 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepurposing Existing Deep Networks for Caption and Aesthetic-Guided Image Cropping
Jan 07, 2022
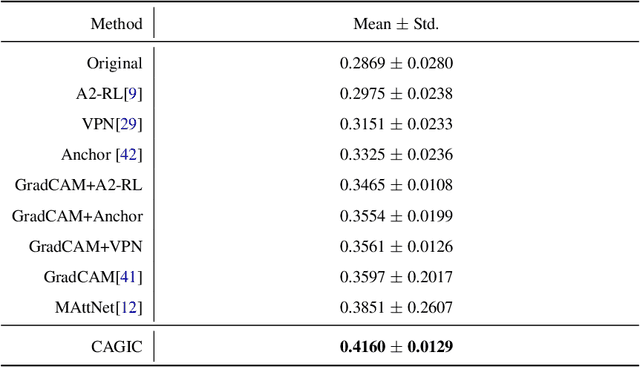
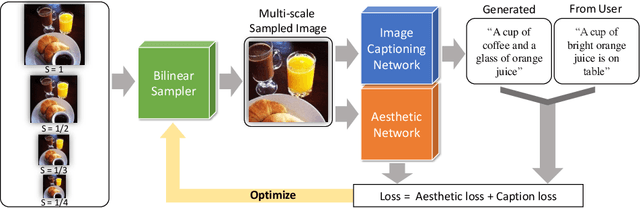
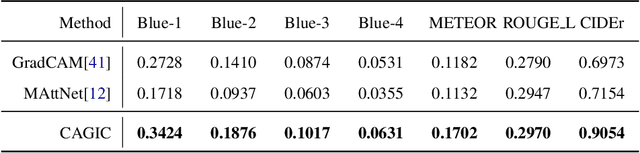
We propose a novel optimization framework that crops a given image based on user description and aesthetics. Unlike existing image cropping methods, where one typically trains a deep network to regress to crop parameters or cropping actions, we propose to directly optimize for the cropping parameters by repurposing pre-trained networks on image captioning and aesthetic tasks, without any fine-tuning, thereby avoiding training a separate network. Specifically, we search for the best crop parameters that minimize a combined loss of the initial objectives of these networks. To make the optimization table, we propose three strategies: (i) multi-scale bilinear sampling, (ii) annealing the scale of the crop region, therefore effectively reducing the parameter space, (iii) aggregation of multiple optimization results. Through various quantitative and qualitative evaluations, we show that our framework can produce crops that are well-aligned to intended user descriptions and aesthetically pleasing.
Wild ToFu: Improving Range and Quality of Indirect Time-of-Flight Depth with RGB Fusion in Challenging Environments
Dec 07, 2021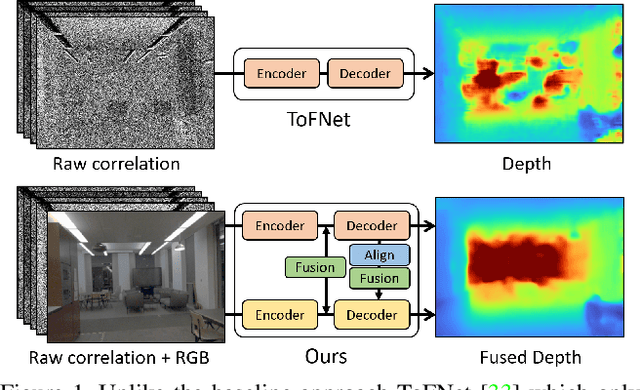

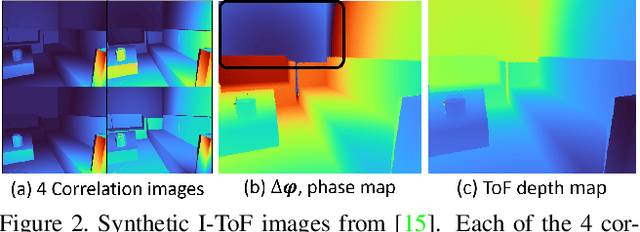
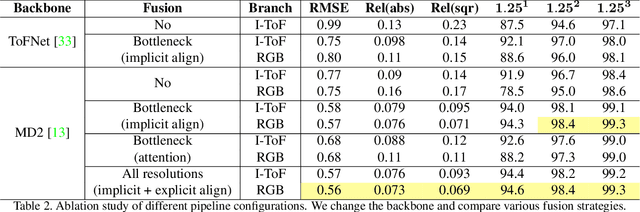
Indirect Time-of-Flight (I-ToF) imaging is a widespread way of depth estimation for mobile devices due to its small size and affordable price. Previous works have mainly focused on quality improvement for I-ToF imaging especially curing the effect of Multi Path Interference (MPI). These investigations are typically done in specifically constrained scenarios at close distance, indoors and under little ambient light. Surprisingly little work has investigated I-ToF quality improvement in real-life scenarios where strong ambient light and far distances pose difficulties due to an extreme amount of induced shot noise and signal sparsity, caused by the attenuation with limited sensor power and light scattering. In this work, we propose a new learning based end-to-end depth prediction network which takes noisy raw I-ToF signals as well as an RGB image and fuses their latent representation based on a multi step approach involving both implicit and explicit alignment to predict a high quality long range depth map aligned to the RGB viewpoint. We test our approach on challenging real-world scenes and show more than 40% RMSE improvement on the final depth map compared to the baseline approach.
