 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting DAgger in the Era of LLM-Agents
May 13, 2026Long-horizon LM agents learn from multi-turn interaction, where a single early mistake can alter the subsequent state distribution and derail the whole trajectory. Existing recipes fall short in complementary ways: supervised fine-tuning provides dense teacher supervision but suffers from covariate shift because it is trained on off-policy teacher trajectories; while reinforcement learning with verifiable rewards avoids this off-policy mismatch by learning from on-policy rollouts but with only sparse outcome feedback. We address this dilemma by revisiting Dataset Aggregation (DAgger) for multi-turn LM agents: the algorithm collects trajectories through a turn-level interpolation of student and teacher policies, and the student is then trained on these trajectories using supervised labels provided by the teacher. By directly interacting with environments, we expose the model to realistic states likely to be encountered during deployment, thereby effectively mitigating covariate shift. Besides, since the student is learned by mimicking the teacher's behavior, it receives rich feedback during learning. To demonstrate DAgger enjoys the benefits of both worlds, we tested the algorithm to train a software-engineering agent with 4B- and 8B-scale student models. On SWE-bench Verified, our DAgger-style training improves over the strongest post-training baseline by +3.9 points at 4B and +3.6 points at 8B. The resulting 4B agent reaches 27.3%, outperforming representative published 8B SWE-agent systems, while the 8B agent achieves 29.8%, surpassing SWE-Gym-32B and coming within 5 points of stronger 32B-scale agents. Together with consistent gains on the held-out SWE-Gym split, these results suggest the effectiveness of DAgger for modern long-horizon LM agents.
Exploration-Driven Optimization for Test-Time Large Language Model Reasoning
May 11, 2026Post-training techniques combined with inference-time scaling significantly enhance the reasoning and alignment capabilities of large language models (LLMs). However, a fundamental tension arises: inference-time methods benefit from diverse sampling from a relatively flattened probability distribution, whereas reinforcement learning (RL)-based post-training inherently sharpens these distributions. To address this, we propose Exploration-Driven Optimization (EDO), which extends reward-biasing style exploration objectives to iterative post-training and integrates them into standard RL objectives, encouraging greater diversity in sampled solutions while facilitating more effective inference-time computation. We incorporate EDO into iterative Direct Preference Optimization (iDPO) and Group Relative Policy Optimization (GRPO), resulting in two variants: ED-iDPO and ED-GRPO. Extensive experiments demonstrate that both ED-iDPO and ED-GRPO exhibit greater solution diversity and improved reasoning abilities, particularly when combined with test-time computation techniques like self-consistency. Across three in-distribution reasoning benchmarks, EDO achieves a 1.0-1.3\% improvement over the strongest baselines, and delivers an additional 1.5\% average gain on five out-of-distribution tasks. Beyond accuracy, EDO preserves model entropy and stabilizes RL training dynamics, highlighting its effectiveness in preventing over-optimization collapse. Taken together, these results establish EDO as a practical framework for balancing exploration and exploitation in LLM reasoning, especially in settings that rely on test-time scaling.
FlowRL: A Taxonomy and Modular Framework for Reinforcement Learning with Diffusion Policies
Mar 29, 2026Thanks to their remarkable flexibility, diffusion models and flow models have emerged as promising candidates for policy representation. However, efficient reinforcement learning (RL) upon these policies remains a challenge due to the lack of explicit log-probabilities for vanilla policy gradient estimators. While numerous attempts have been proposed to address this, the field lacks a unified perspective to reconcile these seemingly disparate methods, thus hampering ongoing development. In this paper, we bridge this gap by introducing a comprehensive taxonomy for RL algorithms with diffusion/flow policies. To support reproducibility and agile prototyping, we introduce a modular, JAX-based open-source codebase that leverages JIT-compilation for high-throughput training. Finally, we provide systematic and standardized benchmarks across Gym-Locomotion, DeepMind Control Suite, and IsaacLab, offering a rigorous side-by-side comparison of diffusion-based methods and guidance for practitioners to choose proper algorithms based on the application. Our work establishes a clear foundation for understanding and algorithm design, a high-efficiency toolkit for future research in the field, and an algorithmic guideline for practitioners in generative models and robotics. Our code is available at https://github.com/typoverflow/flow-rl.
