 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Self-Play and Scale: A Behavior Benchmark for Generalization in Autonomous Driving
May 11, 2026Recent Autonomous Driving (AD) works such as GigaFlow and PufferDrive have unlocked Reinforcement Learning (RL) at scale as a training strategy for driving policies. Yet such policies remain disconnected from established benchmarks, leaving the performance of large-scale RL for driving on standardized evaluations unknown. We present BehaviorBench -- a comprehensive test suite that closes this gap along three axes: Evaluation, Complexity, and Behavior Diversity. In terms of Evaluation, we provide an interface connecting PufferDrive to nuPlan, which, for the first time, enables policies trained via RL at scale to be evaluated on an established planning benchmark for autonomous driving. Complementarily, we offer an evaluation framework that allows planners to be benchmarked directly inside the PufferDrive simulation, at a fraction of the time. Regarding Complexity, we observe that today's standardized benchmarks are so simple that near-perfect scores are achievable by straight lane following with collision checking. We extract a meaningful, interaction-rich split from the Waymo Open Motion Dataset (WOMD) on which strong performance is impossible without multi-agent reasoning. Lastly, we address Behavior Diversity. Existing benchmarks commonly evaluate planners against a single rule-based traffic model, the Intelligent Driver Model (IDM). We provide a diverse suite of interactive traffic agents to stress-test policies under heterogeneous behaviors, beyond just using IDM. Overall, our benchmarking analysis uncovers the following insight: despite learning interactive behaviors in an emergent manner, policies trained via pure self-play under standard reward functions overfit to their training opponents and fail to generalize to other traffic agent behaviors. Building on this observation, we propose a hybrid planner that combines a PPO policy with a rule-based planner.
Super Agents and Confounders: Influence of surrounding agents on vehicle trajectory prediction
Apr 03, 2026In highly interactive driving scenes, trajectory prediction is conditioned on information from surrounding traffic participants such as cars and pedestrians. Our main contribution is a comprehensive analysis of state-of-the-art trajectory predictors, which reveals a surprising and critical flaw: many surrounding agents degrade prediction accuracy rather than improve it. Using Shapley-based attribution, we rigorously demonstrate that models learn unstable and non-causal decision-making schemes that vary significantly across training runs. Building on these insights, we propose to integrate a Conditional Information Bottleneck (CIB), which does not require additional supervision and is trained to effectively compress agent features as well as ignore those that are not beneficial for the prediction task. Comprehensive experiments using multiple datasets and model architectures demonstrate that this simple yet effective approach not only improves overall trajectory prediction performance in many cases but also increases robustness to different perturbations. Our results highlight the importance of selectively integrating contextual information, which can often contain spurious or misleading signals, in trajectory prediction. Moreover, we provide interpretable metrics for identifying non-robust behavior and present a promising avenue towards a solution.
Don't double it: Efficient Agent Prediction in Occlusions
Jan 29, 2026Occluded traffic agents pose a significant challenge for autonomous vehicles, as hidden pedestrians or vehicles can appear unexpectedly, yet this problem remains understudied. Existing learning-based methods, while capable of inferring the presence of hidden agents, often produce redundant occupancy predictions where a single agent is identified multiple times. This issue complicates downstream planning and increases computational load. To address this, we introduce MatchInformer, a novel transformer-based approach that builds on the state-of-the-art SceneInformer architecture. Our method improves upon prior work by integrating Hungarian Matching, a state-of-the-art object matching algorithm from object detection, into the training process to enforce a one-to-one correspondence between predictions and ground truth, thereby reducing redundancy. We further refine trajectory forecasts by decoupling an agent's heading from its motion, a strategy that improves the accuracy and interpretability of predicted paths. To better handle class imbalances, we propose using the Matthews Correlation Coefficient (MCC) to evaluate occupancy predictions. By considering all entries in the confusion matrix, MCC provides a robust measure even in sparse or imbalanced scenarios. Experiments on the Waymo Open Motion Dataset demonstrate that our approach improves reasoning about occluded regions and produces more accurate trajectory forecasts than prior methods.
