 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Inference and Transfer of Compositional Task Structures for Few-shot Task Generalization
May 25, 2022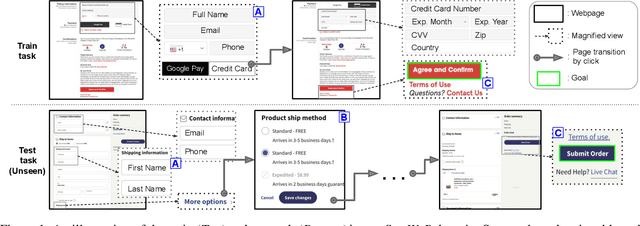
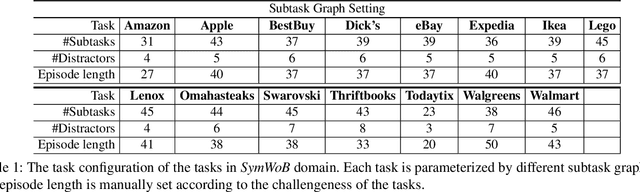
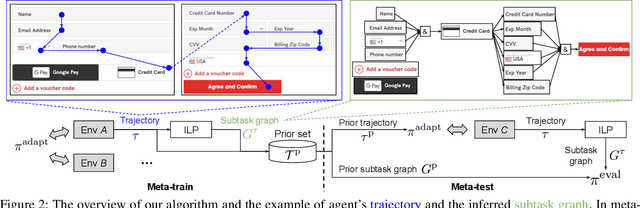

We tackle real-world problems with complex structures beyond the pixel-based game or simulator. We formulate it as a few-shot reinforcement learning problem where a task is characterized by a subtask graph that defines a set of subtasks and their dependencies that are unknown to the agent. Different from the previous meta-rl methods trying to directly infer the unstructured task embedding, our multi-task subtask graph inferencer (MTSGI) first infers the common high-level task structure in terms of the subtask graph from the training tasks, and use it as a prior to improve the task inference in testing. Our experiment results on 2D grid-world and complex web navigation domains show that the proposed method can learn and leverage the common underlying structure of the tasks for faster adaptation to the unseen tasks than various existing algorithms such as meta reinforcement learning, hierarchical reinforcement learning, and other heuristic agents.
Tiny Robot Learning: Challenges and Directions for Machine Learning in Resource-Constrained Robots
May 11, 2022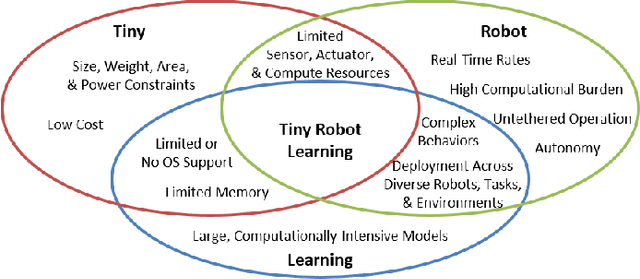
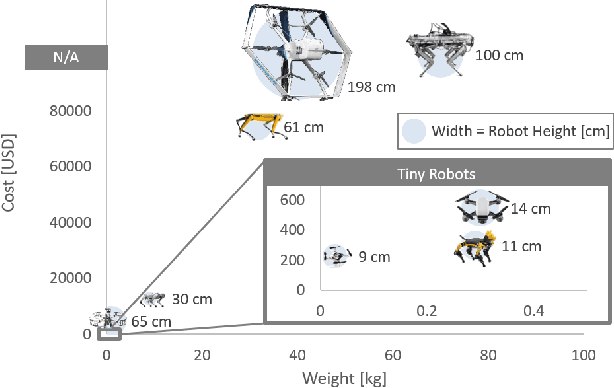
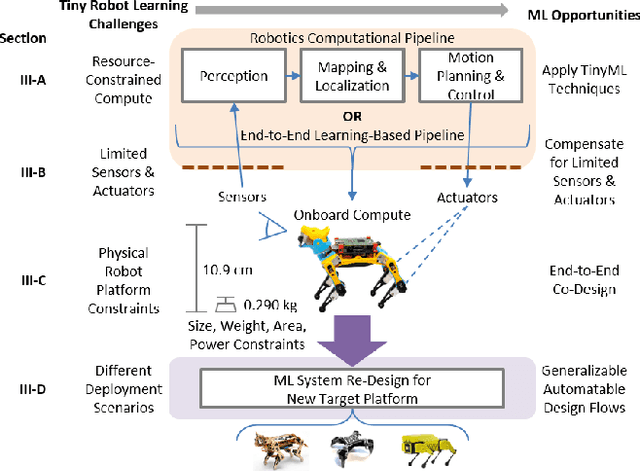
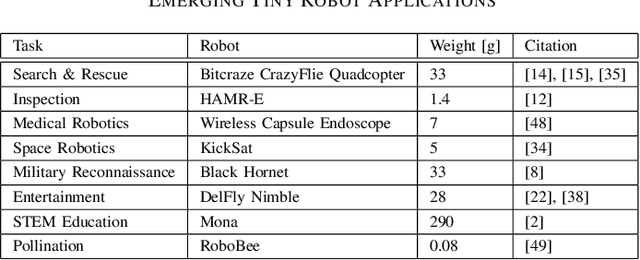
