 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Pre-Training for Visuo-Motor Control: Revisiting a Learning-from-Scratch Baseline
Dec 12, 2022We revisit a simple Learning-from-Scratch baseline for visuo-motor control that uses data augmentation and a shallow ConvNet. We find that this baseline has competitive performance with recent methods that leverage frozen visual representations trained on large-scale vision datasets.
CACTI: A Framework for Scalable Multi-Task Multi-Scene Visual Imitation Learning
Dec 12, 2022Developing robots that are capable of many skills and generalization to unseen scenarios requires progress on two fronts: efficient collection of large and diverse datasets, and training of high-capacity policies on the collected data. While large datasets have propelled progress in other fields like computer vision and natural language processing, collecting data of comparable scale is particularly challenging for physical systems like robotics. In this work, we propose a framework to bridge this gap and better scale up robot learning, under the lens of multi-task, multi-scene robot manipulation in kitchen environments. Our framework, named CACTI, has four stages that separately handle data collection, data augmentation, visual representation learning, and imitation policy training. In the CACTI framework, we highlight the benefit of adapting state-of-the-art models for image generation as part of the augmentation stage, and the significant improvement of training efficiency by using pretrained out-of-domain visual representations at the compression stage. Experimentally, we demonstrate that 1) on a real robot setup, CACTI enables efficient training of a single policy capable of 10 manipulation tasks involving kitchen objects, and robust to varying layouts of distractor objects; 2) in a simulated kitchen environment, CACTI trains a single policy on 18 semantic tasks across up to 50 layout variations per task. The simulation task benchmark and augmented datasets in both real and simulated environments will be released to facilitate future research.
MoDem: Accelerating Visual Model-Based Reinforcement Learning with Demonstrations
Dec 12, 2022



Poor sample efficiency continues to be the primary challenge for deployment of deep Reinforcement Learning (RL) algorithms for real-world applications, and in particular for visuo-motor control. Model-based RL has the potential to be highly sample efficient by concurrently learning a world model and using synthetic rollouts for planning and policy improvement. However, in practice, sample-efficient learning with model-based RL is bottlenecked by the exploration challenge. In this work, we find that leveraging just a handful of demonstrations can dramatically improve the sample-efficiency of model-based RL. Simply appending demonstrations to the interaction dataset, however, does not suffice. We identify key ingredients for leveraging demonstrations in model learning -- policy pretraining, targeted exploration, and oversampling of demonstration data -- which forms the three phases of our model-based RL framework. We empirically study three complex visuo-motor control domains and find that our method is 150%-250% more successful in completing sparse reward tasks compared to prior approaches in the low data regime (100K interaction steps, 5 demonstrations). Code and videos are available at: https://nicklashansen.github.io/modemrl
