 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Temporal Information Help with Contrastive Self-Supervised Learning?
Nov 25, 2020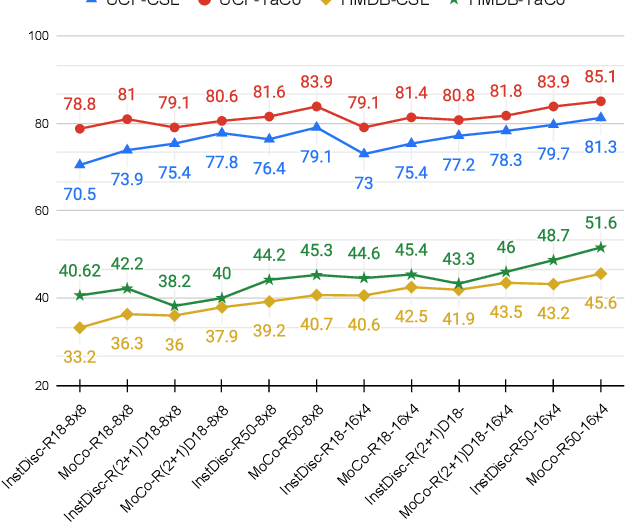
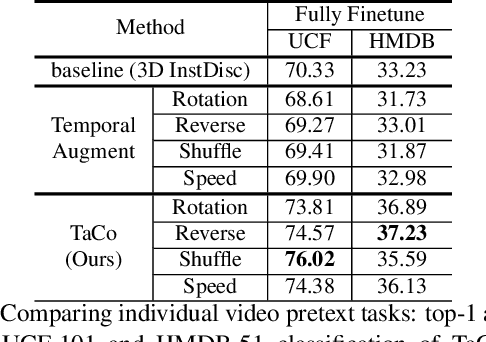
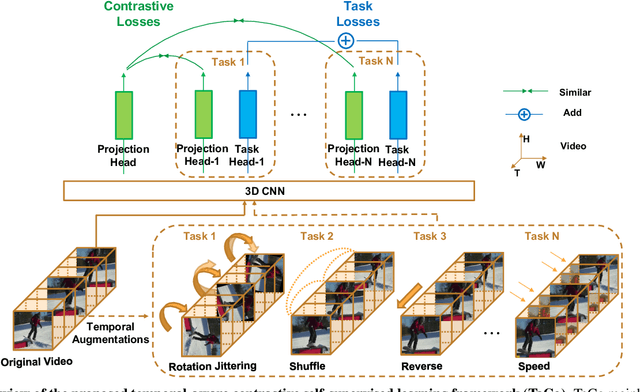
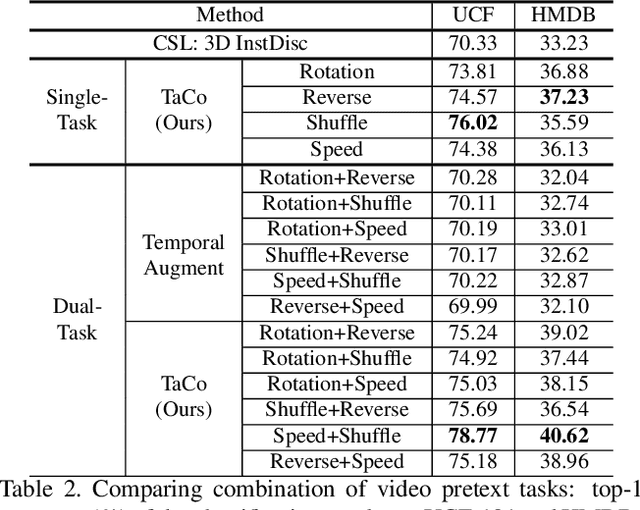
Leveraging temporal information has been regarded as essential for developing video understanding models. However, how to properly incorporate temporal information into the recent successful instance discrimination based contrastive self-supervised learning (CSL) framework remains unclear. As an intuitive solution, we find that directly applying temporal augmentations does not help, or even impair video CSL in general. This counter-intuitive observation motivates us to re-design existing video CSL frameworks, for better integration of temporal knowledge. To this end, we present Temporal-aware Contrastive self-supervised learningTaCo, as a general paradigm to enhance video CSL. Specifically, TaCo selects a set of temporal transformations not only as strong data augmentation but also to constitute extra self-supervision for video understanding. By jointly contrasting instances with enriched temporal transformations and learning these transformations as self-supervised signals, TaCo can significantly enhance unsupervised video representation learning. For instance, TaCo demonstrates consistent improvement in downstream classification tasks over a list of backbones and CSL approaches. Our best model achieves 85.1% (UCF-101) and 51.6% (HMDB-51) top-1 accuracy, which is a 3% and 2.4% relative improvement over the previous state-of-the-art.