SiMPO: Measure Matching for Online Diffusion Reinforcement Learning
Mar 10, 2026A commonly used family of RL algorithms for diffusion policies conducts softmax reweighting over the behavior policy, which usually induces an over-greedy policy and fails to leverage feedback from negative samples. In this work, we introduce Signed Measure Policy Optimization (SiMPO), a simple and unified framework that generalizes reweighting scheme in diffusion RL with general monotonic functions. SiMPO revisits diffusion RL via a two-stage measure matching lens. First, we construct a virtual target policy by $f$-divergence regularized policy optimization, where we can relax the non-negativity constraint to allow for a signed target measure. Second, we use this signed measure to guide diffusion or flow models through reweighted matching. This formulation offers two key advantages: a) it generalizes to arbitrary monotonically increasing weighting functions; and b) it provides a principled justification and practical guidance for negative reweighting. Furthermore, we provide geometric interpretations to illustrate how negative reweighting actively repels the policy from suboptimal actions. Extensive empirical evaluations demonstrate that SiMPO achieves superior performance by leveraging these flexible weighting schemes, and we provide practical guidelines for selecting reweighting methods tailored to the reward landscape.
Spectral Representation-based Reinforcement Learning
Dec 17, 2025In real-world applications with large state and action spaces, reinforcement learning (RL) typically employs function approximations to represent core components like the policies, value functions, and dynamics models. Although powerful approximations such as neural networks offer great expressiveness, they often present theoretical ambiguities, suffer from optimization instability and exploration difficulty, and incur substantial computational costs in practice. In this paper, we introduce the perspective of spectral representations as a solution to address these difficulties in RL. Stemming from the spectral decomposition of the transition operator, this framework yields an effective abstraction of the system dynamics for subsequent policy optimization while also providing a clear theoretical characterization. We reveal how to construct spectral representations for transition operators that possess latent variable structures or energy-based structures, which implies different learning methods to extract spectral representations from data. Notably, each of these learning methods realizes an effective RL algorithm under this framework. We also provably extend this spectral view to partially observable MDPs. Finally, we validate these algorithms on over 20 challenging tasks from the DeepMind Control Suite, where they achieve performances comparable or superior to current state-of-the-art model-free and model-based baselines.
Reinforced In-Context Black-Box Optimization
Feb 27, 2024



Black-Box Optimization (BBO) has found successful applications in many fields of science and engineering. Recently, there has been a growing interest in meta-learning particular components of BBO algorithms to speed up optimization and get rid of tedious hand-crafted heuristics. As an extension, learning the entire algorithm from data requires the least labor from experts and can provide the most flexibility. In this paper, we propose RIBBO, a method to reinforce-learn a BBO algorithm from offline data in an end-to-end fashion. RIBBO employs expressive sequence models to learn the optimization histories produced by multiple behavior algorithms and tasks, leveraging the in-context learning ability of large models to extract task information and make decisions accordingly. Central to our method is to augment the optimization histories with regret-to-go tokens, which are designed to represent the performance of an algorithm based on cumulative regret of the histories. The integration of regret-to-go tokens enables RIBBO to automatically generate sequences of query points that satisfy the user-desired regret, which is verified by its universally good empirical performance on diverse problems, including BBOB functions, hyper-parameter optimization and robot control problems.
ACT: Empowering Decision Transformer with Dynamic Programming via Advantage Conditioning
Sep 12, 2023Decision Transformer (DT), which employs expressive sequence modeling techniques to perform action generation, has emerged as a promising approach to offline policy optimization. However, DT generates actions conditioned on a desired future return, which is known to bear some weaknesses such as the susceptibility to environmental stochasticity. To overcome DT's weaknesses, we propose to empower DT with dynamic programming. Our method comprises three steps. First, we employ in-sample value iteration to obtain approximated value functions, which involves dynamic programming over the MDP structure. Second, we evaluate action quality in context with estimated advantages. We introduce two types of advantage estimators, IAE and GAE, which are suitable for different tasks. Third, we train an Advantage-Conditioned Transformer (ACT) to generate actions conditioned on the estimated advantages. Finally, during testing, ACT generates actions conditioned on a desired advantage. Our evaluation results validate that, by leveraging the power of dynamic programming, ACT demonstrates effective trajectory stitching and robust action generation in spite of the environmental stochasticity, outperforming baseline methods across various benchmarks. Additionally, we conduct an in-depth analysis of ACT's various design choices through ablation studies.