Machine learning (ML) has become a pervasive tool across computing systems. An emerging application that stress-tests the challenges of ML system design is tiny robot learning, the deployment of ML on resource-constrained low-cost autonomous robots. Tiny robot learning lies at the intersection of embedded systems, robotics, and ML, compounding the challenges of these domains. Tiny robot learning is subject to challenges from size, weight, area, and power (SWAP) constraints; sensor, actuator, and compute hardware limitations; end-to-end system tradeoffs; and a large diversity of possible deployment scenarios. Tiny robot learning requires ML models to be designed with these challenges in mind, providing a crucible that reveals the necessity of holistic ML system design and automated end-to-end design tools for agile development. This paper gives a brief survey of the tiny robot learning space, elaborates on key challenges, and proposes promising opportunities for future work in ML system design.
Roofline Model for UAVs: A Bottleneck Analysis Tool for Onboard Compute Characterization of Autonomous Unmanned Aerial Vehicles
Apr 22, 2022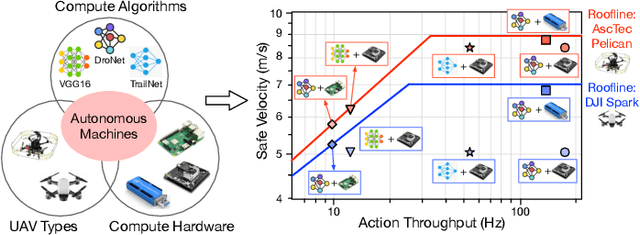
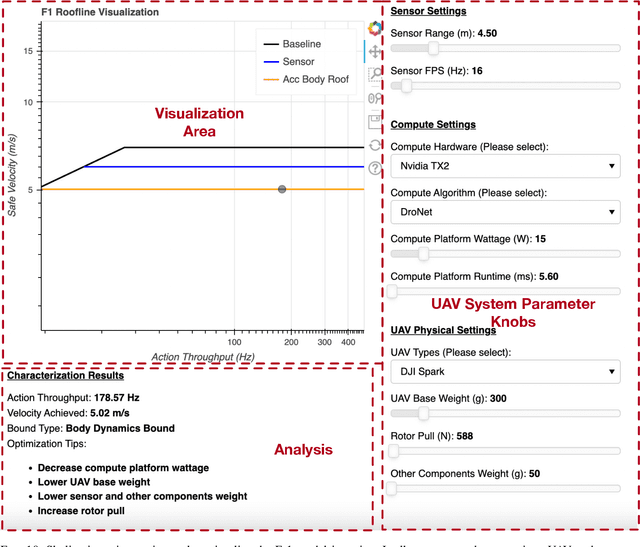
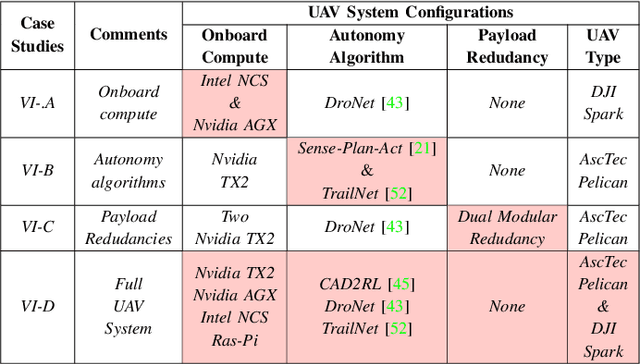
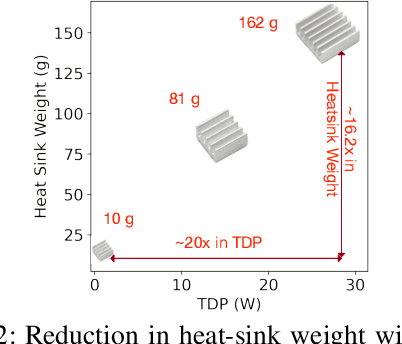
We introduce an early-phase bottleneck analysis and characterization model called the F-1 for designing computing systems that target autonomous Unmanned Aerial Vehicles (UAVs). The model provides insights by exploiting the fundamental relationships between various components in the autonomous UAV, such as sensor, compute, and body dynamics. To guarantee safe operation while maximizing the performance (e.g., velocity) of the UAV, the compute, sensor, and other mechanical properties must be carefully selected or designed. The F-1 model provides visual insights that can aid a system architect in understanding the optimal compute design or selection for autonomous