 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistentRFT: Reducing Visual Hallucinations in Flow-based Reinforcement Fine-Tuning
Feb 03, 2026Reinforcement Fine-Tuning (RFT) on flow-based models is crucial for preference alignment. However, they often introduce visual hallucinations like over-optimized details and semantic misalignment. This work preliminarily explores why visual hallucinations arise and how to reduce them. We first investigate RFT methods from a unified perspective, and reveal the core problems stemming from two aspects, exploration and exploitation: (1) limited exploration during stochastic differential equation (SDE) rollouts, leading to an over-emphasis on local details at the expense of global semantics, and (2) trajectory imitation process inherent in policy gradient methods, distorting the model's foundational vector field and its cross-step consistency. Building on this, we propose ConsistentRFT, a general framework to mitigate these hallucinations. Specifically, we design a Dynamic Granularity Rollout (DGR) mechanism to balance exploration between global semantics and local details by dynamically scheduling different noise sources. We then introduce a Consistent Policy Gradient Optimization (CPGO) that preserves the model's consistency by aligning the current policy with a more stable prior. Extensive experiments demonstrate that ConsistentRFT significantly mitigates visual hallucinations, achieving average reductions of 49\% for low-level and 38\% for high-level perceptual hallucinations. Furthermore, ConsistentRFT outperforms other RFT methods on out-of-domain metrics, showing an improvement of 5.1\% (v.s. the baseline's decrease of -0.4\%) over FLUX1.dev. This is \href{https://xiaofeng-tan.github.io/projects/ConsistentRFT}{Project Page}.
Towards Fine-Grained Vision-Language Alignment for Few-Shot Anomaly Detection
Oct 30, 2025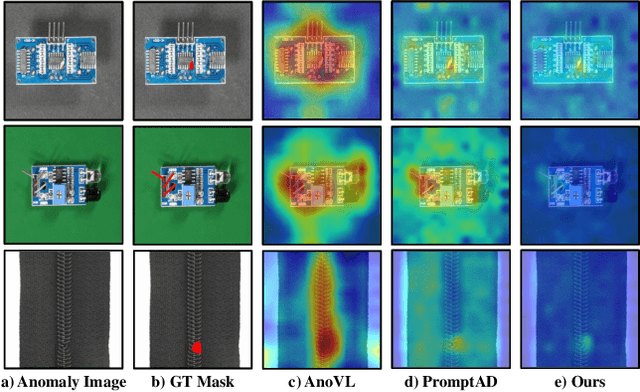
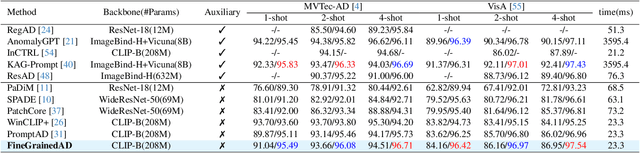
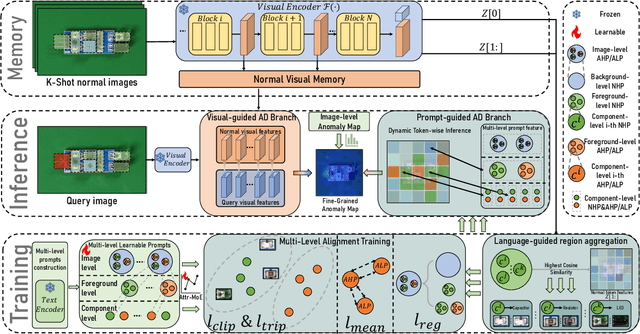
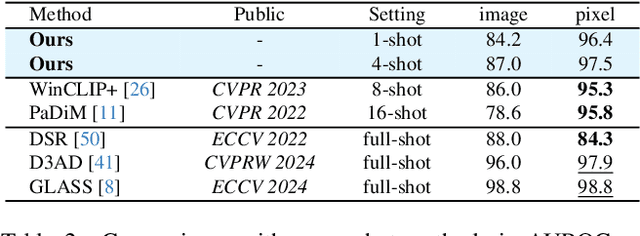
Few-shot anomaly detection (FSAD) methods identify anomalous regions with few known normal samples. Most existing methods rely on the generalization ability of pre-trained vision-language models (VLMs) to recognize potentially anomalous regions through feature similarity between text descriptions and images. However, due to the lack of detailed textual descriptions, these methods can only pre-define image-level descriptions to match each visual patch token to identify potential anomalous regions, which leads to the semantic misalignment between image descriptions and patch-level visual anomalies, achieving sub-optimal localization performance. To address the above issues, we propose the Multi-Level Fine-Grained Semantic Caption (MFSC) to provide multi-level and fine-grained textual descriptions for existing anomaly detection datasets with automatic construction pipeline. Based on the MFSC, we propose a novel framework named FineGrainedAD to improve anomaly localization performance, which consists of two components: Multi-Level Learnable Prompt (MLLP) and Multi-Level Semantic Alignment (MLSA). MLLP introduces fine-grained semantics into multi-level learnable prompts through automatic replacement and concatenation mechanism, while MLSA designs region aggregation strategy and multi-level alignment training to facilitate learnable prompts better align with corresponding visual regions. Experiments demonstrate that the proposed FineGrainedAD achieves superior overall performance in few-shot settings on MVTec-AD and VisA datasets.
