 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVDGC: Joint 3D and 2D Multi-view Pedestrian Detection via Dual Geometric Constraints
Jun 30, 2026The core challenge in multi-view pedestrian detection (MVPD) lies in effective aggregation of visual features from different viewpoints for robust occlusion reasoning. Recent approaches have addressed this by first projecting image-view features onto a Bird's Eye View (BEV) map, where ground localization is then performed. Despite impressive performance, the perspective transformation induces severe distortion, causing spatial structure break and degrading the quality of object feature extraction. The blurred and ambiguous features hinder accurate BEV point localization, especially in densely populated regions. Moreover, the strong mutual relationship between the BEV ground point and image bounding boxes is not capitalized on. Although multi-view consistency of 2D detections can serve as a powerful constraint in BEV space, these detections are commonly treated as auxiliary signals rather than being jointly optimized with the primary task.In this work, we propose \textbf{MVDGC}, a unified framework that \emph{jointly estimates pedestrian locations on the BEV plane and 2D bounding boxes in image views}. MVDGC employs a \emph{sparse set of 3D cylindrical queries} that embraces geometric context across both BEV and image views, enforcing dual spatial constraints for precise localization. Specifically, the geometric constraints is established by modeling each pedestrian as a vertical cylinder whose center lies on the BEV plane and whose projection casts a rectangular box in the image views. These queries function as shape anchors that directly extract 2D features from the intact image-view features using camera projection, eliminating projection-induced distortions. The 3D cylindrical query enables the unification of BEV and ImV localization into a single task: 3D cylinder position and shape refinement. Code is available at: https://github.com/UARK-AICV/MVDGC
SemLT3D: Semantic-Guided Expert Distillation for Camera-only Long-Tailed 3D Object Detection
Apr 20, 2026Camera-only 3D object detection has emerged as a cost-effective and scalable alternative to LiDAR for autonomous driving, yet existing methods primarily prioritize overall performance while overlooking the severe long-tail imbalance inherent in real-world datasets. In practice, many rare but safety-critical categories such as children, strollers, or emergency vehicles are heavily underrepresented, leading to biased learning and degraded performance. This challenge is further exacerbated by pronounced inter-class ambiguity (e.g., visually similar subclasses) and substantial intra-class diversity (e.g., objects varying widely in appearance, scale, pose, or context), which together hinder reliable long-tail recognition. In this work, we introduce SemLT3D, a Semantic-Guided Expert Distillation framework designed to enrich the representation space for underrepresented classes through semantic priors. SemLT3D consists of: (1) a language-guided mixture-of-experts module that routes 3D queries to specialized experts according to their semantic affinity, enabling the model to better disentangle confusing classes and specialize on tail distributions; and (2) a semantic projection distillation pipeline that aligns 3D queries with CLIP-informed 2D semantics, producing more coherent and discriminative features across diverse visual manifestations. Although motivated by long-tail imbalance, the semantically structured learning in SemLT3D also improves robustness under broader appearance variations and challenging corner cases, offering a principled step toward more reliable camera-only 3D perception.
FG-CXR: A Radiologist-Aligned Gaze Dataset for Enhancing Interpretability in Chest X-Ray Report Generation
Nov 23, 2024



Developing an interpretable system for generating reports in chest X-ray (CXR) analysis is becoming increasingly crucial in Computer-aided Diagnosis (CAD) systems, enabling radiologists to comprehend the decisions made by these systems. Despite the growth of diverse datasets and methods focusing on report generation, there remains a notable gap in how closely these models' generated reports align with the interpretations of real radiologists. In this study, we tackle this challenge by initially introducing Fine-Grained CXR (FG-CXR) dataset, which provides fine-grained paired information between the captions generated by radiologists and the corresponding gaze attention heatmaps for each anatomy. Unlike existing datasets that include a raw sequence of gaze alongside a report, with significant misalignment between gaze location and report content, our FG-CXR dataset offers a more grained alignment between gaze attention and diagnosis transcript. Furthermore, our analysis reveals that simply applying black-box image captioning methods to generate reports cannot adequately explain which information in CXR is utilized and how long needs to attend to accurately generate reports. Consequently, we propose a novel explainable radiologist's attention generator network (Gen-XAI) that mimics the diagnosis process of radiologists, explicitly constraining its output to closely align with both radiologist's gaze attention and transcript. Finally, we perform extensive experiments to illustrate the effectiveness of our method. Our datasets and checkpoint is available at https://github.com/UARK-AICV/FG-CXR.