ARLBench: Flexible and Efficient Benchmarking for Hyperparameter Optimization in Reinforcement Learning
Sep 27, 2024



Hyperparameters are a critical factor in reliably training well-performing reinforcement learning (RL) agents. Unfortunately, developing and evaluating automated approaches for tuning such hyperparameters is both costly and time-consuming. As a result, such approaches are often only evaluated on a single domain or algorithm, making comparisons difficult and limiting insights into their generalizability. We propose ARLBench, a benchmark for hyperparameter optimization (HPO) in RL that allows comparisons of diverse HPO approaches while being highly efficient in evaluation. To enable research into HPO in RL, even in settings with low compute resources, we select a representative subset of HPO tasks spanning a variety of algorithm and environment combinations. This selection allows for generating a performance profile of an automated RL (AutoRL) method using only a fraction of the compute previously necessary, enabling a broader range of researchers to work on HPO in RL. With the extensive and large-scale dataset on hyperparameter landscapes that our selection is based on, ARLBench is an efficient, flexible, and future-oriented foundation for research on AutoRL. Both the benchmark and the dataset are available at https://github.com/automl/arlbench.
* Accepted at the 17th European Workshop on Reinforcement Learning
One-shot World Models Using a Transformer Trained on a Synthetic Prior
Sep 21, 2024



A World Model is a compressed spatial and temporal representation of a real world environment that allows one to train an agent or execute planning methods. However, world models are typically trained on observations from the real world environment, and they usually do not enable learning policies for other real environments. We propose One-Shot World Model (OSWM), a transformer world model that is learned in an in-context learning fashion from purely synthetic data sampled from a prior distribution. Our prior is composed of multiple randomly initialized neural networks, where each network models the dynamics of each state and reward dimension of a desired target environment. We adopt the supervised learning procedure of Prior-Fitted Networks by masking next-state and reward at random context positions and query OSWM to make probabilistic predictions based on the remaining transition context. During inference time, OSWM is able to quickly adapt to the dynamics of a simple grid world, as well as the CartPole gym and a custom control environment by providing 1k transition steps as context and is then able to successfully train environment-solving agent policies. However, transferring to more complex environments remains a challenge, currently. Despite these limitations, we see this work as an important stepping-stone in the pursuit of learning world models purely from synthetic data.
Dreaming of Many Worlds: Learning Contextual World Models Aids Zero-Shot Generalization
Mar 16, 2024



Zero-shot generalization (ZSG) to unseen dynamics is a major challenge for creating generally capable embodied agents. To address the broader challenge, we start with the simpler setting of contextual reinforcement learning (cRL), assuming observability of the context values that parameterize the variation in the system's dynamics, such as the mass or dimensions of a robot, without making further simplifying assumptions about the observability of the Markovian state. Toward the goal of ZSG to unseen variation in context, we propose the contextual recurrent state-space model (cRSSM), which introduces changes to the world