Weakly-Supervised Amodal Instance Segmentation with Compositional Priors
Oct 25, 2020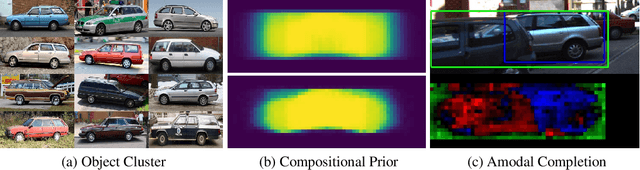


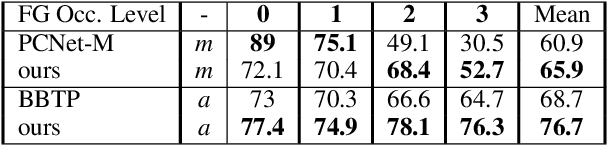
Amodal segmentation in biological vision refers to the perception of the entire object when only a fraction is visible. This ability of seeing through occluders and reasoning about occlusion is innate to biological vision but not adequately modeled in current machine vision approaches. A key challenge is that ground-truth supervisions of amodal object segmentation are inherently difficult to obtain. In this paper, we present a neural network architecture that is capable of amodal perception, when weakly supervised with standard (inmodal) bounding box annotations. Our model extends compositional convolutional neural networks (CompositionalNets), which have been shown to be robust to partial occlusion by explicitly representing objects as composition of parts. In particular, we extend CompositionalNets by: 1) Expanding the innate part-voting mechanism in the CompositionalNets to perform instance segmentation; 2) and by exploiting the internal representations of CompositionalNets to enable amodal completion for both bounding box and segmentation mask. Our extensive experiments show that our proposed model can segment amodal masks robustly, with much improved mask prediction qualities compared to state-of-the-art amodal segmentation approaches.
Shape-Texture Debiased Neural Network Training
Oct 12, 2020

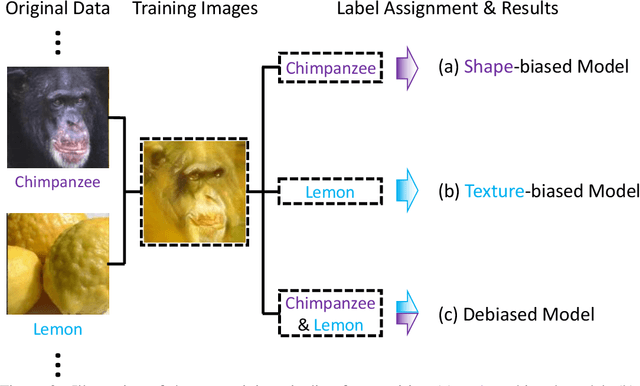
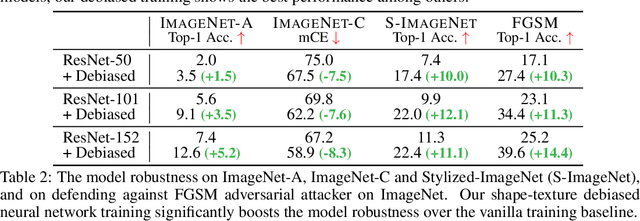
Shape and texture are two prominent and complementary cues for recognizing objects. Nonetheless, Convolutional Neural Networks are often biased towards either texture or shape, depending on the training dataset. Our ablation shows that such bias degenerates model performance. Motivated by this observation, we develop a simple algorithm for shape-texture debiased learning. To prevent models from exclusively attending on a single cue in representation learning, we augment training data with images with conflicting shape and texture information (e.g., an image of chimpanzee shape but with lemon texture) and, most importantly, provide the corresponding supervisions from shape and texture simultaneously. Experiments show that our method successfully improves model performance on several image recognition benchmarks and adversarial robustness. For example, by training on ImageNet, it helps ResNet-152 achieve substantial improvements on ImageNet (+1.2%), ImageNet-A (+5.2%), ImageNet-C (+8.3%) and Stylized-ImageNet (+11.1%), and on defending against FGSM adversarial attacker on ImageNet (+14.4%). Our method also claims to be compatible to other advanced data augmentation strategies, e.g., Mixup and CutMix. The code is available here: https://github.com/LiYingwei/ShapeTextureDebiasedTraining.