Depth-only Object Tracking
Oct 22, 2021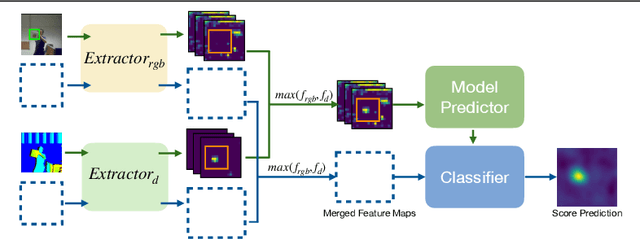


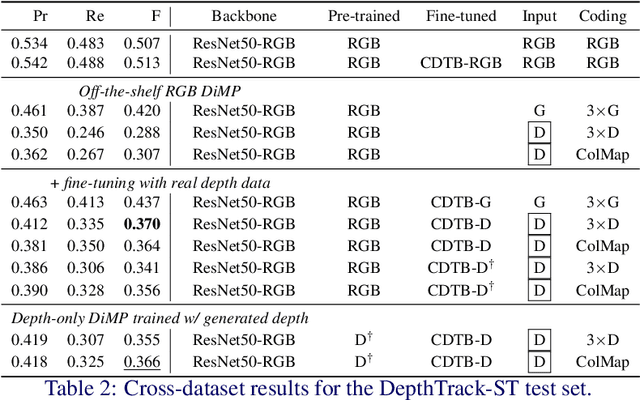
Depth (D) indicates occlusion and is less sensitive to illumination changes, which make depth attractive modality for Visual Object Tracking (VOT). Depth is used in RGBD object tracking where the best trackers are deep RGB trackers with additional heuristic using depth maps. There are two potential reasons for the heuristics: 1) the lack of large RGBD tracking datasets to train deep RGBD trackers and 2) the long-term evaluation protocol of VOT RGBD that benefits from heuristics such as depth-based occlusion detection. In this work, we study how far D-only tracking can go if trained with large amounts of depth data. To compensate the lack of depth data, we generate depth maps for tracking. We train a "Depth-DiMP" from the scratch with the generated data and fine-tune it with the available small RGBD tracking datasets. The depth-only DiMP achieves good accuracy in depth-only tracking and combined with the original RGB DiMP the end-to-end trained RGBD-DiMP outperforms the recent VOT 2020 RGBD winners.