model of the Dreamer (v3) (Hafner et al., 2023). This allows the world model to incorporate context for inferring latent Markovian states from the observations and modeling the latent dynamics. Our experiments show that such systematic incorporation of the context improves the ZSG of the policies trained on the ``dreams'' of the world model. We further find qualitatively that our approach allows Dreamer to disentangle the latent state from context, allowing it to extrapolate its dreams to the many worlds of unseen contexts. The code for all our experiments is available at \url{https://github.com/sai-prasanna/dreaming_of_many_worlds}.
T3VIP: Transformation-based 3D Video Prediction
Sep 19, 2022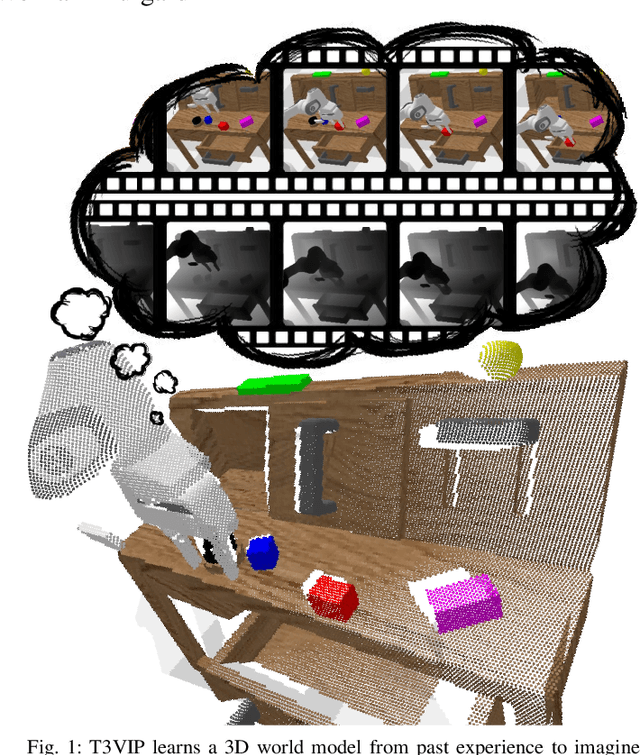
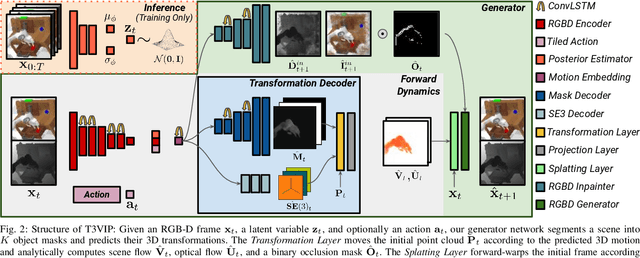
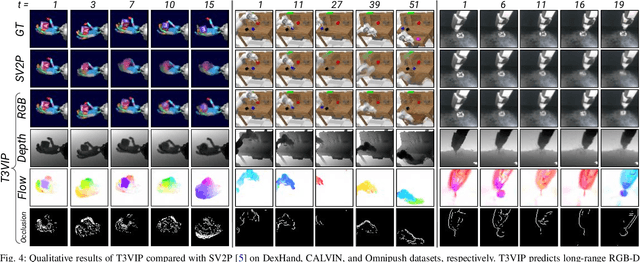
For autonomous skill acquisition, robots have to learn about the physical rules governing the 3D world dynamics from their own past experience to predict and reason about plausible future outcomes. To this end, we propose a transformation-based 3D video prediction (T3VIP) approach that explicitly models the 3D motion by decomposing a scene into its object parts and predicting their corresponding rigid transformations. Our model is fully unsupervised, captures the stochastic nature of the real world, and the observational cues in image and point cloud domains constitute its learning signals. To fully leverage all the 2D and 3D observational signals, we equip our model with automatic hyperparameter optimization (HPO) to interpret the best way of learning from them. To the best of our knowledge, our model is the first generative model that provides an RGB-D video prediction of the future for a static camera. Our extensive evaluation with simulated and real-world datasets demonstrates that our formulation leads to interpretable 3D models that predict future depth videos while achieving on-par performance with 2D models on RGB video prediction. Moreover, we demonstrate that our model outperforms 2D baselines on visuomotor control. Videos, code, dataset, and pre-trained models are available at http://t3vip.cs.uni-freiburg.de.
Automated Reinforcement Learning (AutoRL): A Survey and Open Problems
Jan 11, 2022
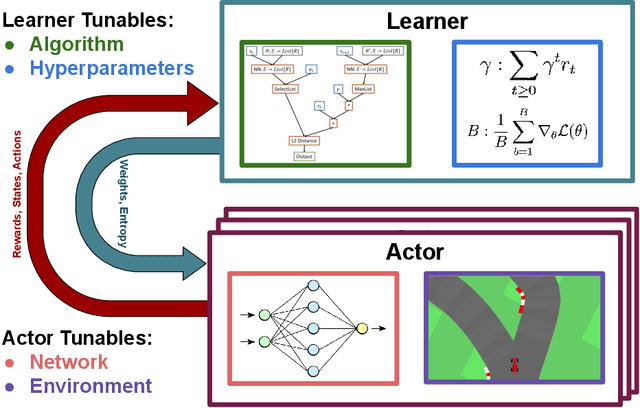
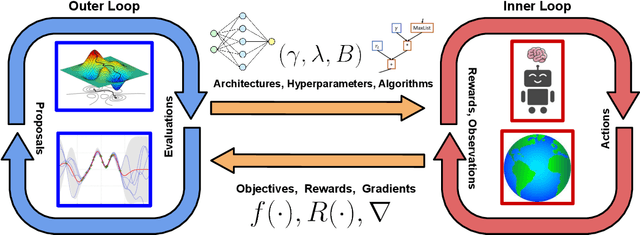

The combination of Reinforcement Learning (RL) with deep learning has led to a series of impressive feats, with many believing (deep) RL provides a path towards generally capable agents. However, the success of RL agents is often highly sensitive to design choices in the training process, which may require tedious and error-prone manual tuning. This makes it challenging to use RL for new problems, while also limits its full potential. In many other areas of machine learning, AutoML has shown it is possible to automate such design choices and has also yielded promising initial results when applied to RL. However, Automated Reinforcement Learning (AutoRL) involves not only standard applications of AutoML but also includes additional challenges unique to RL, that naturally produce a different set of methods. As such, AutoRL has been emerging as an important area of research in RL, providing promise in a variety of applications from RNA design to playing games such as Go. Given the diversity of methods and environments considered in RL, much of the research has been conducted in distinct subfields, ranging from meta-learning to evolution. In this survey we seek to unify the field of AutoRL, we provide a common taxonomy, discuss each area in detail and pose open problems which would be of interest to researchers going forward.