UAVs. The model is experimentally validated using real UAVs, and the error is between 5.1\% to 9.5\% compared to real-world flight tests. An interactive web-based tool for the F-1 model called Skyline is available for free of cost use at: ~\url{https://bit.ly/skyline-tool}
Multi-objective evolution for Generalizable Policy Gradient Algorithms
Apr 08, 2022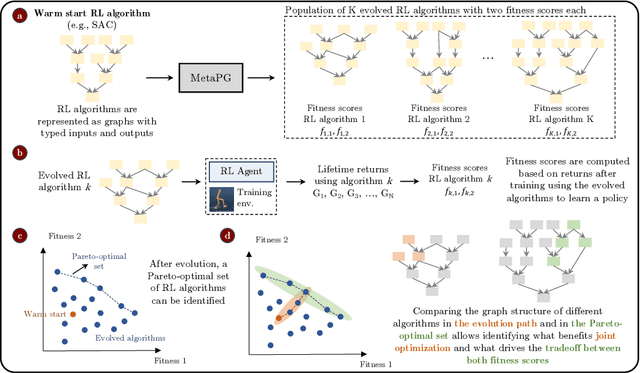
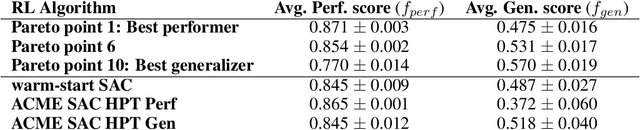
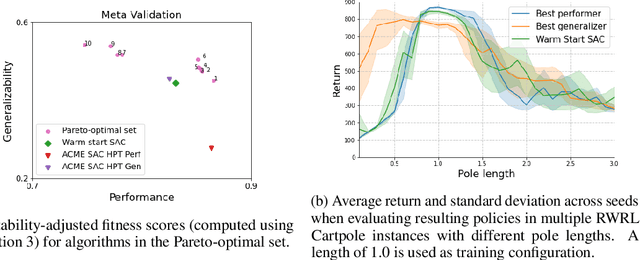
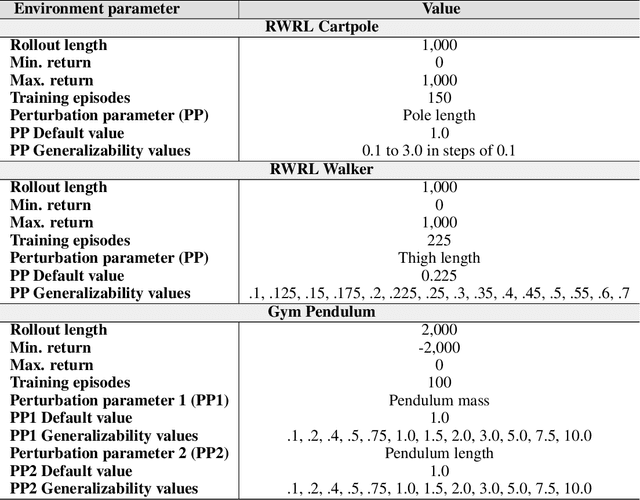
Performance, generalizability, and stability are three Reinforcement Learning (RL) challenges relevant to many practical applications in which they present themselves in combination. Still, state-of-the-art RL algorithms fall short when addressing multiple RL objectives simultaneously and current human-driven design practices might not be well-suited for multi-objective RL. In this paper we present MetaPG, an evolutionary method that discovers new RL algorithms represented as graphs, following a multi-objective search criteria in which different RL objectives are encoded in separate fitness scores. Our findings show that, when using a graph-based implementation of Soft Actor-Critic (SAC) to initialize the population, our method is able to find new algorithms that improve upon SAC's performance and generalizability by 3% and 17%, respectively, and reduce instability up to 65%. In addition, we analyze the graph structure of the best algorithms in the population and offer an interpretation of specific elements that help trading performance for generalizability and vice versa. We validate our findings in three different continuous control tasks: RWRL Cartpole, RWRL Walker, and Gym Pendulum.