Wavelet-Based Network For High Dynamic Range Imaging
Aug 03, 2021


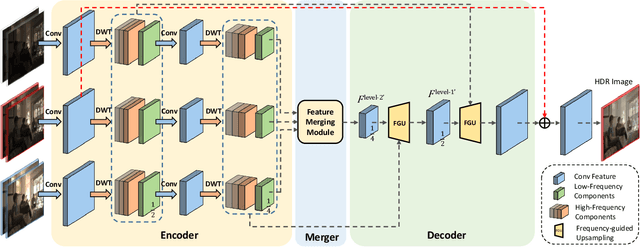
High dynamic range (HDR) imaging from multiple low dynamic range (LDR) images has been suffering from ghosting artifacts caused by scene and objects motion. Existing methods, such as optical flow based and end-to-end deep learning based solutions, are error-prone either in detail restoration or ghosting artifacts removal. Comprehensive empirical evidence shows that ghosting artifacts caused by large foreground motion are mainly low-frequency signals and the details are mainly high-frequency signals. In this work, we propose a novel frequency-guided end-to-end deep neural network (FHDRNet) to conduct HDR fusion in the frequency domain, and Discrete Wavelet Transform (DWT) is used to decompose inputs into different frequency bands. The low-frequency signals are used to avoid specific ghosting artifacts, while the high-frequency signals are used for preserving details. Using a U-Net as the backbone, we propose two novel modules: merging module and frequency-guided upsampling module. The merging module applies the attention mechanism to the low-frequency components to deal with the ghost caused by large foreground motion. The frequency-guided upsampling module reconstructs details from multiple frequency-specific components with rich details. In addition, a new RAW dataset is created for training and evaluating multi-frame HDR imaging algorithms in the RAW domain. Extensive experiments are conducted on public datasets and our RAW dataset, showing that the proposed FHDRNet achieves state-of-the-art performance.
Residual Contrastive Learning for Joint Demosaicking and Denoising
Jun 18, 2021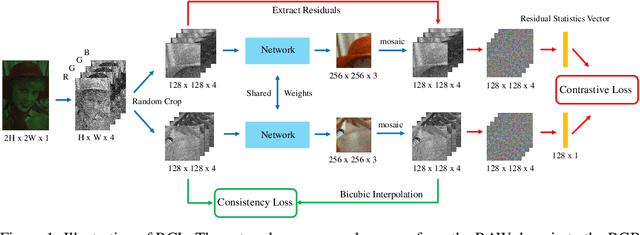
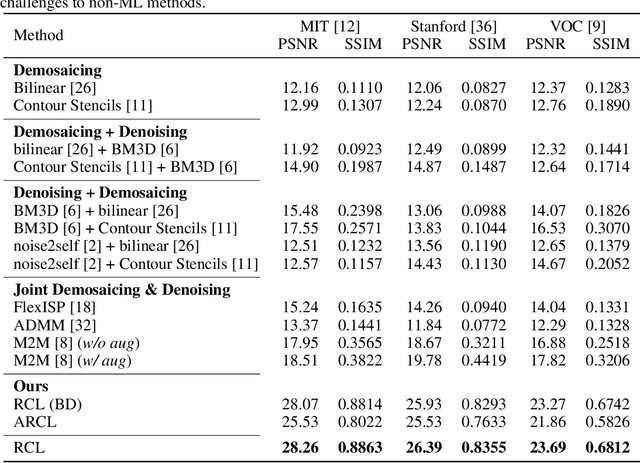

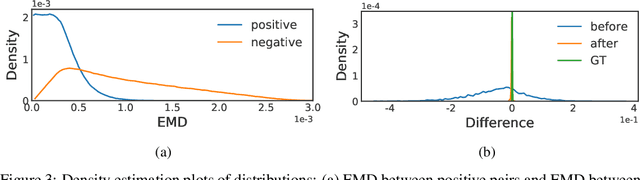
The breakthrough of contrastive learning (CL) has fueled the recent success of self-supervised learning (SSL) in high-level vision tasks on RGB images. However, CL is still ill-defined for low-level vision tasks, such as joint demosaicking and denoising (JDD), in the RAW domain. To bridge this methodological gap, we present a novel CL approach on RAW images, residual contrastive learning (RCL), which aims to learn meaningful representations for JDD. Our work is built on the assumption that noise contained in each RAW image is signal-dependent, thus two crops from the same RAW image should have more similar noise distribution than two crops from different RAW images. We use residuals as a discriminative feature and the earth mover's distance to measure the distribution divergence for the contrastive loss. To evaluate the proposed CL strategy, we simulate a series of unsupervised JDD experiments with large-scale data corrupted by synthetic signal-dependent noise, where we set a new benchmark for unsupervised JDD tasks with unknown (random) noise variance. Our empirical study not only validates that CL can be applied on distributions (c.f. features), but also exposes the lack of robustness of previous non-ML and SSL JDD methods when the statistics of the noise are unknown, thus providing some further insight into signal-dependent noise problems.