CO2: Consistent Contrast for Unsupervised Visual Representation Learning
Oct 05, 2020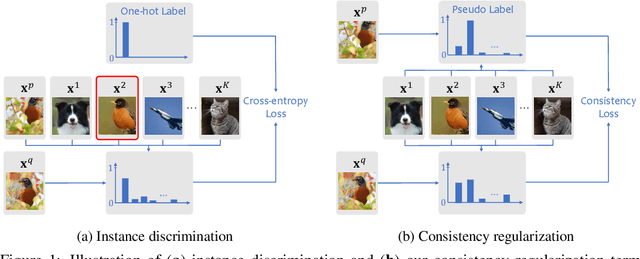
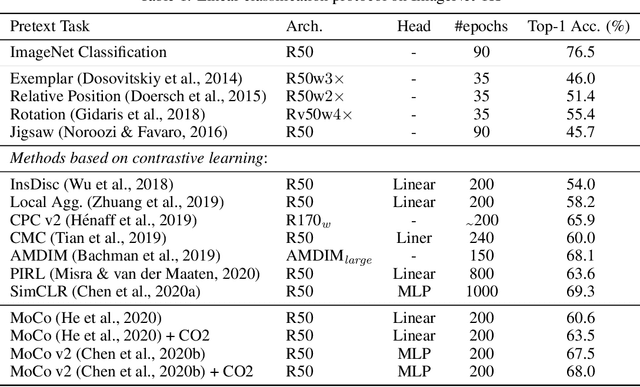
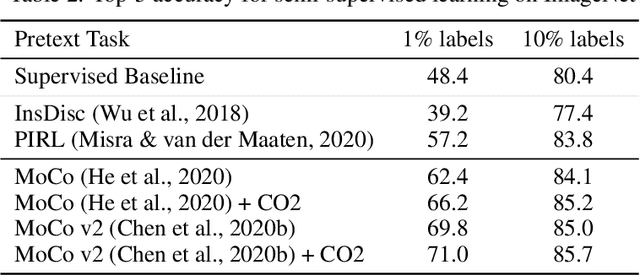
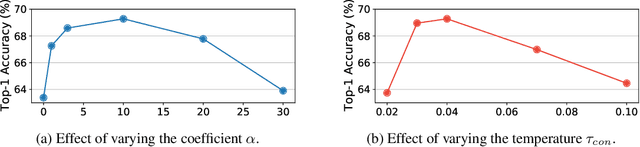
Contrastive learning has been adopted as a core method for unsupervised visual representation learning. Without human annotation, the common practice is to perform an instance discrimination task: Given a query image crop, this task labels crops from the same image as positives, and crops from other randomly sampled images as negatives. An important limitation of this label assignment strategy is that it can not reflect the heterogeneous similarity between the query crop and each crop from other images, taking them as equally negative, while some of them may even belong to the same semantic class as the query. To address this issue, inspired by consistency regularization in semi-supervised learning on unlabeled data, we propose Consistent Contrast (CO2), which introduces a consistency regularization term into the current contrastive learning framework. Regarding the similarity of the query crop to each crop from other images as "unlabeled", the consistency term takes the corresponding similarity of a positive crop as a pseudo label, and encourages consistency between these two similarities. Empirically, CO2 improves Momentum Contrast (MoCo) by 2.9% top-1 accuracy on ImageNet linear protocol, 3.8% and 1.1% top-5 accuracy on 1% and 10% labeled semi-supervised settings. It also transfers to image classification, object detection, and semantic segmentation on PASCAL VOC. This shows that CO2 learns better visual representations for these downstream tasks.