Decoupling Classifier for Boosting Few-shot Object Detection and Instance Segmentation
May 20, 2025This paper focus on few-shot object detection~(FSOD) and instance segmentation~(FSIS), which requires a model to quickly adapt to novel classes with a few labeled instances. The existing methods severely suffer from bias classification because of the missing label issue which naturally exists in an instance-level few-shot scenario and is first formally proposed by us. Our analysis suggests that the standard classification head of most FSOD or FSIS models needs to be decoupled to mitigate the bias classification. Therefore, we propose an embarrassingly simple but effective method that decouples the standard classifier into two heads. Then, these two individual heads are capable of independently addressing clear positive samples and noisy negative samples which are caused by the missing label. In this way, the model can effectively learn novel classes while mitigating the effects of noisy negative samples. Without bells and whistles, our model without any additional computation cost and parameters consistently outperforms its baseline and state-of-the-art by a large margin on PASCAL VOC and MS-COCO benchmarks for FSOD and FSIS tasks. The Code is available at https://csgaobb.github.io/Projects/DCFS.
AdaptCLIP: Adapting CLIP for Universal Visual Anomaly Detection
May 15, 2025Universal visual anomaly detection aims to identify anomalies from novel or unseen vision domains without additional fine-tuning, which is critical in open scenarios. Recent studies have demonstrated that pre-trained vision-language models like CLIP exhibit strong generalization with just zero or a few normal images. However, existing methods struggle with designing prompt templates, complex token interactions, or requiring additional fine-tuning, resulting in limited flexibility. In this work, we present a simple yet effective method called AdaptCLIP based on two key insights. First, adaptive visual and textual representations should be learned alternately rather than jointly. Second, comparative learning between query and normal image prompt should incorporate both contextual and aligned residual features, rather than relying solely on residual features. AdaptCLIP treats CLIP models as a foundational service, adding only three simple adapters, visual adapter, textual adapter, and prompt-query adapter, at its input or output ends. AdaptCLIP supports zero-/few-shot generalization across domains and possesses a training-free manner on target domains once trained on a base dataset. AdaptCLIP achieves state-of-the-art performance on 12 anomaly detection benchmarks from industrial and medical domains, significantly outperforming existing competitive methods. We will make the code and model of AdaptCLIP available at https://github.com/gaobb/AdaptCLIP.