Real World Offline Reinforcement Learning with Realistic Data Source
Oct 12, 2022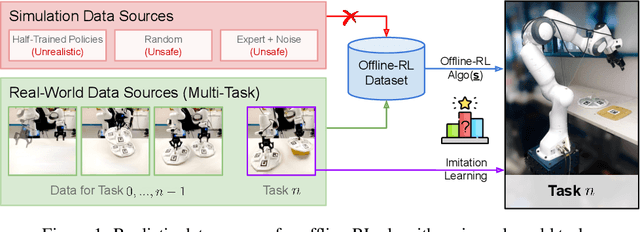

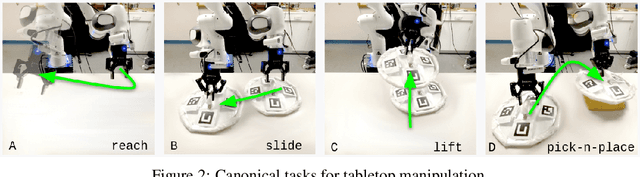
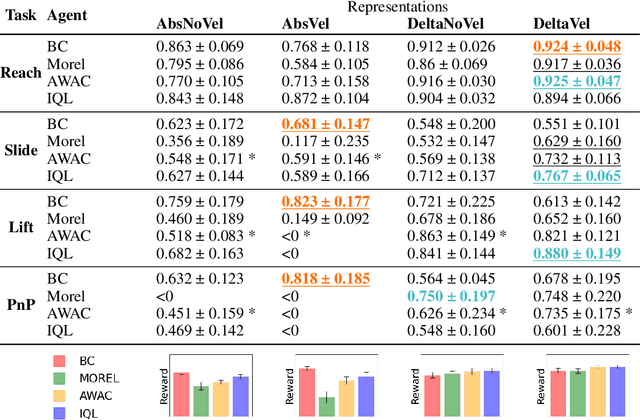
Offline reinforcement learning (ORL) holds great promise for robot learning due to its ability to learn from arbitrary pre-generated experience. However, current ORL benchmarks are almost entirely in simulation and utilize contrived datasets like replay buffers of online RL agents or sub-optimal trajectories, and thus hold limited relevance for real-world robotics. In this work (Real-ORL), we posit that data collected from safe operations of closely related tasks are more practical data sources for real-world robot learning. Under these settings, we perform an extensive (6500+ trajectories collected over 800+ robot hours and 270+ human labor hour) empirical study evaluating generalization and transfer capabilities of representative ORL methods on four real-world tabletop manipulation tasks. Our study finds that ORL and imitation learning prefer different action spaces, and that ORL algorithms can generalize from leveraging offline heterogeneous data sources and outperform imitation learning. We release our dataset and implementations at URL: https://sites.google.com/view/real-orl
Can Foundation Models Perform Zero-Shot Task Specification For Robot Manipulation?
Apr 23, 2022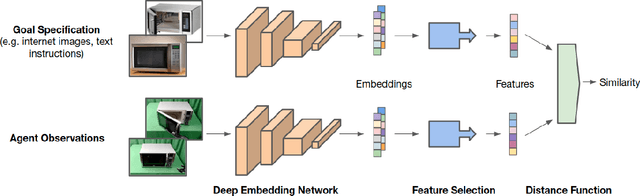
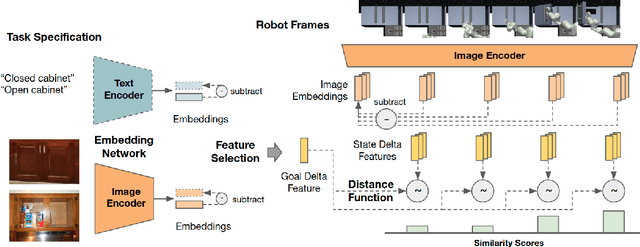
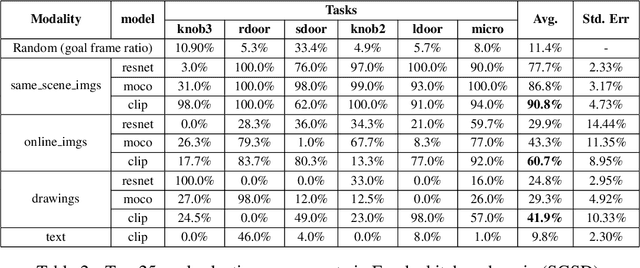

Task specification is at the core of programming autonomous robots. A low-effort modality for task specification is critical for engagement of non-expert end-users and ultimate adoption of personalized robot agents. A widely studied approach to task specification is through goals, using either compact state vectors or goal images from the same robot scene. The former is hard to interpret for non-experts and necessitates detailed state estimation and scene understanding. The latter requires the generation of desired goal image, which often requires a human to complete the task, defeating the purpose of having autonomous robots. In this work, we explore alternate and more general forms of goal specification that are expected to be easier for humans to specify and use such as images obtained from the internet, hand sketches that provide a visual description of the desired task, or simple language descriptions. As a preliminary step towards this, we investigate the capabilities of large scale pre-trained models (foundation models) for zero-shot goal specification, and find promising results in a collection of simulated robot manipulation tasks and real-world datasets.
