 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Autonomous Wood-Log Grasping with a Forestry Crane: Simulator and Benchmarking
Feb 03, 2025



Forestry machines operated in forest production environments face challenges when performing manipulation tasks, especially regarding the complicated dynamics of underactuated crane systems and the heavy weight of logs to be grasped. This study investigates the feasibility of using reinforcement learning for forestry crane manipulators in grasping and lifting heavy wood logs autonomously. We first build a simulator using Mujoco physics engine to create realistic scenarios, including modeling a forestry crane with 8 degrees of freedom from CAD data and wood logs of different sizes. We further implement a velocity controller for autonomous log grasping with deep reinforcement learning using a curriculum strategy. Utilizing our new simulator, the proposed control strategy exhibits a success rate of 96% when grasping logs of different diameters and under random initial configurations of the forestry crane. In addition, reward functions and reinforcement learning baselines are implemented to provide an open-source benchmark for the community in large-scale manipulation tasks. A video with several demonstrations can be seen at https://www.acin.tuwien.ac.at/en/d18a/
Adaptive Prompt: Unlocking the Power of Visual Prompt Tuning
Jan 31, 2025



Visual Prompt Tuning (VPT) has recently emerged as a powerful method for adapting pre-trained vision models to downstream tasks. By introducing learnable prompt tokens as task-specific instructions, VPT effectively guides pre-trained transformer models with minimal overhead. Despite its empirical success, a comprehensive theoretical understanding of VPT remains an active area of research. Building on recent insights into the connection between mixture of experts and prompt-based approaches, we identify a key limitation in VPT: the restricted functional expressiveness in prompt formulation. To address this limitation, we propose Visual Adaptive Prompt Tuning (VAPT), a new generation of prompts that redefines prompts as adaptive functions of the input. Our theoretical analysis shows that this simple yet intuitive approach achieves optimal sample efficiency. Empirical results on VTAB-1K and FGVC further demonstrate VAPT's effectiveness, with performance gains of 7.34% and 1.04% over fully fine-tuning baselines, respectively. Notably, VAPT also surpasses VPT by a substantial margin while using fewer parameters. These results highlight both the effectiveness and efficiency of our method and pave the way for future research to explore the potential of adaptive prompts.
Online Trajectory Replanner for Dynamically Grasping Irregular Objects
Jan 29, 2025



This paper presents a new trajectory replanner for grasping irregular objects. Unlike conventional grasping tasks where the object's geometry is assumed simple, we aim to achieve a "dynamic grasp" of the irregular objects, which requires continuous adjustment during the grasping process. To effectively handle irregular objects, we propose a trajectory optimization framework that comprises two phases. Firstly, in a specified time limit of 10s, initial offline trajectories are computed for a seamless motion from an initial configuration of the robot to grasp the object and deliver it to a pre-defined target location. Secondly, fast online trajectory optimization is implemented to update robot trajectories in real-time within 100 ms. This helps to mitigate pose estimation errors from the vision system. To account for model inaccuracies, disturbances, and other non-modeled effects, trajectory tracking controllers for both the robot and the gripper are implemented to execute the optimal trajectories from the proposed framework. The intensive experimental results effectively demonstrate the performance of our trajectory planning framework in both simulation and real-world scenarios.
FedEFM: Federated Endovascular Foundation Model with Unseen Data
Jan 28, 2025