TempoRL: Learning When to Act
Jun 09, 2021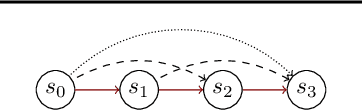

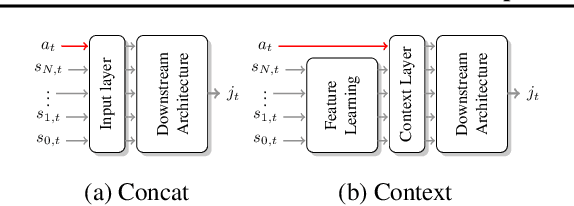

Reinforcement learning is a powerful approach to learn behaviour through interactions with an environment. However, behaviours are usually learned in a purely reactive fashion, where an appropriate action is selected based on an observation. In this form, it is challenging to learn when it is necessary to execute new decisions. This makes learning inefficient, especially in environments that need various degrees of fine and coarse control. To address this, we propose a proactive setting in which the agent not only selects an action in a state but also for how long to commit to that action. Our TempoRL approach introduces skip connections between states and learns a skip-policy for repeating the same action along these skips. We demonstrate the effectiveness of TempoRL on a variety of traditional and deep RL environments, showing that our approach is capable of learning successful policies up to an order of magnitude faster than vanilla Q-learning.
On the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
Feb 26, 2021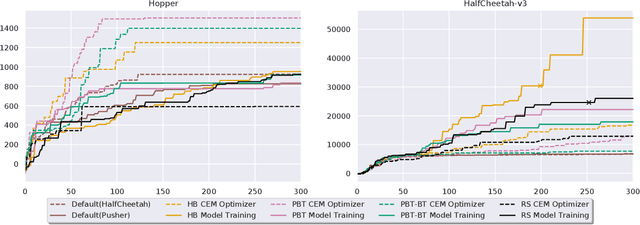
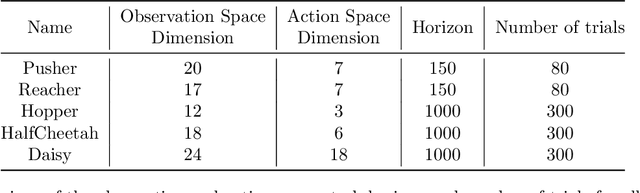
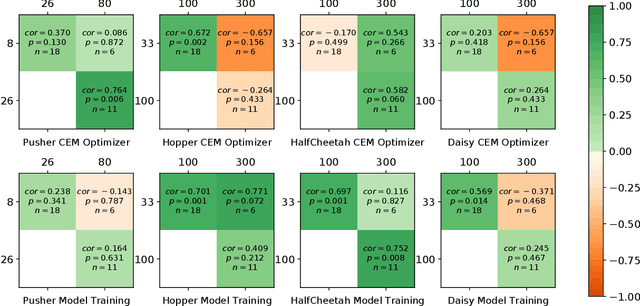
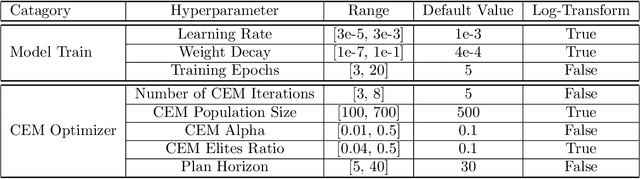
Model-based Reinforcement Learning (MBRL) is a promising framework for learning control in a data-efficient manner. MBRL algorithms can be fairly complex due to the separate dynamics modeling and the subsequent planning algorithm, and as a result, they often possess tens of hyperparameters and architectural choices. For this reason, MBRL typically requires significant human expertise before it can be applied to new problems and domains. To alleviate this problem, we propose to use automatic hyperparameter optimization (HPO). We demonstrate that this problem can be tackled effectively with automated HPO, which we demonstrate to yield significantly improved performance compared to human experts. In addition, we show that tuning of several MBRL hyperparameters dynamically, i.e. during the training itself, further improves the performance compared to using static hyperparameters which are kept fixed for the whole training. Finally, our experiments provide valuable insights into the effects of several hyperparameters, such as plan horizon or learning rate and their influence on the stability of training and resulting rewards.