MetaUAS: Universal Anomaly Segmentation with One-Prompt Meta-Learning
May 14, 2025Zero- and few-shot visual anomaly segmentation relies on powerful vision-language models that detect unseen anomalies using manually designed textual prompts. However, visual representations are inherently independent of language. In this paper, we explore the potential of a pure visual foundation model as an alternative to widely used vision-language models for universal visual anomaly segmentation. We present a novel paradigm that unifies anomaly segmentation into change segmentation. This paradigm enables us to leverage large-scale synthetic image pairs, featuring object-level and local region changes, derived from existing image datasets, which are independent of target anomaly datasets. We propose a one-prompt Meta-learning framework for Universal Anomaly Segmentation (MetaUAS) that is trained on this synthetic dataset and then generalizes well to segment any novel or unseen visual anomalies in the real world. To handle geometrical variations between prompt and query images, we propose a soft feature alignment module that bridges paired-image change perception and single-image semantic segmentation. This is the first work to achieve universal anomaly segmentation using a pure vision model without relying on special anomaly detection datasets and pre-trained visual-language models. Our method effectively and efficiently segments any anomalies with only one normal image prompt and enjoys training-free without guidance from language. Our MetaUAS significantly outperforms previous zero-shot, few-shot, and even full-shot anomaly segmentation methods. The code and pre-trained models are available at https://github.com/gaobb/MetaUAS.
Few-Shot Anomaly-Driven Generation for Anomaly Classification and Segmentation
May 14, 2025Anomaly detection is a practical and challenging task due to the scarcity of anomaly samples in industrial inspection. Some existing anomaly detection methods address this issue by synthesizing anomalies with noise or external data. However, there is always a large semantic gap between synthetic and real-world anomalies, resulting in weak performance in anomaly detection. To solve the problem, we propose a few-shot Anomaly-driven Generation (AnoGen) method, which guides the diffusion model to generate realistic and diverse anomalies with only a few real anomalies, thereby benefiting training anomaly detection models. Specifically, our work is divided into three stages. In the first stage, we learn the anomaly distribution based on a few given real anomalies and inject the learned knowledge into an embedding. In the second stage, we use the embedding and given bounding boxes to guide the diffusion model to generate realistic and diverse anomalies on specific objects (or textures). In the final stage, we propose a weakly-supervised anomaly detection method to train a more powerful model with generated anomalies. Our method builds upon DRAEM and DesTSeg as the foundation model and conducts experiments on the commonly used industrial anomaly detection dataset, MVTec. The experiments demonstrate that our generated anomalies effectively improve the model performance of both anomaly classification and segmentation tasks simultaneously, \eg, DRAEM and DseTSeg achieved a 5.8\% and 1.5\% improvement in AU-PR metric on segmentation task, respectively. The code and generated anomalous data are available at https://github.com/gaobb/AnoGen.
Learning to Detect Multi-class Anomalies with Just One Normal Image Prompt
May 14, 2025Unsupervised reconstruction networks using self-attention transformers have achieved state-of-the-art performance for multi-class (unified) anomaly detection with a single model. However, these self-attention reconstruction models primarily operate on target features, which may result in perfect reconstruction for both normal and anomaly features due to high consistency with context, leading to failure in detecting anomalies. Additionally, these models often produce inaccurate anomaly segmentation due to performing reconstruction in a low spatial resolution latent space. To enable reconstruction models enjoying high efficiency while enhancing their generalization for unified anomaly detection, we propose a simple yet effective method that reconstructs normal features and restores anomaly features with just One Normal Image Prompt (OneNIP). In contrast to previous work, OneNIP allows for the first time to reconstruct or restore anomalies with just one normal image prompt, effectively boosting unified anomaly detection performance. Furthermore, we propose a supervised refiner that regresses reconstruction errors by using both real normal and synthesized anomalous images, which significantly improves pixel-level anomaly segmentation. OneNIP outperforms previous methods on three industry anomaly detection benchmarks: MVTec, BTAD, and VisA. The code and pre-trained models are available at https://github.com/gaobb/OneNIP.
