 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-in-the-Loop Task and Motion Planning for Imitation Learning
Oct 24, 2023



Imitation learning from human demonstrations can teach robots complex manipulation skills, but is time-consuming and labor intensive. In contrast, Task and Motion Planning (TAMP) systems are automated and excel at solving long-horizon tasks, but they are difficult to apply to contact-rich tasks. In this paper, we present Human-in-the-Loop Task and Motion Planning (HITL-TAMP), a novel system that leverages the benefits of both approaches. The system employs a TAMP-gated control mechanism, which selectively gives and takes control to and from a human teleoperator. This enables the human teleoperator to manage a fleet of robots, maximizing data collection efficiency. The collected human data is then combined with an imitation learning framework to train a TAMP-gated policy, leading to superior performance compared to training on full task demonstrations. We compared HITL-TAMP to a conventional teleoperation system -- users gathered more than 3x the number of demos given the same time budget. Furthermore, proficient agents (75\%+ success) could be trained from just 10 minutes of non-expert teleoperation data. Finally, we collected 2.1K demos with HITL-TAMP across 12 contact-rich, long-horizon tasks and show that the system often produces near-perfect agents. Videos and additional results at https://hitltamp.github.io .
Imitating Task and Motion Planning with Visuomotor Transformers
May 25, 2023Imitation learning is a powerful tool for training robot manipulation policies, allowing them to learn from expert demonstrations without manual programming or trial-and-error. However, common methods of data collection, such as human supervision, scale poorly, as they are time-consuming and labor-intensive. In contrast, Task and Motion Planning (TAMP) can autonomously generate large-scale datasets of diverse demonstrations. In this work, we show that the combination of large-scale datasets generated by TAMP supervisors and flexible Transformer models to fit them is a powerful paradigm for robot manipulation. To that end, we present a novel imitation learning system called OPTIMUS that trains large-scale visuomotor Transformer policies by imitating a TAMP agent. OPTIMUS introduces a pipeline for generating TAMP data that is specifically curated for imitation learning and can be used to train performant transformer-based policies. In this paper, we present a thorough study of the design decisions required to imitate TAMP and demonstrate that OPTIMUS can solve a wide variety of challenging vision-based manipulation tasks with over 70 different objects, ranging from long-horizon pick-and-place tasks, to shelf and articulated object manipulation, achieving 70 to 80% success rates. Video results at https://mihdalal.github.io/optimus/
Voyager: An Open-Ended Embodied Agent with Large Language Models
May 25, 2023We introduce Voyager, the first LLM-powered embodied lifelong learning agent in Minecraft that continuously explores the world, acquires diverse skills, and makes novel discoveries without human intervention. Voyager consists of three key components: 1) an automatic curriculum that maximizes exploration, 2) an ever-growing skill library of executable code for storing and retrieving complex behaviors, and 3) a new iterative prompting mechanism that incorporates environment feedback, execution errors, and self-verification for program improvement. Voyager interacts with GPT-4 via blackbox queries, which bypasses the need for model parameter fine-tuning. The skills developed by Voyager are temporally extended, interpretable, and compositional, which compounds the agent's abilities rapidly and alleviates catastrophic forgetting. Empirically, Voyager shows strong in-context lifelong learning capability and exhibits exceptional proficiency in playing Minecraft. It obtains 3.3x more unique items, travels 2.3x longer distances, and unlocks key tech tree milestones up to 15.3x faster than prior SOTA. Voyager is able to utilize the learned skill library in a new Minecraft world to solve novel tasks from scratch, while other techniques struggle to generalize. We open-source our full codebase and prompts at https://voyager.minedojo.org/.
ORBIT: A Unified Simulation Framework for Interactive Robot Learning Environments
Jan 10, 2023



