLE-Smith to 224 of real-world datasets and generate 606 tasks spanning multiple categories, objectives, and modalities, demonstrating that MLE-Smith can work effectively across a wide range of real-world datasets. Evaluation on the generated tasks shows that the performance of eight mainstream and cutting-edge LLMs on MLE-Smith tasks is strongly correlated with their performance on carefully human-designed tasks, highlighting the effectiveness of the MLE-Smith to scaling up MLE tasks, while maintaining task quality.
DHAGrasp: Synthesizing Affordance-Aware Dual-Hand Grasps with Text Instructions
Sep 26, 2025Learning to generate dual-hand grasps that respect object semantics is essential for robust hand-object interaction but remains largely underexplored due to dataset scarcity. Existing grasp datasets predominantly focus on single-hand interactions and contain only limited semantic part annotations. To address these challenges, we introduce a pipeline, SymOpt, that constructs a large-scale dual-hand grasp dataset by leveraging existing single-hand datasets and exploiting object and hand symmetries. Building on this, we propose a text-guided dual-hand grasp generator, DHAGrasp, that synthesizes Dual-Hand Affordance-aware Grasps for unseen objects. Our approach incorporates a novel dual-hand affordance representation and follows a two-stage design, which enables effective learning from a small set of segmented training objects while scaling to a much larger pool of unsegmented data. Extensive experiments demonstrate that our method produces diverse and semantically consistent grasps, outperforming strong baselines in both grasp quality and generalization to unseen objects. The project page is at https://quanzhou-li.github.io/DHAGrasp/.
Reversible GNS for Dissipative Fluids with Consistent Bidirectional Dynamics
Sep 26, 2025



Simulating physically plausible trajectories toward user-defined goals is a fundamental yet challenging task in fluid dynamics. While particle-based simulators can efficiently reproduce forward dynamics, inverse inference remains difficult, especially in dissipative systems where dynamics are irreversible and optimization-based solvers are slow, unstable, and often fail to converge. In this work, we introduce the Reversible Graph Network Simulator (R-GNS), a unified framework that enforces bidirectional consistency within a single graph architecture. Unlike prior neural simulators that approximate inverse dynamics by fitting backward data, R-GNS does not attempt to reverse the underlying physics. Instead, we propose a mathematically invertible design based on residual reversible message passing with shared parameters, coupling forward dynamics with inverse inference to deliver accurate predictions and efficient recovery of plausible initial states. Experiments on three dissipative benchmarks (Water-3D, WaterRamps, and WaterDrop) show that R-GNS achieves higher accuracy and consistency with only one quarter of the parameters, and performs inverse inference more than 100 times faster than optimization-based baselines. For forward simulation, R-GNS matches the speed of strong GNS baselines, while in goal-conditioned tasks it eliminates iterative optimization and achieves orders-of-magnitude speedups. On goal-conditioned tasks, R-GNS further demonstrates its ability to complex target shapes (e.g., characters "L" and "N") through vivid, physically consistent trajectories. To our knowledge, this is the first reversible framework that unifies forward and inverse simulation for dissipative fluid systems.
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025
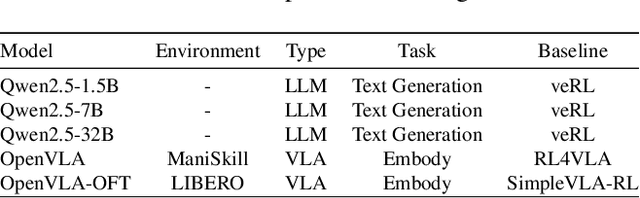

Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
Offline Imitation Learning upon Arbitrary Demonstrations by Pre-Training Dynamics Representations
Aug 20, 2025Limited data has become a major bottleneck in scaling up offline imitation learning (IL). In this paper, we propose enhancing IL performance under limited expert data by introducing a pre-training stage that learns dynamics representations, derived from factorizations of the transition dynamics. We first theoretically justify that the optimal decision variable of offline IL lies in the representation space, significantly reducing the parameters to learn in the downstream IL. Moreover, the dynamics representations can be learned from arbitrary data collected with the same dynamics, allowing the reuse of massive non-expert data and mitigating the limited data issues. We present a tractable loss function inspired by noise contrastive estimation to learn the dynamics representations at the pre-training stage. Experiments on MuJoCo demonstrate that our proposed algorithm can mimic expert policies with as few as a single trajectory. Experiments on real quadrupeds show that we can leverage pre-trained dynamics representations from simulator data to learn to walk from a few real-world demonstrations.
MeshCoder: LLM-Powered Structured Mesh Code Generation from Point Clouds
Aug 20, 2025Reconstructing 3D objects into editable programs is pivotal for applications like reverse engineering and shape editing. However, existing methods often rely on limited domain-specific languages (DSLs) and small-scale datasets, restricting their ability to model complex geometries and structures. To address these challenges, we introduce MeshCoder, a novel framework that reconstructs complex 3D objects from point clouds into editable Blender Python scripts. We develop a comprehensive set of expressive Blender Python APIs capable of synthesizing intricate geometries. Leveraging these APIs, we construct a large-scale paired object-code dataset, where the code for each object is decomposed into distinct semantic parts. Subsequently, we train a multimodal large language model (LLM) that translates 3D point cloud into executable Blender Python scripts. Our approach not only achieves superior performance in shape-to-code reconstruction tasks but also facilitates intuitive geometric and topological editing through convenient code modifications. Furthermore, our code-based representation enhances the reasoning capabilities of LLMs in 3D shape understanding tasks. Together, these contributions establish MeshCoder as a powerful and flexible solution for programmatic 3D shape reconstruction and understanding.
STream3R: Scalable Sequential 3D Reconstruction with Causal Transformer
Aug 14, 2025We present STream3R, a novel approach to 3D reconstruction that reformulates pointmap prediction as a decoder-only Transformer problem. Existing state-of-the-art methods for multi-view reconstruction either depend on expensive global optimization or rely on simplistic memory mechanisms that scale poorly with sequence length. In contrast, STream3R introduces an streaming framework that processes image sequences efficiently using causal attention, inspired by advances in modern language modeling. By learning geometric priors from large-scale 3D datasets, STream3R generalizes well to diverse and challenging scenarios, including dynamic scenes where traditional methods often fail. Extensive experiments show that our method consistently outperforms prior work across both static and dynamic scene benchmarks. Moreover, STream3R is inherently compatible with LLM-style training infrastructure, enabling efficient large-scale pretraining and fine-tuning for various downstream 3D tasks. Our results underscore the potential of causal Transformer models for online 3D perception, paving the way for real-time 3D understanding in streaming environments. More details can be found in our project page: https://nirvanalan.github.io/projects/stream3r.
One-Step Flow Policy Mirror Descent
Jul 31, 2025Diffusion policies have achieved great success in online reinforcement learning (RL) due to their strong expressive capacity. However, the inference of diffusion policy models relies on a slow iterative sampling process, which limits their responsiveness. To overcome this limitation, we propose Flow Policy Mirror Descent (FPMD), an online RL algorithm that enables 1-step sampling during policy inference. Our approach exploits a theoretical connection between the distribution variance and the discretization error of single-step sampling in straight interpolation flow matching models, and requires no extra distillation or consistency training. We present two algorithm variants based on flow policy and MeanFlow policy parametrizations, respectively. Extensive empirical evaluations on MuJoCo benchmarks demonstrate that our algorithms show strong performance comparable to diffusion policy baselines while requiring hundreds of times fewer function evaluations during inference.
Spectral Bellman Method: Unifying Representation and Exploration in RL
Jul 17, 2025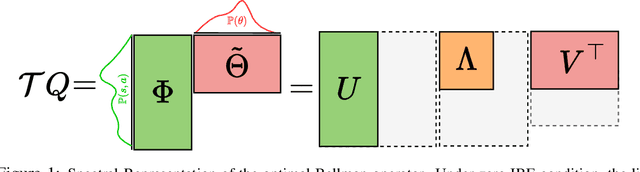
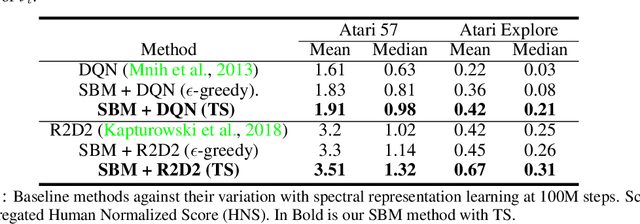

The effect of representation has been demonstrated in reinforcement learning, from both theoretical and empirical successes. However, the existing representation learning mainly induced from model learning aspects, misaligning with our RL tasks. This work introduces Spectral Bellman Representation, a novel framework derived from the Inherent Bellman Error (IBE) condition, which aligns with the fundamental structure of Bellman updates across a space of possible value functions, therefore, directly towards value-based RL. Our key insight is the discovery of a fundamental spectral relationship: under the zero-IBE condition, the transformation of a distribution of value functions by the Bellman operator is intrinsically linked to the feature covariance structure. This spectral connection yields a new, theoretically-grounded objective for learning state-action features that inherently capture this Bellman-aligned covariance. Our method requires a simple modification to existing algorithms. We demonstrate that our learned representations enable structured exploration, by aligning feature covariance with Bellman dynamics, and improve overall performance, particularly in challenging hard-exploration and long-horizon credit assignment tasks. Our framework naturally extends to powerful multi-step Bellman operators, further broadening its impact. Spectral Bellman Representation offers a principled and effective path toward learning more powerful and structurally sound representations for value-based reinforcement learning.