R3M: A Universal Visual Representation for Robot Manipulation
Mar 23, 2022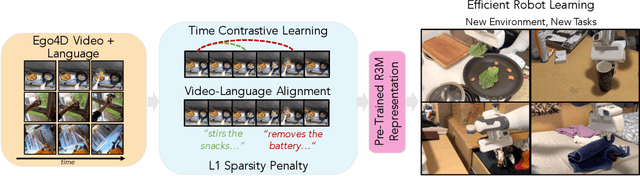
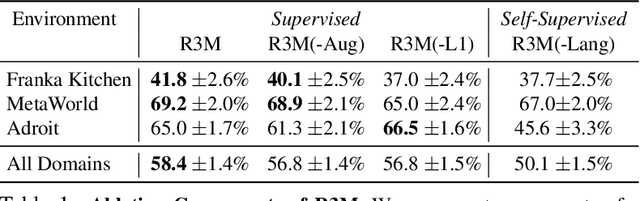
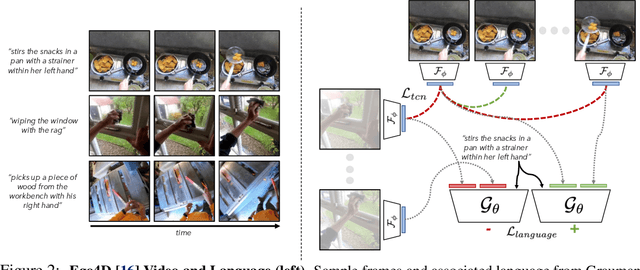
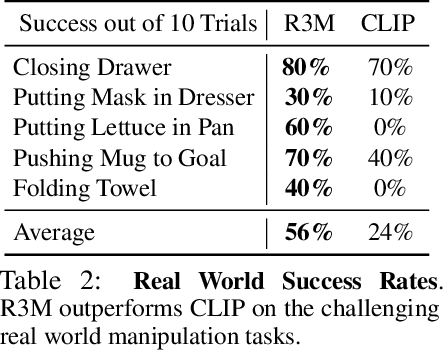
We study how visual representations pre-trained on diverse human video data can enable data-efficient learning of downstream robotic manipulation tasks. Concretely, we pre-train a visual representation using the Ego4D human video dataset using a combination of time-contrastive learning, video-language alignment, and an L1 penalty to encourage sparse and compact representations. The resulting representation, R3M, can be used as a frozen perception module for downstream policy learning. Across a suite of 12 simulated robot manipulation tasks, we find that R3M improves task success by over 20% compared to training from scratch and by over 10% compared to state-of-the-art visual representations like CLIP and MoCo. Furthermore, R3M enables a Franka Emika Panda arm to learn a range of manipulation tasks in a real, cluttered apartment given just 20 demonstrations. Code and pre-trained models are available at https://tinyurl.com/robotr3m.
Policy Architectures for Compositional Generalization in Control
Mar 10, 2022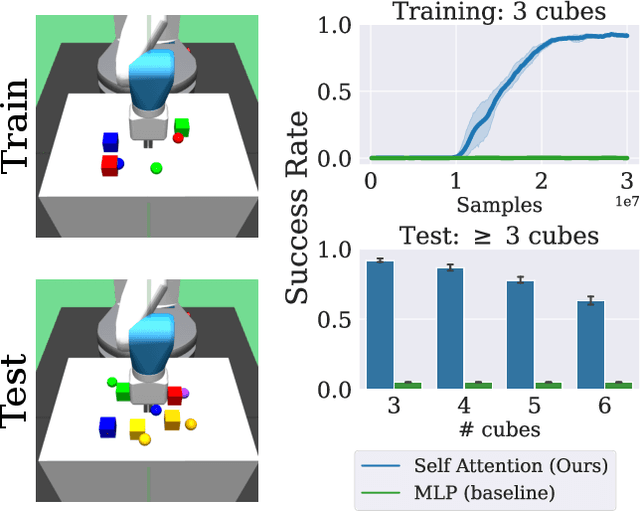
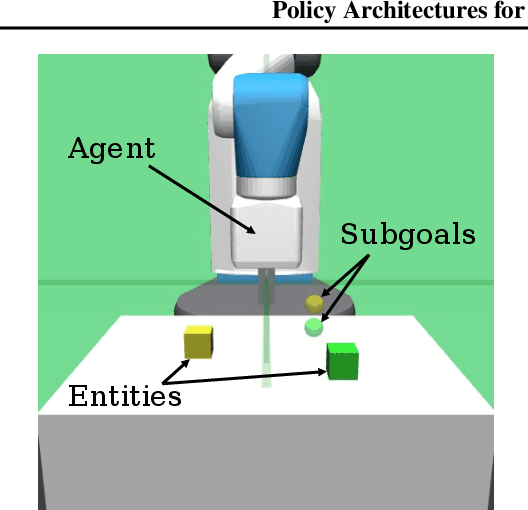
Many tasks in control, robotics, and planning can be specified using desired goal configurations for various entities in the environment. Learning goal-conditioned policies is a natural paradigm to solve such tasks. However, current approaches struggle to learn and generalize as task complexity increases, such as variations in number of environment entities or compositions of goals. In this work, we introduce a framework for modeling entity-based compositional structure in tasks, and create suitable policy designs that can leverage this structure. Our policies, which utilize architectures like Deep Sets and Self Attention, are flexible and can be trained end-to-end without requiring any action primitives. When trained using standard reinforcement and imitation learning methods on a suite of simulated robot manipulation tasks, we find that these architectures achieve significantly higher success rates with less data. We also find these architectures enable broader and compositional generalization, producing policies that extrapolate to different numbers of entities than seen in training, and stitch together (i.e. compose) learned skills in novel ways. Videos of the results can be found at https://sites.google.com/view/comp-gen-rl.