In endovascular surgery, the precise identification of catheters and guidewires in X-ray images is essential for reducing intervention risks. However, accurately segmenting catheter and guidewire structures is challenging due to the limited availability of labeled data. Foundation models offer a promising solution by enabling the collection of similar domain data to train models whose weights can be fine-tuned for downstream tasks. Nonetheless, large-scale data collection for training is constrained by the necessity of maintaining patient privacy. This paper proposes a new method to train a foundation model in a decentralized federated learning setting for endovascular intervention. To ensure the feasibility of the training, we tackle the unseen data issue using differentiable Earth Mover's Distance within a knowledge distillation framework. Once trained, our foundation model's weights provide valuable initialization for downstream tasks, thereby enhancing task-specific performance. Intensive experiments show that our approach achieves new state-of-the-art results, contributing to advancements in endovascular intervention and robotic-assisted endovascular surgery, while addressing the critical issue of data sharing in the medical domain.
SplineFormer: An Explainable Transformer-Based Approach for Autonomous Endovascular Navigation
Jan 08, 2025Endovascular navigation is a crucial aspect of minimally invasive procedures, where precise control of curvilinear instruments like guidewires is critical for successful interventions. A key challenge in this task is accurately predicting the evolving shape of the guidewire as it navigates through the vasculature, which presents complex deformations due to interactions with the vessel walls. Traditional segmentation methods often fail to provide accurate real-time shape predictions, limiting their effectiveness in highly dynamic environments. To address this, we propose SplineFormer, a new transformer-based architecture, designed specifically to predict the continuous, smooth shape of the guidewire in an explainable way. By leveraging the transformer's ability, our network effectively captures the intricate bending and twisting of the guidewire, representing it as a spline for greater accuracy and smoothness. We integrate our SplineFormer into an end-to-end robot navigation system by leveraging the condensed information. The experimental results demonstrate that our SplineFormer is able to perform endovascular navigation autonomously and achieves a 50% success rate when cannulating the brachiocephalic artery on the real robot.
Phi-4 Technical Report
Dec 12, 2024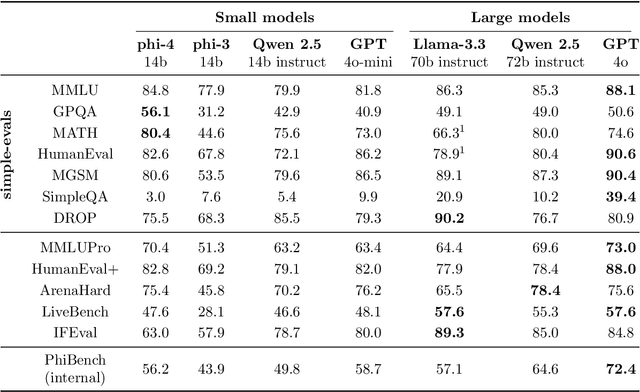
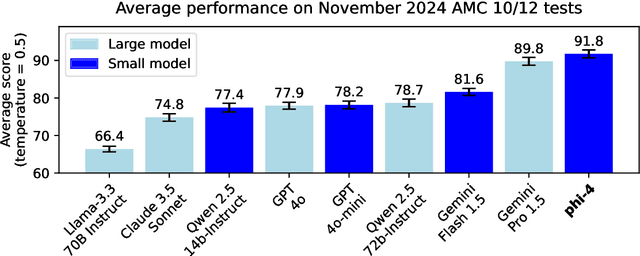

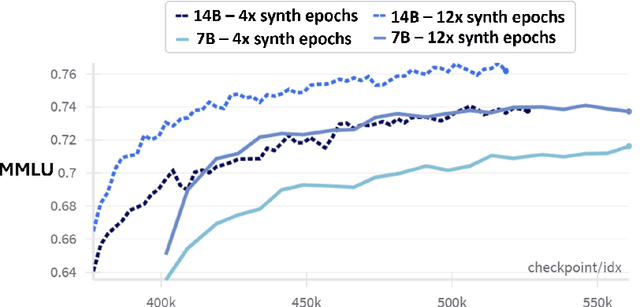
We present phi-4, a 14-billion parameter language model developed with a training recipe that is centrally focused on data quality. Unlike most language models, where pre-training is based primarily on organic data sources such as web content or code, phi-4 strategically incorporates synthetic data throughout the training process. While previous models in the Phi family largely distill the capabilities of a teacher model (specifically GPT-4), phi-4 substantially surpasses its teacher model on STEM-focused QA capabilities, giving evidence that our data-generation and post-training techniques go beyond distillation. Despite minimal changes to the phi-3 architecture, phi-4 achieves strong performance relative to its size -- especially on reasoning-focused benchmarks -- due to improved data, training curriculum, and innovations in the post-training scheme.
NCDD: Nearest Centroid Distance Deficit for Out-Of-Distribution Detection in Gastrointestinal Vision
Dec 02, 2024