CoKe: Localized Contrastive Learning for Robust Keypoint Detection
Sep 30, 2020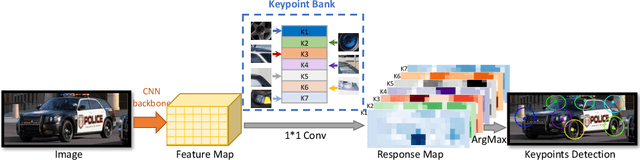
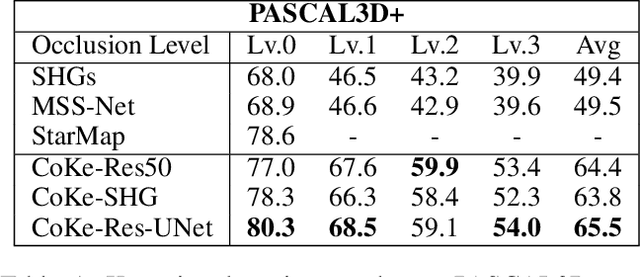
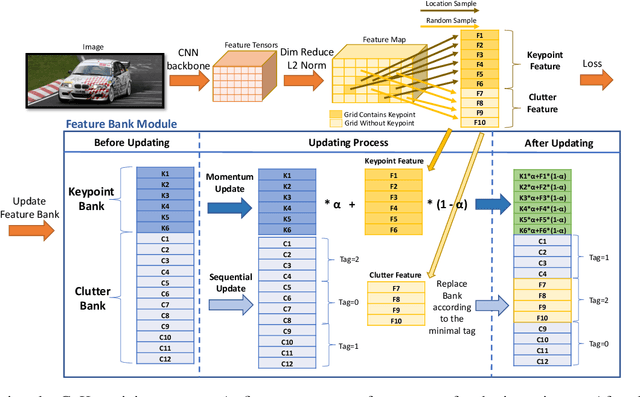
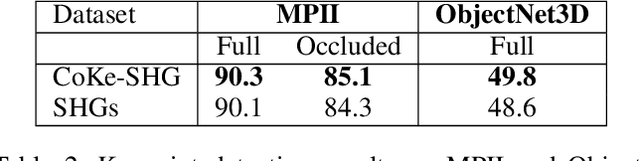
Today's most popular approaches to keypoint detection learn a holistic representation of all keypoints. This enables them to implicitly leverage the relative spatial geometry between keypoints and thus to prevent false-positive detections due to local ambiguities. However, our experiments show that such holistic representations do not generalize well when the 3D pose of objects varies strongly, or when objects are partially occluded. In this paper, we propose CoKe, a framework for the supervised contrastive learning of distinct local feature representations for robust keypoint detection. In particular, we introduce a feature bank mechanism and update rules for keypoint and non-keypoint features which make possible to learn local keypoint detectors that are accurate and robust to local ambiguities. Our experiments show that CoKe achieves state-of-the-art results compared to approaches that jointly represent all keypoints holistically (Stacked Hourglass Networks, MSS-Net) as well as to approaches that are supervised with the detailed 3D object geometry (StarMap). Notably, CoKe performs exceptionally well when objects are partially occluded and outperforms related work on a range of diverse datasets (PASCAL3D+, MPII, ObjectNet3D).
Lymph Node Gross Tumor Volume Detection in Oncology Imaging via Relationship Learning Using Graph Neural Network
Aug 29, 2020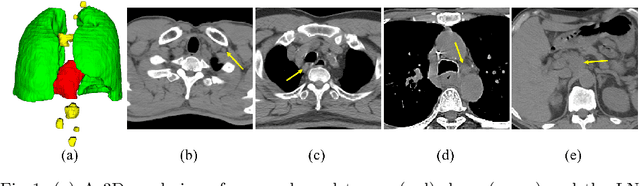
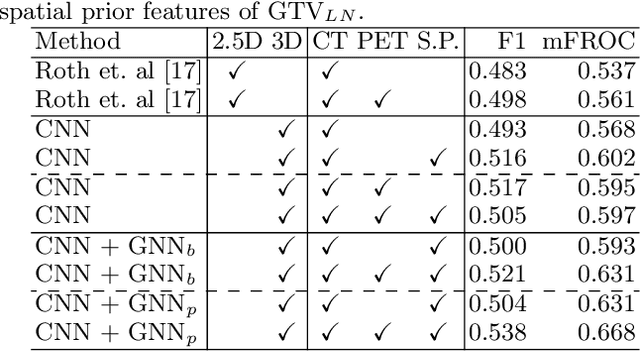
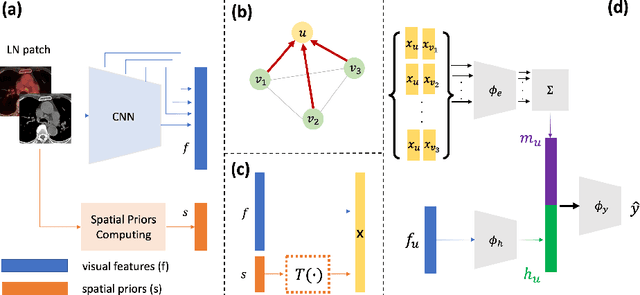
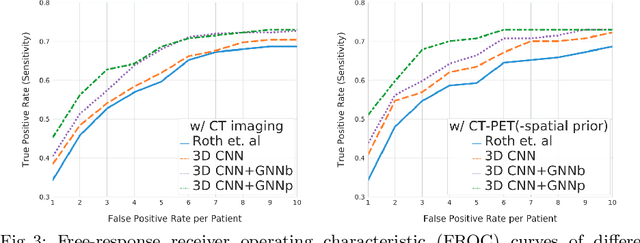
Determining the spread of GTV$_{LN}$ is essential in defining the respective resection or irradiating regions for the downstream workflows of surgical resection and radiotherapy for many cancers. Different from the more common enlarged lymph node (LN), GTV$_{LN}$ also includes smaller ones if associated with high