 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous-Time Gaussian Belief Trees for Motion Planning
Jul 03, 2026We address sampling-based motion planning for continuous-time stochastic systems under process and measurement uncertainty, with probabilistic guarantees on safety and performance. The robot dynamics are modeled as a continuous-time linear stochastic differential equation, while sensor measurements arrive at discrete time instants. We derive an offline hybrid belief propagation model in which the belief evolves according to continuous-time ODEs between measurements and undergoes discrete Kalman filter update jumps at measurement times. To ensure safety, we introduce a belief-barrier-function-based safety checker for segment-level probabilistic verification. This enables the planner to certify safety over entire continuous trajectory segments and detect inter-sample chance-constraint violations that are missed by conventional node-based checks. Together, these components provide a principled framework for sampling-based belief planning that accounts for both continuous-time uncertainty propagation and continuous-time safety requirements. We integrate the method with RRT and SST planners and evaluate it across multiple benchmark environments. The results show that the proposed method achieves high success rates and robust enforcement of chance constraints, including in narrow-passage scenarios where discrete-time counterparts fail due to missed inter-sample unsafe behavior.
Sampling-based Task and Kinodynamic Motion Planning under Semantic Uncertainty
Apr 01, 2026This paper tackles the problem of integrated task and kinodynamic motion planning in uncertain environments. We consider a robot with nonlinear dynamics tasked with a Linear Temporal Logic over finite traces ($\ltlf$) specification operating in a partially observable environment. Specifically, the uncertainty is in the semantic labels of the environment. We show how the problem can be modeled as a Partially Observable Stochastic Hybrid System that captures the robot dynamics, $\ltlf$ task, and uncertainty in the environment state variables. We propose an anytime algorithm that takes advantage of the structure of the hybrid system, and combines the effectiveness of decision-making techniques and sampling-based motion planning. We prove the soundness and asymptotic optimality of the algorithm. Results show the efficacy of our algorithm in uncertain environments, and that it consistently outperforms baseline methods.
Resolving Multiple-Dynamic Model Uncertainty in Hypothesis-Driven Belief-MDPs
Nov 21, 2024



When human operators of cyber-physical systems encounter surprising behavior, they often consider multiple hypotheses that might explain it. In some cases, taking information-gathering actions such as additional measurements or control inputs given to the system can help resolve uncertainty and determine the most accurate hypothesis. The task of optimizing these actions can be formulated as a belief-space Markov decision process that we call a hypothesis-driven belief MDP. Unfortunately, this problem suffers from the curse of history similar to a partially observable Markov decision process (POMDP). To plan in continuous domains, an agent needs to reason over countlessly many possible action-observation histories, each resulting in a different belief over the unknown state. The problem is exacerbated in the hypothesis-driven context because each action-observation pair spawns a different belief for each hypothesis, leading to additional branching. This paper considers the case in which each hypothesis corresponds to a different dynamic model in an underlying POMDP. We present a new belief MDP formulation that: (i) enables reasoning over multiple hypotheses, (ii) balances the goals of determining the (most likely) correct hypothesis and performing well in the underlying POMDP, and (iii) can be solved with sparse tree search.
Rao-Blackwellized POMDP Planning
Sep 24, 2024



Partially Observable Markov Decision Processes (POMDPs) provide a structured framework for decision-making under uncertainty, but their application requires efficient belief updates. Sequential Importance Resampling Particle Filters (SIRPF), also known as Bootstrap Particle Filters, are commonly used as belief updaters in large approximate POMDP solvers, but they face challenges such as particle deprivation and high computational costs as the system's state dimension grows. To address these issues, this study introduces Rao-Blackwellized POMDP (RB-POMDP) approximate solvers and outlines generic methods to apply Rao-Blackwellization in both belief updates and online planning. We compare the performance of SIRPF and Rao-Blackwellized Particle Filters (RBPF) in a simulated localization problem where an agent navigates toward a target in a GPS-denied environment using POMCPOW and RB-POMCPOW planners. Our results not only confirm that RBPFs maintain accurate belief approximations over time with fewer particles, but, more surprisingly, RBPFs combined with quadrature-based integration improve planning quality significantly compared to SIRPF-based planning under the same computational limits.
Sound Heuristic Search Value Iteration for Undiscounted POMDPs with Reachability Objectives
Jun 05, 2024



Partially Observable Markov Decision Processes (POMDPs) are powerful models for sequential decision making under transition and observation uncertainties. This paper studies the challenging yet important problem in POMDPs known as the (indefinite-horizon) Maximal Reachability Probability Problem (MRPP), where the goal is to maximize the probability of reaching some target states. This is also a core problem in model checking with logical specifications and is naturally undiscounted (discount factor is one). Inspired by the success of point-based methods developed for discounted problems, we study their extensions to MRPP. Specifically, we focus on trial-based heuristic search value iteration techniques and present a novel algorithm that leverages the strengths of these techniques for efficient exploration of the belief space (informed search via value bounds) while addressing their drawbacks in handling loops for indefinite-horizon problems. The algorithm produces policies with two-sided bounds on optimal reachability probabilities. We prove convergence to an optimal policy from below under certain conditions. Experimental evaluations on a suite of benchmarks show that our algorithm outperforms existing methods in almost all cases in both probability guarantees and computation time.
Cieran: Designing Sequential Colormaps via In-Situ Active Preference Learning
Feb 29, 2024