TrackMe:A Simple and Effective Multiple Object Tracking Annotation Tool
Oct 20, 2024



Object tracking, especially animal tracking, is one of the key topics that attract a lot of attention due to its benefits of animal behavior understanding and monitoring. Recent state-of-the-art tracking methods are founded on deep learning architectures for object detection, appearance feature extraction and track association. Despite the good tracking performance, these methods are trained and evaluated on common objects such as human and cars. To perform on the animal, there is a need to create large datasets of different types in multiple conditions. The dataset construction comprises of data collection and data annotation. In this work, we put more focus on the latter task. Particularly, we renovate the well-known tool, LabelMe, so as to assist common user with or without in-depth knowledge about computer science to annotate the data with less effort. The new tool named as TrackMe inherits the simplicity, high compatibility with varied systems, minimal hardware requirement and convenient feature utilization from the predecessor. TrackMe is an upgraded version with essential features for multiple object tracking annotation.
Facial Chick Sexing: An Automated Chick Sexing System From Chick Facial Image
Oct 11, 2024



Chick sexing, the process of determining the gender of day-old chicks, is a critical task in the poultry industry due to the distinct roles that each gender plays in production. While effective traditional methods achieve high accuracy, color, and wing feather sexing is exclusive to specific breeds, and vent sexing is invasive and requires trained experts. To address these challenges, we propose a novel approach inspired by facial gender classification techniques in humans: facial chick sexing. This new method does not require expert knowledge and aims to reduce training time while enhancing animal welfare by minimizing chick manipulation. We develop a comprehensive system for training and inference that includes data collection, facial and keypoint detection, facial alignment, and classification. We evaluate our model on two sets of images: Cropped Full Face and Cropped Middle Face, both of which maintain essential facial features of the chick for further analysis. Our experiment demonstrates the promising viability, with a final accuracy of 81.89%, of this approach for future practices in chick sexing by making them more universally applicable.
HENASY: Learning to Assemble Scene-Entities for Egocentric Video-Language Model
Jun 01, 2024



Video-Language Models (VLMs), pre-trained on large-scale video-caption datasets, are now standard for robust visual-language representation and downstream tasks. However, their reliance on global contrastive alignment limits their ability to capture fine-grained interactions between visual and textual elements. To address these challenges, we introduce HENASY (Hierarchical ENtities ASsemblY), a novel framework designed for egocentric video analysis that enhances the granularity of video content representations. HENASY employs a compositional approach using an enhanced slot-attention and grouping mechanisms for videos, assembling dynamic entities from video patches. It integrates a local entity encoder for dynamic modeling, a global encoder for broader contextual understanding, and an entity-aware decoder for late-stage fusion, enabling effective video scene dynamics modeling and granular-level alignment between visual entities and text. By incorporating innovative contrastive losses, HENASY significantly improves entity and activity recognition, delivering superior performance on benchmarks such as Ego4D and EpicKitchen, and setting new standards in both zero-shot and extensive video understanding tasks. Our results confirm groundbreaking capabilities of HENASY and establish it as a significant advancement in video-language multimodal research.