We present ORBIT, a unified and modular framework for robot learning powered by NVIDIA Isaac Sim. It offers a modular design to easily and efficiently create robotic environments with photo-realistic scenes and fast and accurate rigid and deformable body simulation. With ORBIT, we provide a suite of benchmark tasks of varying difficulty -- from single-stage cabinet opening and cloth folding to multi-stage tasks such as room reorganization. To support working with diverse observations and action spaces, we include fixed-arm and mobile manipulators with different physically-based sensors and motion generators. ORBIT allows training reinforcement learning policies and collecting large demonstration datasets from hand-crafted or expert solutions in a matter of minutes by leveraging GPU-based parallelization. In summary, we offer an open-sourced framework that readily comes with 16 robotic platforms, 4 sensor modalities, 10 motion generators, more than 20 benchmark tasks, and wrappers to 4 learning libraries. With this framework, we aim to support various research areas, including representation learning, reinforcement learning, imitation learning, and task and motion planning. We hope it helps establish interdisciplinary collaborations in these communities, and its modularity makes it easily extensible for more tasks and applications in the future. For videos, documentation, and code: https://isaac-orbit.github.io/.
Active Task Randomization: Learning Visuomotor Skills for Sequential Manipulation by Proposing Feasible and Novel Tasks
Nov 11, 2022



Solving real-world sequential manipulation tasks requires robots to have a repertoire of skills applicable to a wide range of circumstances. To acquire such skills using data-driven approaches, we need massive and diverse training data which is often labor-intensive and non-trivial to collect and curate. In this work, we introduce Active Task Randomization (ATR), an approach that learns visuomotor skills for sequential manipulation by automatically creating feasible and novel tasks in simulation. During training, our approach procedurally generates tasks using a graph-based task parameterization. To adaptively estimate the feasibility and novelty of sampled tasks, we develop a relational neural network that maps each task parameter into a compact embedding. We demonstrate that our approach can automatically create suitable tasks for efficiently training the skill policies to handle diverse scenarios with a variety of objects. We evaluate our method on simulated and real-world sequential manipulation tasks by composing the learned skills using a task planner. Compared to baseline methods, the skills learned using our approach consistently achieve better success rates.
Learning and Retrieval from Prior Data for Skill-based Imitation Learning
Oct 20, 2022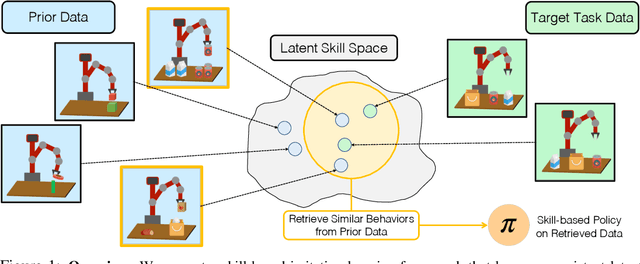