The Unsurprising Effectiveness of Pre-Trained Vision Models for Control
Mar 07, 2022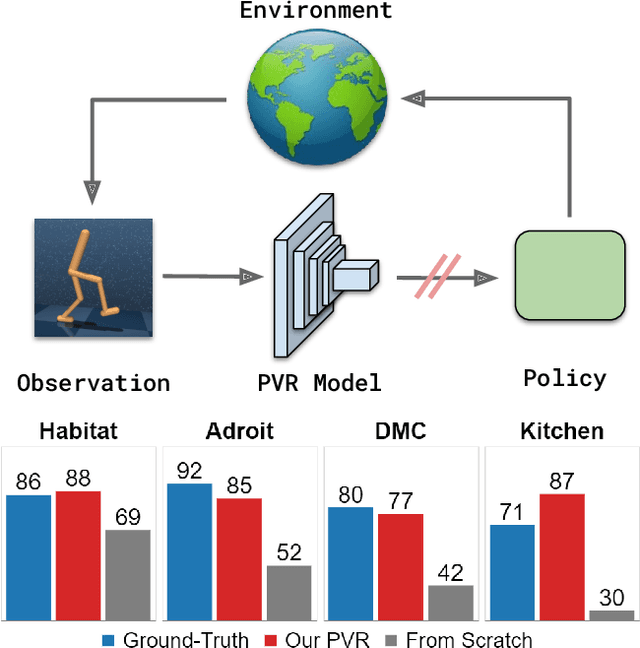



Recent years have seen the emergence of pre-trained representations as a powerful abstraction for AI applications in computer vision, natural language, and speech. However, policy learning for control is still dominated by a tabula-rasa learning paradigm, with visuo-motor policies often trained from scratch using data from deployment environments. In this context, we revisit and study the role of pre-trained visual representations for control, and in particular representations trained on large-scale computer vision datasets. Through extensive empirical evaluation in diverse control domains (Habitat, DeepMind Control, Adroit, Franka Kitchen), we isolate and study the importance of different representation training methods, data augmentations, and feature hierarchies. Overall, we find that pre-trained visual representations can be competitive or even better than ground-truth state representations to train control policies. This is in spite of using only out-of-domain data from standard vision datasets, without any in-domain data from the deployment environments. Additional details and source code is available at https://sites.google.com/view/pvr-control
CIC: Contrastive Intrinsic Control for Unsupervised Skill Discovery
Feb 01, 2022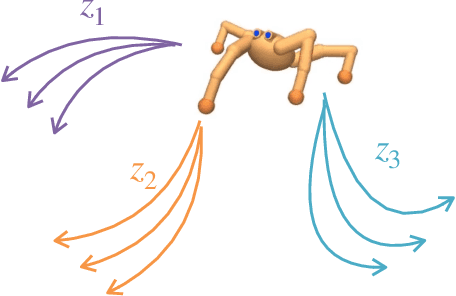
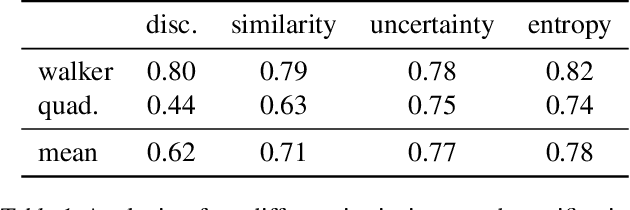

We introduce Contrastive Intrinsic Control (CIC), an algorithm for unsupervised skill discovery that maximizes the mutual information between skills and state transitions. In contrast to most prior approaches, CIC uses a decomposition of the mutual information that explicitly incentivizes diverse behaviors by maximizing state entropy. We derive a novel lower bound estimate for the mutual information which combines a particle estimator for state entropy to generate diverse