TSRNet: Simple Framework for Real-time ECG Anomaly Detection with Multimodal Time and Spectrogram Restoration Network
Dec 15, 2023



The electrocardiogram (ECG) is a valuable signal used to assess various aspects of heart health, such as heart rate and rhythm. It plays a crucial role in identifying cardiac conditions and detecting anomalies in ECG data. However, distinguishing between normal and abnormal ECG signals can be a challenging task. In this paper, we propose an approach that leverages anomaly detection to identify unhealthy conditions using solely normal ECG data for training. Furthermore, to enhance the information available and build a robust system, we suggest considering both the time series and time-frequency domain aspects of the ECG signal. As a result, we introduce a specialized network called the Multimodal Time and Spectrogram Restoration Network (TSRNet) designed specifically for detecting anomalies in ECG signals. TSRNet falls into the category of restoration-based anomaly detection and draws inspiration from both the time series and spectrogram domains. By extracting representations from both domains, TSRNet effectively captures the comprehensive characteristics of the ECG signal. This approach enables the network to learn robust representations with superior discrimination abilities, allowing it to distinguish between normal and abnormal ECG patterns more effectively. Furthermore, we introduce a novel inference method, termed Peak-based Error, that specifically focuses on ECG peaks, a critical component in detecting abnormalities. The experimental result on the large-scale dataset PTB-XL has demonstrated the effectiveness of our approach in ECG anomaly detection, while also prioritizing efficiency by minimizing the number of trainable parameters. Our code is available at https://github.com/UARK-AICV/TSRNet.
ZEETAD: Adapting Pretrained Vision-Language Model for Zero-Shot End-to-End Temporal Action Detection
Nov 04, 2023



Temporal action detection (TAD) involves the localization and classification of action instances within untrimmed videos. While standard TAD follows fully supervised learning with closed-set setting on large training data, recent zero-shot TAD methods showcase the promising open-set setting by leveraging large-scale contrastive visual-language (ViL) pretrained models. However, existing zero-shot TAD methods have limitations on how to properly construct the strong relationship between two interdependent tasks of localization and classification and adapt ViL model to video understanding. In this work, we present ZEETAD, featuring two modules: dual-localization and zero-shot proposal classification. The former is a Transformer-based module that detects action events while selectively collecting crucial semantic embeddings for later recognition. The latter one, CLIP-based module, generates semantic embeddings from text and frame inputs for each temporal unit. Additionally, we enhance discriminative capability on unseen classes by minimally updating the frozen CLIP encoder with lightweight adapters. Extensive experiments on THUMOS14 and ActivityNet-1.3 datasets demonstrate our approach's superior performance in zero-shot TAD and effective knowledge transfer from ViL models to unseen action categories.
Z-GMOT: Zero-shot Generic Multiple Object Tracking
May 28, 2023Despite the significant progress made in recent years, Multi-Object Tracking (MOT) approaches still suffer from several limitations, including their reliance on prior knowledge of tracking targets, which necessitates the costly annotation of large labeled datasets. As a result, existing MOT methods are limited to a small set of predefined categories, and they struggle with unseen objects in the real world. To address these issues, Generic Multiple Object Tracking (GMOT) has been proposed, which requires less prior information about the targets. However, all existing GMOT approaches follow a one-shot paradigm, relying mainly on the initial bounding box and thus struggling to handle variants e.g., viewpoint, lighting, occlusion, scale, and etc. In this paper, we introduce a novel approach to address the limitations of existing MOT and GMOT methods. Specifically, we propose a zero-shot GMOT (Z-GMOT) algorithm that can track never-seen object categories with zero training examples, without the need for predefined categories or an initial bounding box. To achieve this, we propose iGLIP, an improved version of Grounded language-image pretraining (GLIP), which can detect unseen objects while minimizing false positives. We evaluate our Z-GMOT thoroughly on the GMOT-40 dataset, AnimalTrack testset, DanceTrack testset. The results of these evaluations demonstrate a significant improvement over existing methods. For instance, on the GMOT-40 dataset, the Z-GMOT outperforms one-shot GMOT with OC-SORT by 27.79 points HOTA and 44.37 points MOTA. On the AnimalTrack dataset, it surpasses fully-supervised methods with DeepSORT by 12.55 points HOTA and 8.97 points MOTA. To facilitate further research, we will make our code and models publicly available upon acceptance of this paper.