positron emission tomography signals and/or any metastasis signs in CT. This is a daunting task. In this work, we propose a unified LN appearance and inter-LN relationship learning framework to detect the true GTV$_{LN}$. This is motivated by the prior clinical knowledge that LNs form a connected lymphatic system, and the spread of cancer cells among LNs often follows certain pathways. Specifically, we first utilize a 3D convolutional neural network with ROI-pooling to extract the GTV$_{LN}$'s instance-wise appearance features. Next, we introduce a graph neural network to further model the inter-LN relationships where the global LN-tumor spatial priors are included in the learning process. This leads to an end-to-end trainable network to detect by classifying GTV$_{LN}$. We operate our model on a set of GTV$_{LN}$ candidates generated by a preliminary 1st-stage method, which has a sensitivity of $>85\%$ at the cost of high false positive (FP) ($>15$ FPs per patient). We validate our approach on a radiotherapy dataset with 142 paired PET/RTCT scans containing the chest and upper abdominal body parts. The proposed method significantly improves over the state-of-the-art (SOTA) LN classification method by $5.5\%$ and $13.1\%$ in F1 score and the averaged sensitivity value at $2, 3, 4, 6$ FPs per patient, respectively.
Lymph Node Gross Tumor Volume Detection and Segmentation via Distance-based Gating using 3D CT/PET Imaging in Radiotherapy
Aug 27, 2020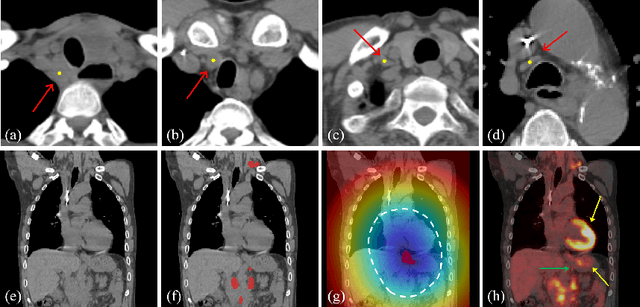
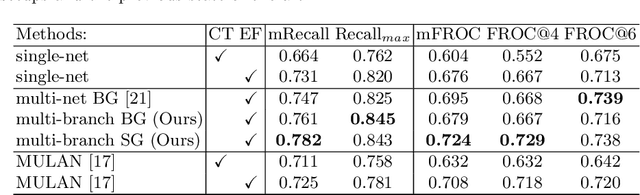
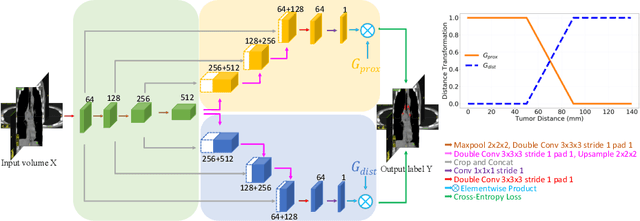
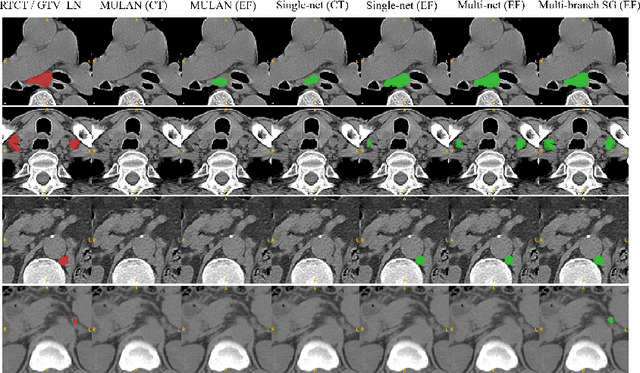
Finding, identifying and segmenting suspicious cancer metastasized lymph nodes from 3D multi-modality imaging is a clinical task of paramount importance. In radiotherapy, they are referred to as Lymph Node Gross Tumor Volume (GTVLN). Determining and delineating the spread of GTVLN is essential in defining the corresponding resection and irradiating regions for the downstream workflows of surgical resection and radiotherapy of various cancers. In this work, we