Learning a Model-Driven Variational Network for Deformable Image Registration
May 25, 2021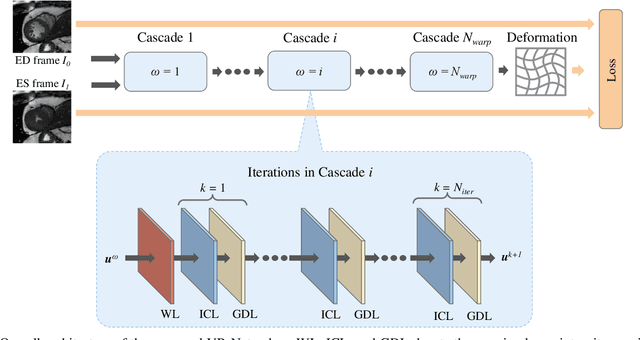
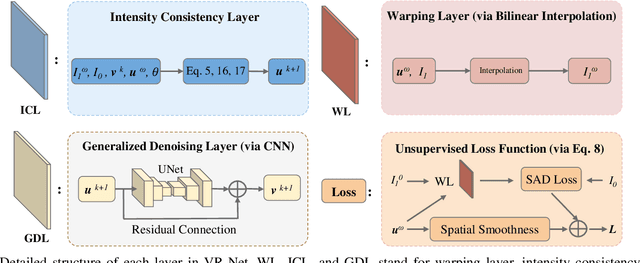
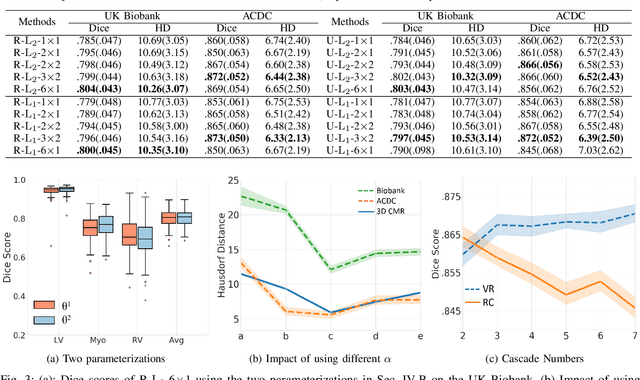
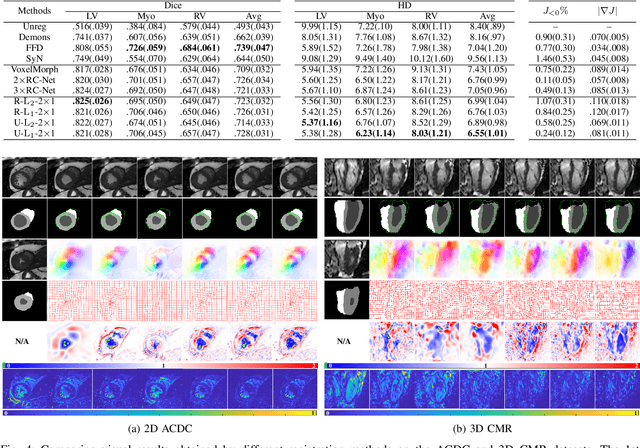
Data-driven deep learning approaches to image registration can be less accurate than conventional iterative approaches, especially when training data is limited. To address this whilst retaining the fast inference speed of deep learning, we propose VR-Net, a novel cascaded variational network for unsupervised deformable image registration. Using the variable splitting optimization scheme, we first convert the image registration problem, established in a generic variational framework, into two sub-problems, one with a point-wise, closed-form solution while the other one is a denoising problem. We then propose two neural layers (i.e. warping layer and intensity consistency layer) to model the analytical solution and a residual U-Net to formulate the denoising problem (i.e. generalized denoising layer). Finally, we cascade the warping layer, intensity consistency layer, and generalized denoising layer to form the VR-Net. Extensive experiments on three (two 2D and one 3D) cardiac magnetic resonance imaging datasets show that VR-Net outperforms state-of-the-art deep learning methods on registration accuracy, while maintains the fast inference speed of deep learning and the data-efficiency of variational model.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021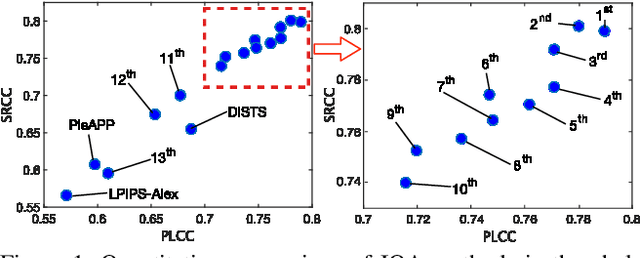
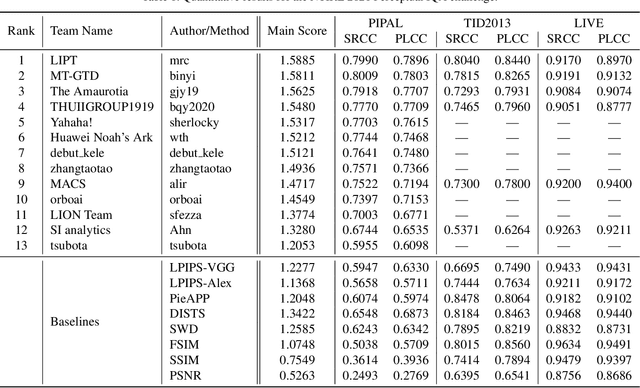

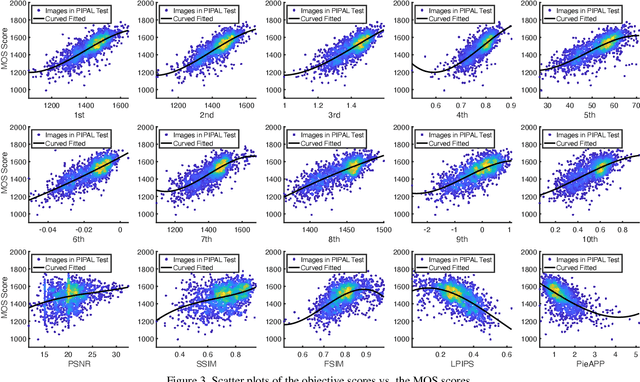
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.