Environment Generation for Zero-Shot Compositional Reinforcement Learning
Jan 21, 2022
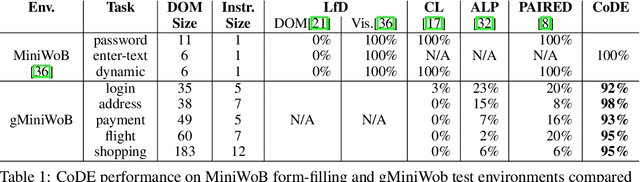

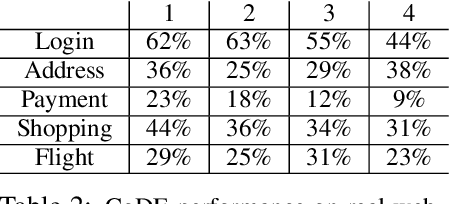
Many real-world problems are compositional - solving them requires completing interdependent sub-tasks, either in series or in parallel, that can be represented as a dependency graph. Deep reinforcement learning (RL) agents often struggle to learn such complex tasks due to the long time horizons and sparse rewards. To address this problem, we present Compositional Design of Environments (CoDE), which trains a Generator agent to automatically build a series of compositional tasks tailored to the RL agent's current skill level. This automatic curriculum not only enables the agent to learn more complex tasks than it could have otherwise, but also selects tasks where the agent's performance is weak, enhancing its robustness and ability to generalize zero-shot to unseen tasks at test-time. We analyze why current environment generation techniques are insufficient for the problem of generating compositional tasks, and propose a new algorithm that addresses these issues. Our results assess learning and generalization across multiple compositional tasks, including the real-world problem of learning to navigate and interact with web pages. We learn to generate environments composed of multiple pages or rooms, and train RL agents capable of completing wide-range of complex tasks in those environments. We contribute two new benchmark frameworks for generating compositional tasks, compositional MiniGrid and gMiniWoB for web navigation.CoDE yields 4x higher success rate than the strongest baseline, and demonstrates strong performance of real websites learned on 3500 primitive tasks.