propose an effective distance-based gating approach to simulate and simplify the high-level reasoning protocols conducted by radiation oncologists, in a divide-and-conquer manner. GTVLN is divided into two subgroups of tumor-proximal and tumor-distal, respectively, by means of binary or soft distance gating. This is motivated by the observation that each category can have distinct though overlapping distributions of appearance, size and other LN characteristics. A novel multi-branch detection-by-segmentation network is trained with each branch specializing on learning one GTVLN category features, and outputs from multi-branch are fused in inference. The proposed method is evaluated on an in-house dataset of $141$ esophageal cancer patients with both PET and CT imaging modalities. Our results validate significant improvements on the mean recall from $72.5\%$ to $78.2\%$, as compared to previous state-of-the-art work. The highest achieved GTVLN recall of $82.5\%$ at $20\%$ precision is clinically relevant and valuable since human observers tend to have low sensitivity (around $80\%$ for the most experienced radiation oncologists, as reported by literature).
ASAP-Net: Attention and Structure Aware Point Cloud Sequence Segmentation
Aug 12, 2020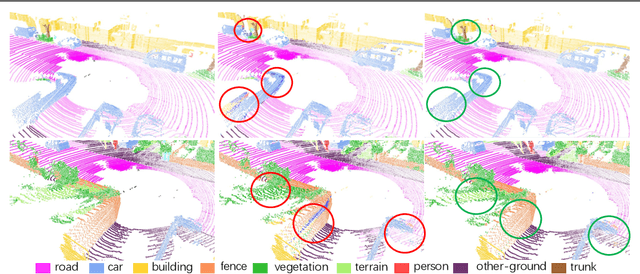
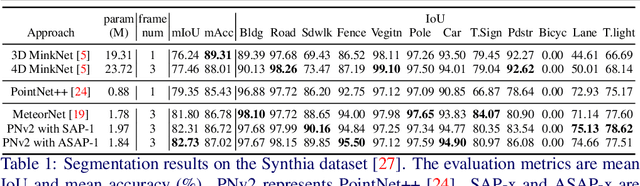
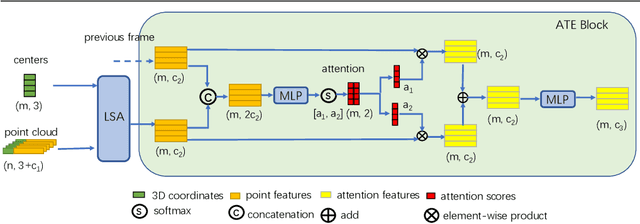
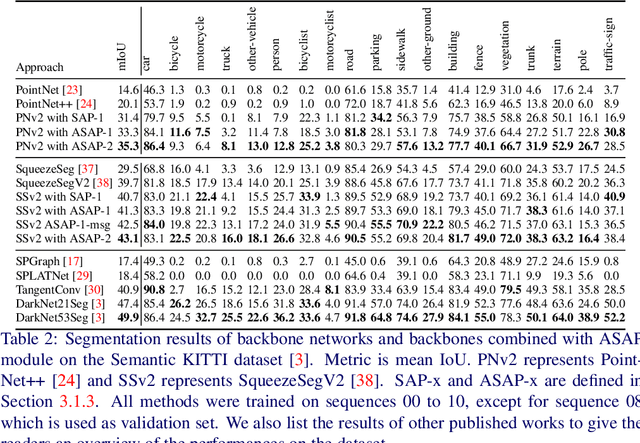
Recent works of point clouds show that mulit-frame spatio-temporal modeling outperforms single-frame versions by utilizing cross-frame information. In this paper, we further improve spatio-temporal point cloud feature learning with a flexible module called ASAP considering both attention and structure information across frames, which we find as two important factors for successful segmentation in dynamic point clouds. Firstly, our ASAP module contains a novel attentive temporal embedding layer to fuse the relatively informative local features across frames in a recurrent fashion. Secondly, an efficient spatio-temporal correlation method is proposed to exploit more