Real-IAD D3: A Real-World 2D/Pseudo-3D/3D Dataset for Industrial Anomaly Detection
Apr 19, 2025The increasing complexity of industrial anomaly detection (IAD) has positioned multimodal detection methods as a focal area of machine vision research. However, dedicated multimodal datasets specifically tailored for IAD remain limited. Pioneering datasets like MVTec 3D have laid essential groundwork in multimodal IAD by incorporating RGB+3D data, but still face challenges in bridging the gap with real industrial environments due to limitations in scale and resolution. To address these challenges, we introduce Real-IAD D3, a high-precision multimodal dataset that uniquely incorporates an additional pseudo3D modality generated through photometric stereo, alongside high-resolution RGB images and micrometer-level 3D point clouds. Real-IAD D3 features finer defects, diverse anomalies, and greater scale across 20 categories, providing a challenging benchmark for multimodal IAD Additionally, we introduce an effective approach that integrates RGB, point cloud, and pseudo-3D depth information to leverage the complementary strengths of each modality, enhancing detection performance. Our experiments highlight the importance of these modalities in boosting detection robustness and overall IAD performance. The dataset and code are publicly accessible for research purposes at https://realiad4ad.github.io/Real-IAD D3
BoxSeg: Quality-Aware and Peer-Assisted Learning for Box-supervised Instance Segmentation
Apr 07, 2025Box-supervised instance segmentation methods aim to achieve instance segmentation with only box annotations. Recent methods have demonstrated the effectiveness of acquiring high-quality pseudo masks under the teacher-student framework. Building upon this foundation, we propose a BoxSeg framework involving two novel and general modules named the Quality-Aware Module (QAM) and the Peer-assisted Copy-paste (PC). The QAM obtains high-quality pseudo masks and better measures the mask quality to help reduce the effect of noisy masks, by leveraging the quality-aware multi-mask complementation mechanism. The PC imitates Peer-Assisted Learning to further improve the quality of the low-quality masks with the guidance of the obtained high-quality pseudo masks. Theoretical and experimental analyses demonstrate the proposed QAM and PC are effective. Extensive experimental results show the superiority of our BoxSeg over the state-of-the-art methods, and illustrate the QAM and PC can be applied to improve other models.
SoftPatch+: Fully Unsupervised Anomaly Classification and Segmentation
Dec 30, 2024



Although mainstream unsupervised anomaly detection (AD) (including image-level classification and pixel-level segmentation)algorithms perform well in academic datasets, their performance is limited in practical application due to the ideal experimental setting of clean training data. Training with noisy data is an inevitable problem in real-world anomaly detection but is seldom discussed. This paper is the first to consider fully unsupervised industrial anomaly detection (i.e., unsupervised AD with noisy data). To solve this problem, we proposed memory-based unsupervised AD methods, SoftPatch and SoftPatch+, which efficiently denoise the data at the patch level. Noise discriminators are utilized to generate outlier scores for patch-level noise elimination before coreset construction. The scores are then stored in the memory bank to soften the anomaly detection boundary. Compared with existing methods, SoftPatch maintains a strong modeling ability of normal data and alleviates the overconfidence problem in coreset, and SoftPatch+ has more robust performance which is articularly useful in real-world industrial inspection scenarios with high levels of noise (from 10% to 40%). Comprehensive experiments conducted in diverse noise scenarios demonstrate that both SoftPatch and SoftPatch+ outperform the state-of-the-art AD methods on the MVTecAD, ViSA, and BTAD benchmarks. Furthermore, the performance of SoftPatch and SoftPatch+ is comparable to that of the noise-free methods in conventional unsupervised AD setting. The code of the proposed methods can be found at https://github.com/TencentYoutuResearch/AnomalyDetection-SoftPatch.