Automated Reinforcement Learning (AutoRL): A Survey and Open Problems
Jan 11, 2022
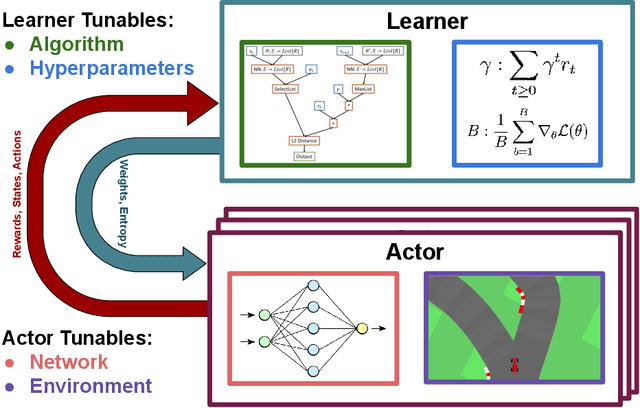
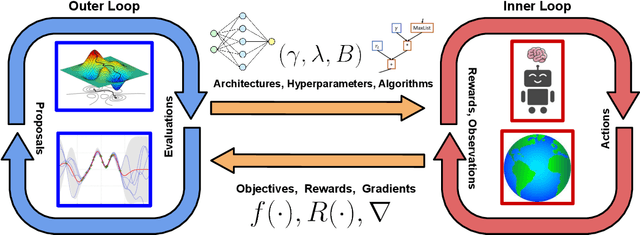

The combination of Reinforcement Learning (RL) with deep learning has led to a series of impressive feats, with many believing (deep) RL provides a path towards generally capable agents. However, the success of RL agents is often highly sensitive to design choices in the training process, which may require tedious and error-prone manual tuning. This makes it challenging to use RL for new problems, while also limits its full potential. In many other areas of machine learning, AutoML has shown it is possible to automate such design choices and has also yielded promising initial results when applied to RL. However, Automated Reinforcement Learning (AutoRL) involves not only standard applications of AutoML but also includes additional challenges unique to RL, that naturally produce a different set of methods. As such, AutoRL has been emerging as an important area of research in RL, providing promise in a variety of applications from RNA design to playing games such as Go. Given the diversity of methods and environments considered in RL, much of the research has been conducted in distinct subfields, ranging from meta-learning to evolution. In this survey we seek to unify the field of AutoRL, we provide a common taxonomy, discuss each area in detail and pose open problems which would be of interest to researchers going forward.