SQN: Weakly-Supervised Semantic Segmentation of Large-Scale 3D Point Clouds with 1000x Fewer Labels
Apr 11, 2021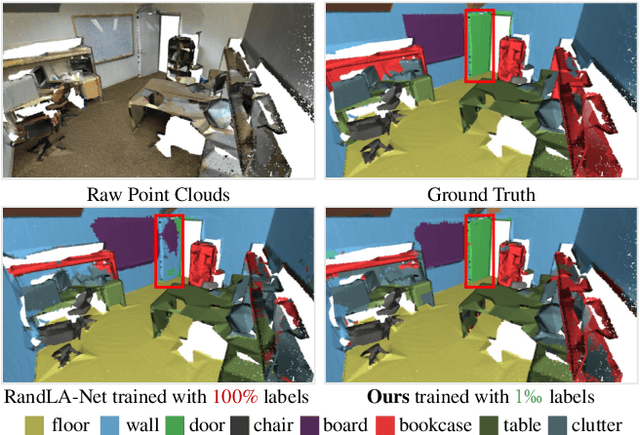
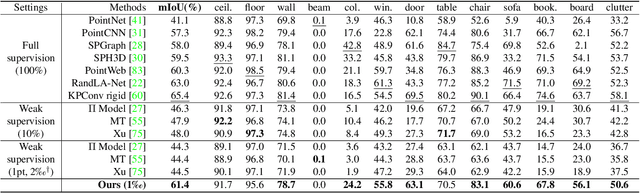
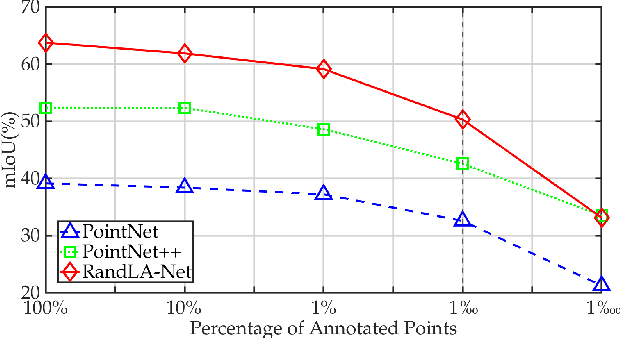
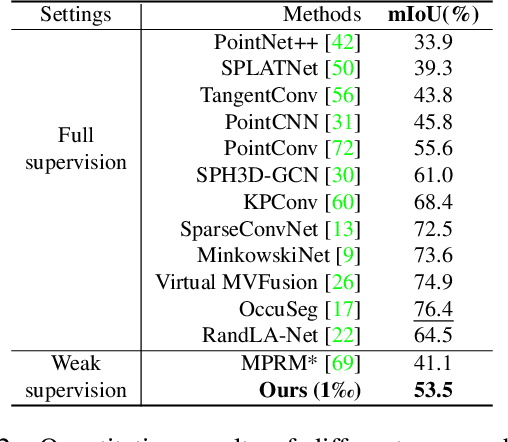
We study the problem of labelling effort for semantic segmentation of large-scale 3D point clouds. Existing works usually rely on densely annotated point-level semantic labels to provide supervision for network training. However, in real-world scenarios that contain billions of points, it is impractical and extremely costly to manually annotate every single point. In this paper, we first investigate whether dense 3D labels are truly required for learning meaningful semantic representations. Interestingly, we find that the segmentation performance of existing works only drops slightly given as few as 1% of the annotations. However, beyond this point (e.g. 1 per thousand and below) existing techniques fail catastrophically. To this end, we propose a new weak supervision method to implicitly augment the total amount of available supervision signals, by leveraging the semantic similarity between neighboring points. Extensive experiments demonstrate that the proposed Semantic Query Network (SQN) achieves state-of-the-art performance on six large-scale open datasets under weak supervision schemes, while requiring only 1000x fewer labeled points for training. The code is available at https://github.com/QingyongHu/SQN.
FS-Net: Fast Shape-based Network for Category-Level 6D Object Pose Estimation with Decoupled Rotation Mechanism
Mar 12, 2021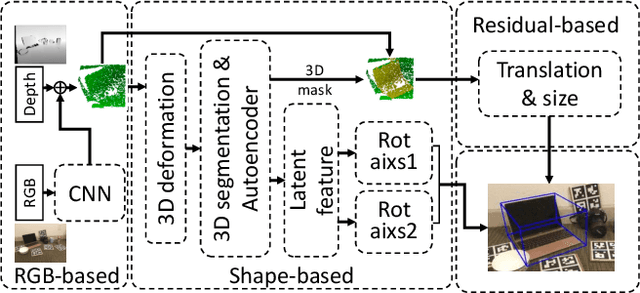