behaviors and contrastive learning to distill these behaviors into distinct skills. We evaluate our algorithm on the Unsupervised Reinforcement Learning Benchmark, which consists of a long reward-free pre-training phase followed by a short adaptation phase to downstream tasks with extrinsic rewards. We find that CIC substantially improves over prior unsupervised skill discovery methods and outperforms the next leading overall exploration algorithm in terms of downstream task performance.
Visual Adversarial Imitation Learning using Variational Models
Jul 16, 2021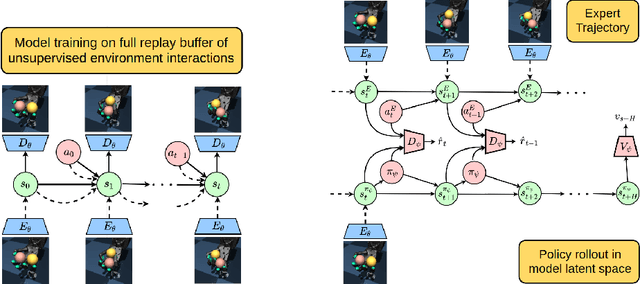
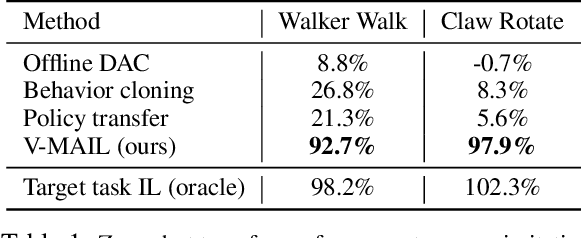


Reward function specification, which requires considerable human effort and iteration, remains a major impediment for learning behaviors through deep reinforcement learning. In contrast, providing visual demonstrations of desired behaviors often presents an easier and more natural way to teach agents. We consider a setting where an agent is provided a fixed dataset of visual demonstrations illustrating how to perform a task, and must learn to solve the task using the provided demonstrations and unsupervised environment interactions. This setting presents a number of challenges including representation learning for visual observations, sample complexity due to high dimensional spaces, and learning instability due to the lack of a fixed reward or learning signal. Towards addressing these challenges, we develop a variational model-based adversarial imitation learning (V-MAIL) algorithm. The model-based approach provides a strong signal for representation learning, enables sample efficiency, and improves the stability of adversarial training by enabling on-policy learning. Through experiments involving several vision-based locomotion and manipulation tasks, we find that V-MAIL learns successful visuomotor policies in a sample-efficient manner, has better stability compared to prior work, and also achieves higher asymptotic performance. We further find that by transferring the learned models, V-MAIL can learn new tasks from visual demonstrations without any additional environment interactions. All results including videos can be found online at \url{https://sites.google.com/view/variational-mail}.