local structure for embedding, meanwhile enforcing temporal consistency and reducing computation complexity. Finally, we show the generalization ability of the proposed ASAP module with different backbone networks for point cloud sequence segmentation. Our ASAP-Net (backbone plus ASAP module) outperforms baselines and previous methods on both Synthia and SemanticKITTI datasets (+3.4 to +15.2 mIoU points with different backbones). Code is availabe at https://github.com/intrepidChw/ASAP-Net
Probabilistic Multi-modal Trajectory Prediction with Lane Attention for Autonomous Vehicles
Jul 06, 2020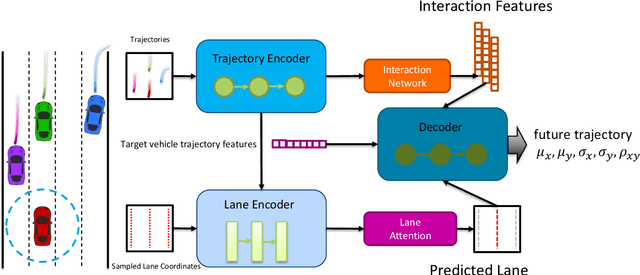
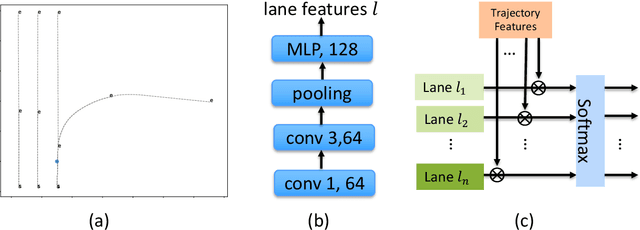
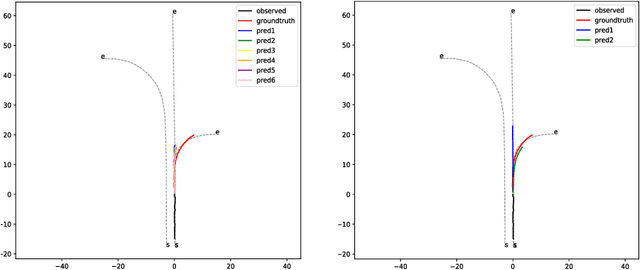
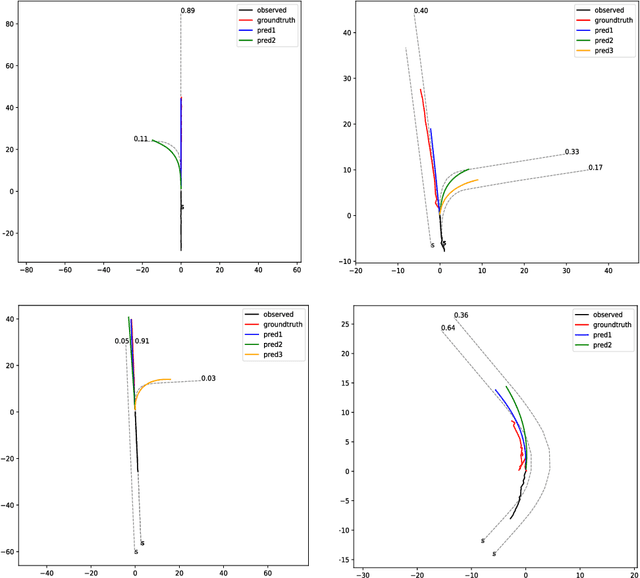
Trajectory prediction is crucial for autonomous vehicles. The planning system not only needs to know the current state of the surrounding objects but also their possible states in the future. As for vehicles, their trajectories are significantly influenced by the lane geometry and how to effectively use the lane information is of active interest. Most of the existing works use rasterized maps to explore road information, which does not distinguish different lanes. In this paper, we propose a novel instance-aware representation for lane representation. By integrating the lane features and trajectory features, a goal-oriented lane attention module is proposed to predict the future locations of the vehicle. We show that the proposed lane representation together with the lane attention module can be integrated into the widely used encoder-decoder framework to generate diverse predictions. Most importantly, each generated trajectory is associated with a probability to handle the uncertainty. Our method does not suffer from collapsing to one behavior modal and can cover diverse possibilities. Extensive experiments and ablation studies on the benchmark datasets corroborate the effectiveness of our proposed method. Notably, our proposed method ranks third place in the Argoverse motion forecasting competition at NeurIPS 2019.