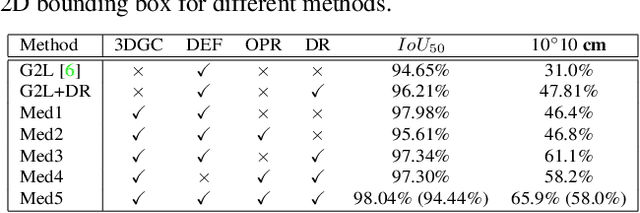
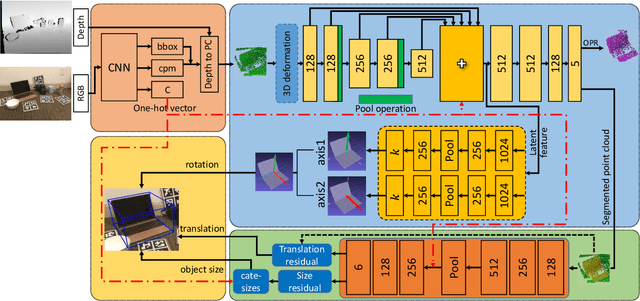
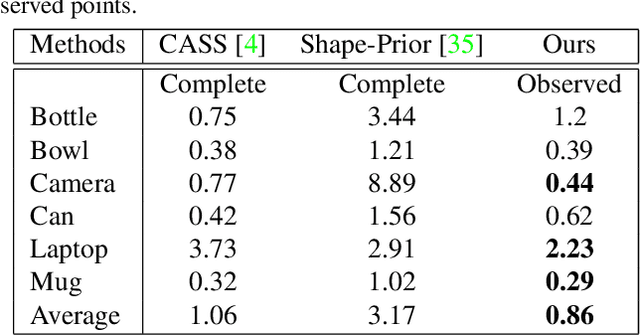
In this paper, we focus on category-level 6D pose and size estimation from monocular RGB-D image. Previous methods suffer from inefficient category-level pose feature extraction which leads to low accuracy and inference speed. To tackle this problem, we propose a fast shape-based network (FS-Net) with efficient category-level feature extraction for 6D pose estimation. First, we design an orientation aware autoencoder with 3D graph convolution for latent feature extraction. The learned latent feature is insensitive to point shift and object size thanks to the shift and scale-invariance properties of the 3D graph convolution. Then, to efficiently decode category-level rotation information from the latent feature, we propose a novel decoupled rotation mechanism that employs two decoders to complementarily access the rotation information. Meanwhile, we estimate translation and size by two residuals, which are the difference between the mean of object points and ground truth translation, and the difference between the mean size of the category and ground truth size, respectively. Finally, to increase the generalization ability of FS-Net, we propose an online box-cage based 3D deformation mechanism to augment the training data. Extensive experiments on two benchmark datasets show that the proposed method achieves state-of-the-art performance in both category- and instance-level 6D object pose estimation. Especially in category-level pose estimation, without extra synthetic data, our method outperforms existing methods by 6.3% on the NOCS-REAL dataset.