Visual Learning-based Planning for Continuous High-Dimensional POMDPs
Dec 17, 2021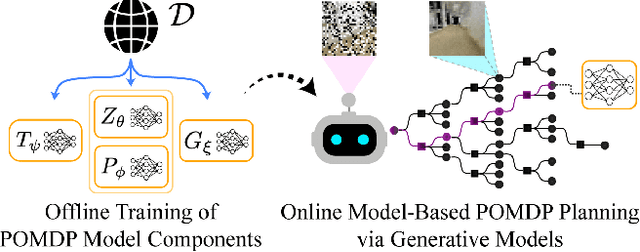
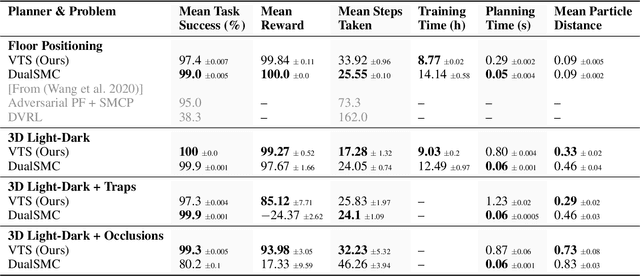
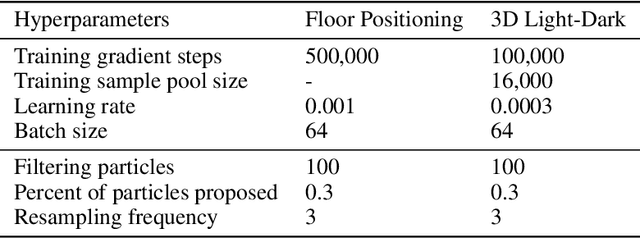
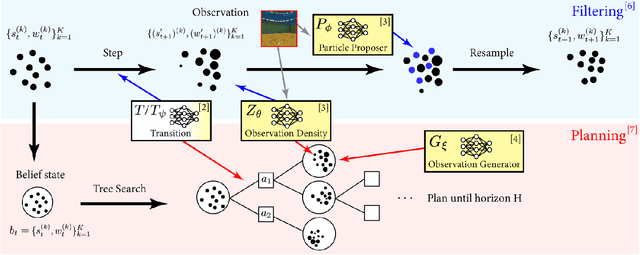
The Partially Observable Markov Decision Process (POMDP) is a powerful framework for capturing decision-making problems that involve state and transition uncertainty. However, most current POMDP planners cannot effectively handle very high-dimensional observations they often encounter in the real world (e.g. image observations in robotic domains). In this work, we propose Visual Tree Search (VTS), a learning and planning procedure that combines generative models learned offline with online model-based POMDP planning. VTS bridges offline model training and online planning by utilizing a set of deep generative observation models to predict and evaluate the likelihood of image observations in a Monte Carlo tree search planner. We show that VTS is robust to different observation noises and, since it utilizes online, model-based planning, can adapt to different reward structures without the need to re-train. This new approach outperforms a baseline state-of-the-art on-policy planning algorithm while using significantly less offline training time.
Less is More: Generating Grounded Navigation Instructions from Landmarks
Nov 29, 2021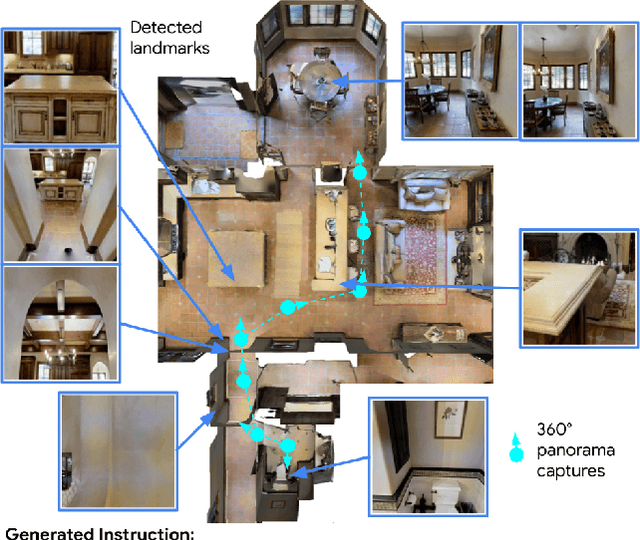
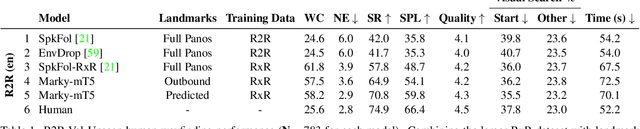


We study the automatic generation of navigation instructions from 360-degree images captured on indoor routes. Existing generators suffer from poor visual grounding, causing them to rely on language priors and hallucinate objects. Our MARKY-MT5 system addresses this by focusing on visual landmarks; it comprises a first stage landmark detector and a second stage generator -- a multimodal, multilingual, multitask encoder-decoder. To train it, we bootstrap grounded landmark annotations on top of the Room-across-Room (RxR) dataset. Using text parsers, weak supervision from RxR's pose traces, and a multilingual image-text encoder trained on 1.8b images, we identify 1.1m English, Hindi and Telugu landmark descriptions and ground them to specific regions in panoramas. On Room-to-Room, human wayfinders obtain success rates (SR) of 71% following MARKY-MT5's instructions, just shy of their 75% SR following human instructions -- and well above SRs with other generators. Evaluations on RxR's longer, diverse paths obtain 61-64% SRs on three languages. Generating such high-quality navigation instructions in novel environments is a step towards conversational navigation tools and could facilitate larger-scale training of instruction-following agents.