Multimodality Multi-Lead ECG Arrhythmia Classification using Self-Supervised Learning
Sep 30, 2022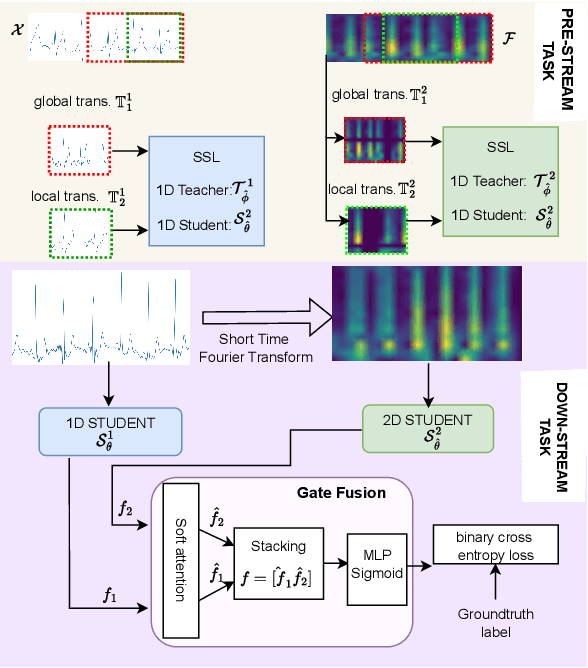
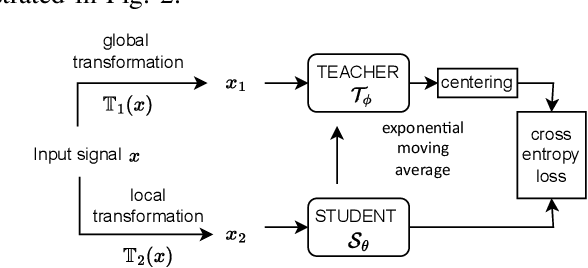
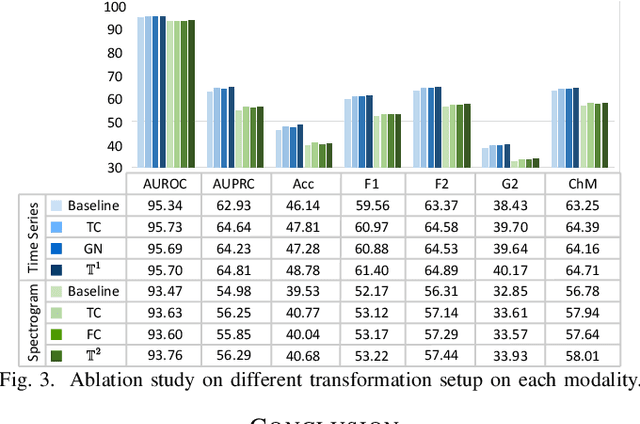
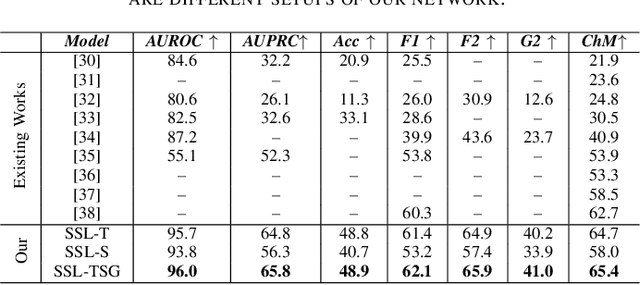
Electrocardiogram (ECG) signal is one of the most effective sources of information mainly employed for the diagnosis and prediction of cardiovascular diseases (CVDs) connected with the abnormalities in heart rhythm. Clearly, single modality ECG (i.e. time series) cannot convey its complete characteristics, thus, exploiting both time and time-frequency modalities in the form of time-series data and spectrogram is needed. Leveraging the cutting-edge self-supervised learning (SSL) technique on unlabeled data, we propose SSL-based multimodality ECG classification. Our proposed network follows SSL learning paradigm and consists of two modules corresponding to pre-stream task, and down-stream task, respectively. In the SSL-pre-stream task, we utilize self-knowledge distillation (KD) techniques with no labeled data, on various transformations and in both time and frequency domains. In the down-stream task, which is trained on labeled data, we propose a gate fusion mechanism to fuse information from multimodality.To evaluate the effectiveness of our approach, ten-fold cross validation on the 12-lead PhysioNet 2020 dataset has been conducted.