Diagnosing and Preventing Instabilities in Recurrent Video Processing
Oct 17, 2020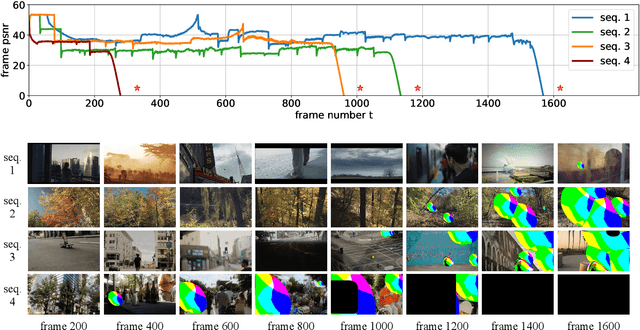
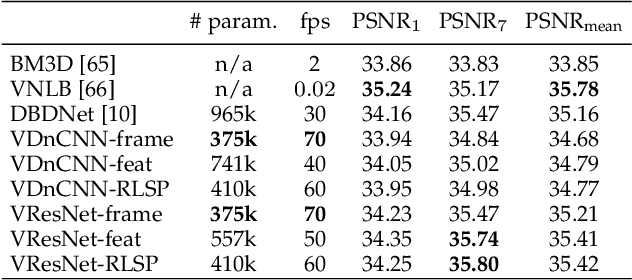
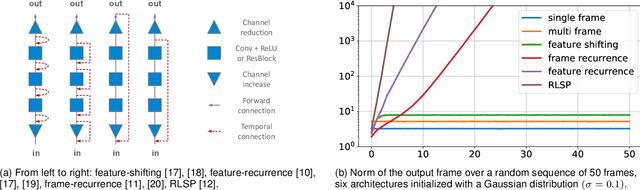
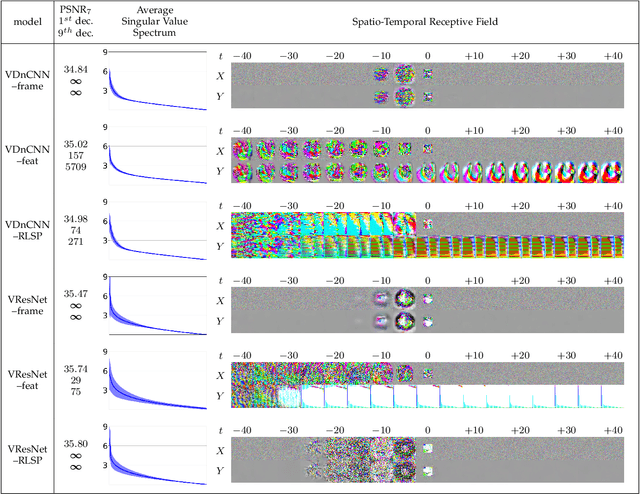
Recurrent models are becoming a popular choice for video enhancement tasks such as video denoising. In this work, we focus on their stability as dynamical systems and show that they tend to fail catastrophically at inference time on long video sequences. To address this issue, we (1) introduce a diagnostic tool which produces adversarial input sequences optimized to trigger instabilities and that can be interpreted as visualizations of spatio-temporal receptive fields, and (2) propose two approaches to enforce the stability of a model: constraining the spectral norm or constraining the stable rank of its convolutional layers. We then introduce Stable Rank Normalization of the Layers (SRNL), a new algorithm that enforces these constraints, and verify experimentally that it successfully results in stable recurrent video processing.