Model Generation with Provable Coverability for Offline Reinforcement Learning
Jun 08, 2022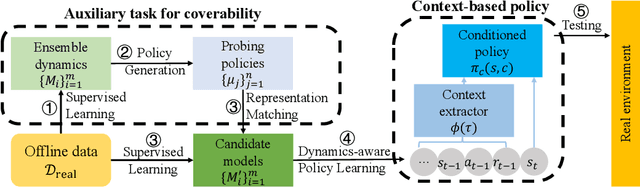
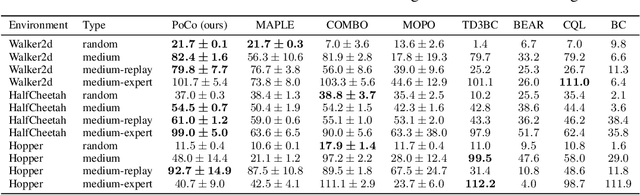
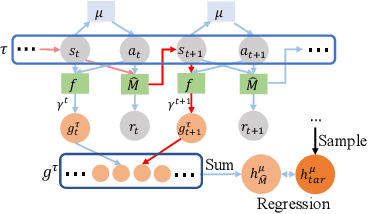
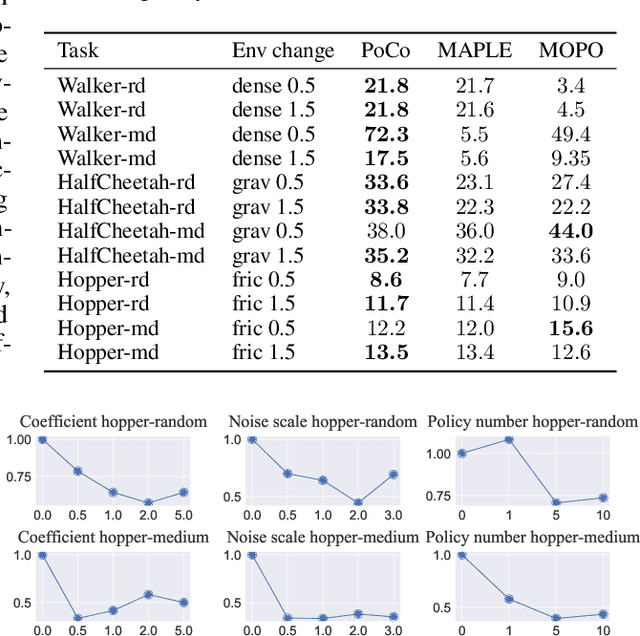
Model-based offline optimization with dynamics-aware policy provides a new perspective for policy learning and out-of-distribution generalization, where the learned policy could adapt to different dynamics enumerated at the training stage. But due to the limitation under the offline setting, the learned model could not mimic real dynamics well enough to support reliable out-of-distribution exploration, which still hinders policy to generalize well. To narrow the gap, previous works roughly ensemble randomly initialized models to better approximate the real dynamics. However, such practice is costly and inefficient, and provides no guarantee on how well the real dynamics could be approximated by the learned models, which we name coverability in this paper. We actively address this issue by generating models with provable ability to cover real dynamics in an efficient and controllable way. To that end, we design a distance metric for dynamic models based on the occupancy of policies under the dynamics, and propose an algorithm to generate models optimizing their coverage for the real dynamics. We give a theoretical analysis on the model generation process and proves that our algorithm could provide enhanced coverability. As a downstream task, we train a dynamics-aware policy with minor or no conservative penalty, and experiments demonstrate that our algorithm outperforms prior offline methods on existing offline RL benchmarks. We also discover that policies learned by our method have better zero-shot transfer performance, implying their better generalization.