Roofline Model for UAVs:A Bottleneck Analysis Tool for Designing Compute Systems for Autonomous Drones
Nov 13, 2021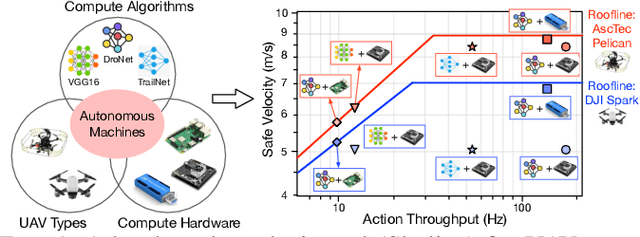
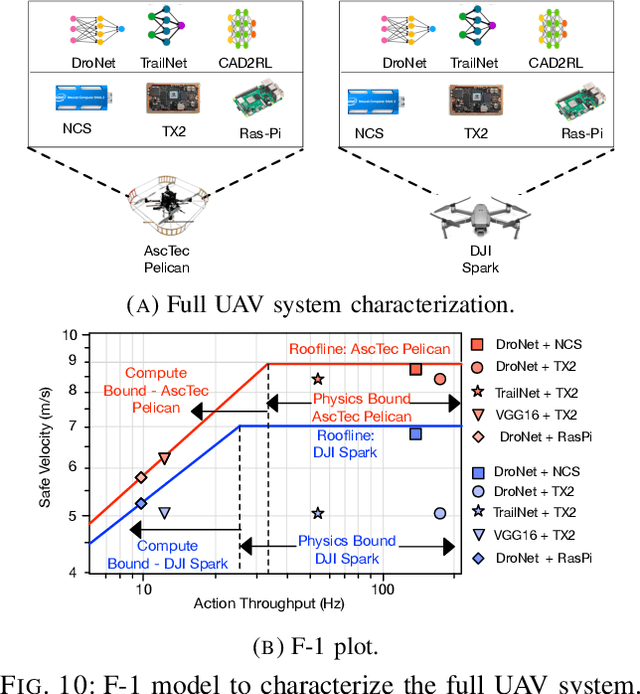


We present a bottleneck analysis tool for designing compute systems for autonomous Unmanned Aerial Vehicles (UAV). The tool provides insights by exploiting the fundamental relationships between various components in the autonomous UAV such as sensor, compute, body dynamics. To guarantee safe operation while maximizing the performance (e.g., velocity) of the UAV, the compute, sensor, and other mechanical properties must be carefully designed (or selected). The goal of our proposed tool is to provide a visual model which aids system architects to understand optimal compute design (or selection) for autonomous UAVs. The tool is available here:~\url{https://bit.ly/skyline-tool}
Multi-Task Learning with Sequence-Conditioned Transporter Networks
Sep 15, 2021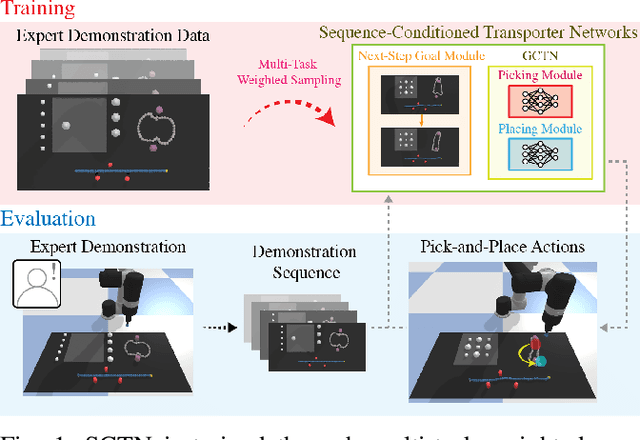
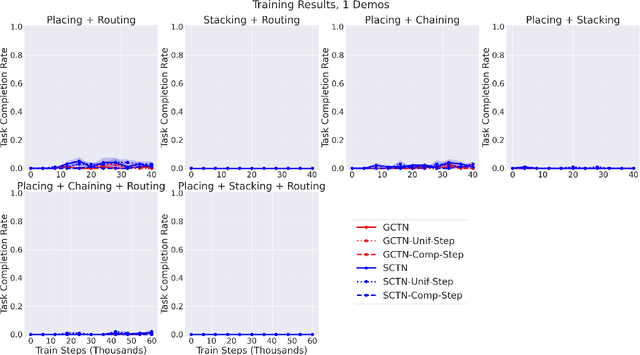
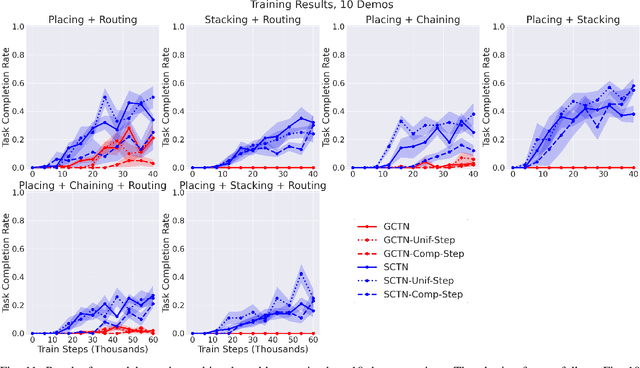
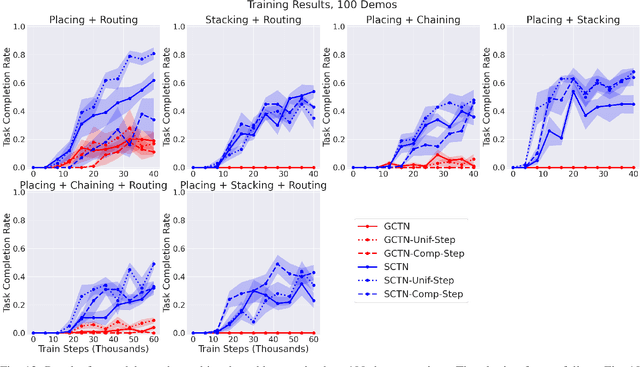
Enabling robots to solve multiple manipulation tasks has a wide range of industrial applications. While learning-based approaches enjoy flexibility and generalizability, scaling these approaches to solve such compositional tasks remains a challenge. In this work, we aim to solve multi-task learning through the lens of sequence-conditioning and weighted sampling. First, we propose a new suite of benchmark specifically aimed at compositional tasks, MultiRavens, which allows defining custom task combinations through task modules that are inspired by industrial tasks and exemplify the difficulties in vision-based learning and planning methods. Second, we propose a vision-based end-to-end system architecture, Sequence-Conditioned Transporter Networks, which augments Goal-Conditioned Transporter Networks with sequence-conditioning and weighted sampling and can efficiently learn to solve multi-task long horizon problems. Our analysis suggests that not only the new framework significantly improves pick-and-place performance on novel 10 multi-task benchmark problems, but also the multi-task learning with weighted sampling can vastly improve learning and agent performances on individual tasks.