Uncertainty-aware multi-view co-training for semi-supervised medical image segmentation and domain adaptation
Jun 28, 2020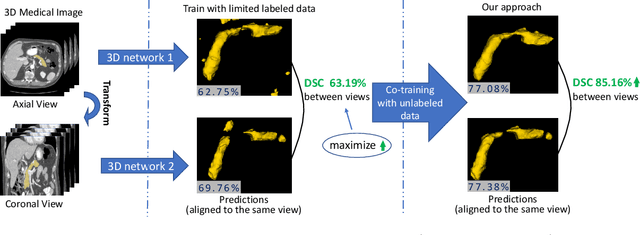
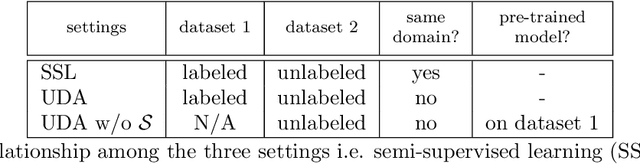
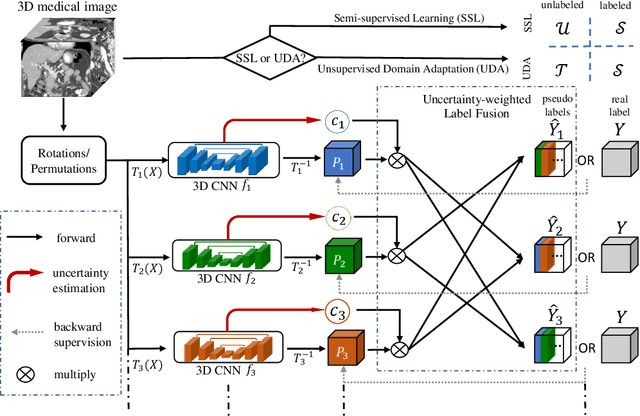
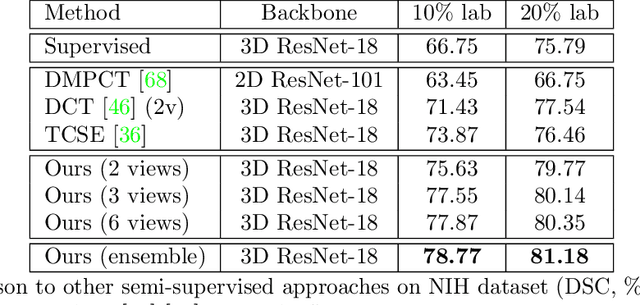
Although having achieved great success in medical image segmentation, deep learning-based approaches usually require large amounts of well-annotated data, which can be extremely expensive in the field of medical image analysis. Unlabeled data, on the other hand, is much easier to acquire. Semi-supervised learning and unsupervised domain adaptation both take the advantage of unlabeled data, and they are closely related to each other. In this paper, we propose uncertainty-aware multi-view co-training (UMCT), a unified framework that addresses these two tasks for volumetric medical image segmentation. Our framework is capable of efficiently utilizing unlabeled data for better performance. We firstly rotate and permute the 3D volumes into multiple views and train a 3D deep network on each view. We then apply co-training by enforcing multi-view consistency on unlabeled data, where an uncertainty estimation of each view is utilized to achieve accurate labeling. Experiments on the NIH pancreas segmentation dataset and a multi-organ segmentation dataset show state-of-the-art performance of the proposed framework on semi-supervised medical image segmentation. Under unsupervised domain adaptation settings, we validate the effectiveness of this work by adapting our multi-organ segmentation model to two pathological organs from the Medical Segmentation Decathlon Datasets. Additionally, we show that our UMCT-DA model can even effectively handle the challenging situation where labeled source data is inaccessible, demonstrating strong potentials for real-world applications.
* 19 pages, 6 figures, to appear in Medical Image Analysis. This article is an extension of the conference paper arXiv:1811.12506