The integration of deep learning tools in gastrointestinal vision holds the potential for significant advancements in diagnosis, treatment, and overall patient care. A major challenge, however, is these tools' tendency to make overconfident predictions, even when encountering unseen or newly emerging disease patterns, undermining their reliability. We address this critical issue of reliability by framing it as an out-of-distribution (OOD) detection problem, where previously unseen and emerging diseases are identified as OOD examples. However, gastrointestinal images pose a unique challenge due to the overlapping feature representations between in- Distribution (ID) and OOD examples. Existing approaches often overlook this characteristic, as they are primarily developed for natural image datasets, where feature distinctions are more apparent. Despite the overlap, we hypothesize that the features of an in-distribution example will cluster closer to the centroids of their ground truth class, resulting in a shorter distance to the nearest centroid. In contrast, OOD examples maintain an equal distance from all class centroids. Based on this observation, we propose a novel nearest-centroid distance deficit (NCCD) score in the feature space for gastrointestinal OOD detection. Evaluations across multiple deep learning architectures and two publicly available benchmarks, Kvasir2 and Gastrovision, demonstrate the effectiveness of our approach compared to several state-of-the-art methods. The code and implementation details are publicly available at: https://github.com/bhattarailab/NCDD
FG-CXR: A Radiologist-Aligned Gaze Dataset for Enhancing Interpretability in Chest X-Ray Report Generation
Nov 23, 2024



Developing an interpretable system for generating reports in chest X-ray (CXR) analysis is becoming increasingly crucial in Computer-aided Diagnosis (CAD) systems, enabling radiologists to comprehend the decisions made by these systems. Despite the growth of diverse datasets and methods focusing on report generation, there remains a notable gap in how closely these models' generated reports align with the interpretations of real radiologists. In this study, we tackle this challenge by initially introducing Fine-Grained CXR (FG-CXR) dataset, which provides fine-grained paired information between the captions generated by radiologists and the corresponding gaze attention heatmaps for each anatomy. Unlike existing datasets that include a raw sequence of gaze alongside a report, with significant misalignment between gaze location and report content, our FG-CXR dataset offers a more grained alignment between gaze attention and diagnosis transcript. Furthermore, our analysis reveals that simply applying black-box image captioning methods to generate reports cannot adequately explain which information in CXR is utilized and how long needs to attend to accurately generate reports. Consequently, we propose a novel explainable radiologist's attention generator network (Gen-XAI) that mimics the diagnosis process of radiologists, explicitly constraining its output to closely align with both radiologist's gaze attention and transcript. Finally, we perform extensive experiments to illustrate the effectiveness of our method. Our datasets and checkpoint is available at https://github.com/UARK-AICV/FG-CXR.
Fine-Grained Alignment in Vision-and-Language Navigation through Bayesian Optimization
Nov 22, 2024



This paper addresses the challenge of fine-grained alignment in Vision-and-Language Navigation (VLN) tasks, where robots navigate realistic 3D environments based on natural language instructions. Current approaches use contrastive learning to align language with visual trajectory sequences. Nevertheless, they encounter difficulties with fine-grained vision negatives. To enhance cross-modal embeddings, we introduce a novel Bayesian Optimization-based adversarial optimization framework for creating fine-grained contrastive vision samples. To validate the proposed methodology, we conduct a series of experiments to assess the effectiveness of the enriched embeddings on fine-grained vision negatives. We conduct experiments on two common VLN benchmarks R2R and REVERIE, experiments on the them demonstrate that these embeddings benefit navigation, and can lead to a promising performance enhancement. Our source code and trained models are available at: https://anonymous.4open.science/r/FGVLN.
Personalize to generalize: Towards a universal medical multi-modality generalization through personalization
Nov 13, 2024The differences among medical imaging modalities, driven by distinct underlying principles, pose significant challenges for generalization in multi-modal medical tasks. Beyond modality gaps, individual variations, such as differences in organ size and metabolic rate, further impede a model's ability to generalize effectively across both modalities and diverse populations. Despite the importance of personalization, existing approaches to multi-modal generalization often neglect individual differences, focusing solely on common anatomical features. This limitation may result in weakened generalization in various medical tasks. In this paper, we unveil that personalization is critical for multi-modal generalization. Specifically, we propose an approach to achieve personalized generalization through approximating the underlying personalized invariant representation ${X}_h$ across various modalities by leveraging individual-level constraints and a learnable biological prior. We validate the feasibility and benefits of learning a personalized ${X}_h$, showing that this representation is highly generalizable and transferable across various multi-modal medical tasks. Extensive experimental results consistently show that the additionally incorporated personalization significantly improves performance and generalization across diverse scenarios, confirming its effectiveness.