Quality colormaps can help communicate important data patterns. However, finding an aesthetically pleasing colormap that looks "just right" for a given scenario requires significant design and technical expertise. We introduce Cieran, a tool that allows any data analyst to rapidly find quality colormaps while designing charts within Jupyter Notebooks. Our system employs an active preference learning paradigm to rank expert-designed colormaps and create new ones from pairwise comparisons, allowing analysts who are novices in color design to tailor colormaps to their data context. We accomplish this by treating colormap design as a path planning problem through the CIELAB colorspace with a context-specific reward model. In an evaluation with twelve scientists, we found that Cieran effectively modeled user preferences to rank colormaps and leveraged this model to create new quality designs. Our work shows the potential of active preference learning for supporting efficient visualization design optimization.
Recursively-Constrained Partially Observable Markov Decision Processes
Oct 15, 2023



In many problems, it is desirable to optimize an objective function while imposing constraints on some other aspect of the problem. A Constrained Partially Observable Markov Decision Process (C-POMDP) allows modelling of such problems while subject to transition uncertainty and partial observability. Typically, the constraints in C-POMDPs enforce a threshold on expected cumulative costs starting from an initial state distribution. In this work, we first show that optimal C-POMDP policies may violate Bellman's principle of optimality and thus may exhibit pathological behaviors, which can be undesirable for many applications. To address this drawback, we introduce a new formulation, the Recursively-Constrained POMDP (RC-POMDP), that imposes additional history dependent cost constraints on the C-POMDP. We show that, unlike C-POMDPs, RC-POMDPs always have deterministic optimal policies, and that optimal policies obey Bellman's principle of optimality. We also present a point-based dynamic programming algorithm that synthesizes optimal policies for RC-POMDPs. In our evaluations, we show that policies for RC-POMDPs produce more desirable behavior than policies for C-POMDPs and demonstrate the efficacy of our algorithm across a set of benchmark problems.
Explanation through Reward Model Reconciliation using POMDP Tree Search
May 01, 2023

As artificial intelligence (AI) algorithms are increasingly used in mission-critical applications, promoting user-trust of these systems will be essential to their success. Ensuring users understand the models over which algorithms reason promotes user trust. This work seeks to reconcile differences between the reward model that an algorithm uses for online partially observable Markov decision (POMDP) planning and the implicit reward model assumed by a human user. Action discrepancies, differences in decisions made by an algorithm and user, are leveraged to estimate a user's objectives as expressed in weightings of a reward function.
Sampling-based Reactive Synthesis for Nondeterministic Hybrid Systems
Apr 14, 2023



This paper introduces a sampling-based strategy synthesis algorithm for nondeterministic hybrid systems with complex continuous dynamics under temporal and reachability constraints. We view the evolution of the hybrid system as a two-player game, where the nondeterminism is an adversarial player whose objective is to prevent achieving temporal and reachability goals. The aim is to synthesize a winning strategy -- a reactive (robust) strategy that guarantees the satisfaction of the goals under all possible moves of the adversarial player. The approach is based on growing a (search) game-tree in the hybrid space by combining a sampling-based planning method with a novel bandit-based technique to select and improve on partial strategies. We provide conditions under which the algorithm is probabilistically complete, i.e., if a winning strategy exists, the algorithm will almost surely find it. The case studies and benchmark results show that the algorithm is general and consistently outperforms the state of the art.
Planning with SiMBA: Motion Planning under Uncertainty for Temporal Goals using Simplified Belief Guides
Oct 18, 2022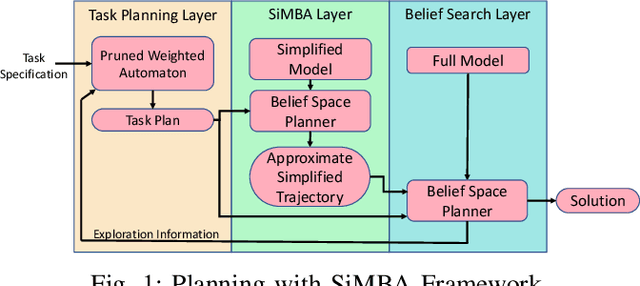
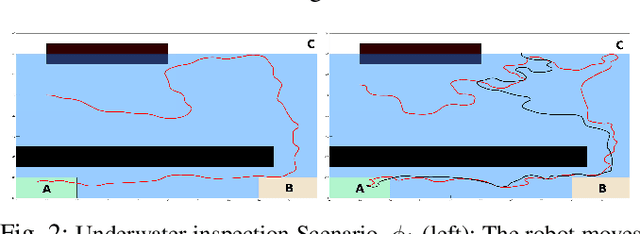
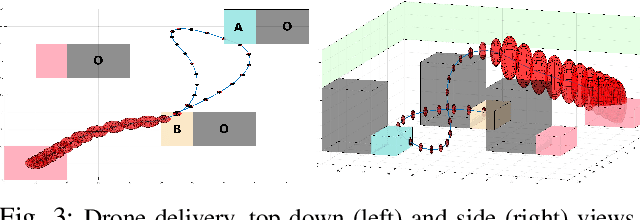

This paper presents a new multi-layered algorithm for motion planning under motion and sensing uncertainties for Linear Temporal Logic specifications. We propose a technique to guide a sampling-based search tree in the combined task and belief space using trajectories from a simplified model of the system, to make the problem computationally tractable. Our method eliminates the need to construct fine and accurate finite abstractions. We prove correctness and probabilistic completeness of our algorithm, and illustrate the benefits of our approach on several case studies. Our results show that guidance with a simplified belief space model allows for significant speed-up in planning for complex specifications.