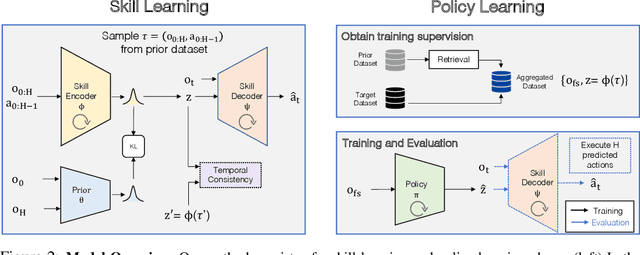

Imitation learning offers a promising path for robots to learn general-purpose behaviors, but traditionally has exhibited limited scalability due to high data supervision requirements and brittle generalization. Inspired by recent advances in multi-task imitation learning, we investigate the use of prior data from previous tasks to facilitate learning novel tasks in a robust, data-efficient manner. To make effective use of the prior data, the robot must internalize knowledge from past experiences and contextualize this knowledge in novel tasks. To that end, we develop a skill-based imitation learning framework that extracts temporally extended sensorimotor skills from prior data and subsequently learns a policy for the target task that invokes these learned skills. We identify several key design choices that significantly improve performance on novel tasks, namely representation learning objectives to enable more predictable skill representations and a retrieval-based data augmentation mechanism to increase the scope of supervision for policy training. On a collection of simulated and real-world manipulation domains, we demonstrate that our method significantly outperforms existing imitation learning and offline reinforcement learning approaches. Videos and code are available at https://ut-austin-rpl.github.io/sailor
MoCoDA: Model-based Counterfactual Data Augmentation
Oct 20, 2022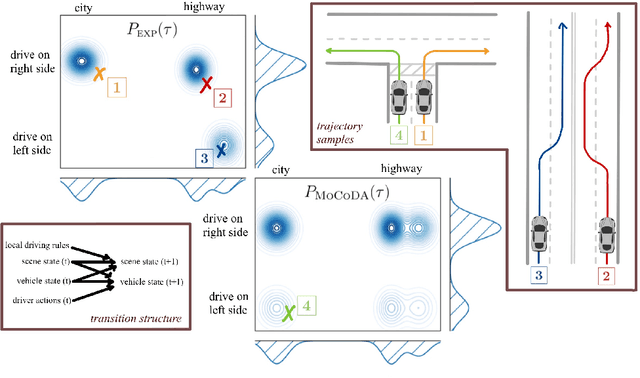
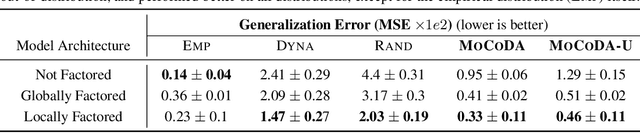
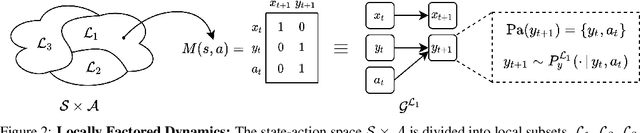
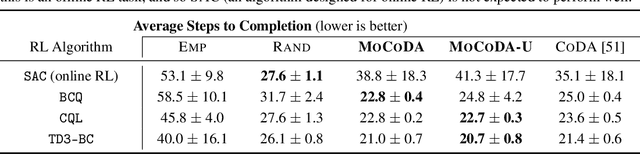
The number of states in a dynamic process is exponential in the number of objects, making reinforcement learning (RL) difficult in complex, multi-object domains. For agents to scale to the real world, they will need to react to and reason about unseen combinations of objects. We argue that the ability to recognize and use local factorization in transition dynamics is a key element in unlocking the power of multi-object reasoning. To this end, we show that (1) known local structure in the environment transitions is sufficient for an exponential reduction in the sample complexity of training a dynamics model, and (2) a locally factored dynamics model provably generalizes out-of-distribution to unseen states and actions. Knowing the local structure also allows us to predict which unseen states and actions this dynamics model will generalize to. We propose to leverage these observations in a novel Model-based Counterfactual Data Augmentation (MoCoDA) framework. MoCoDA applies a learned locally factored dynamics model to an augmented distribution of states and actions to generate counterfactual transitions for RL. MoCoDA works with a broader set of local structures than prior work and allows for direct control over the augmented training distribution. We show that MoCoDA enables RL agents to learn policies that generalize to unseen states and actions. We use MoCoDA to train an offline RL agent to solve an out-of-distribution robotics manipulation task on which standard offline RL algorithms fail.
MineDojo: Building Open-Ended Embodied Agents with Internet-Scale Knowledge
Jun 17, 2022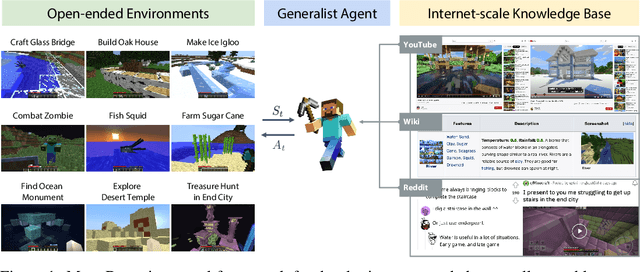
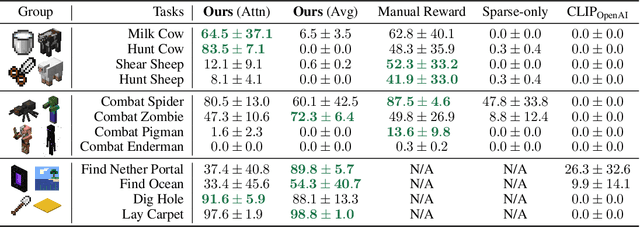
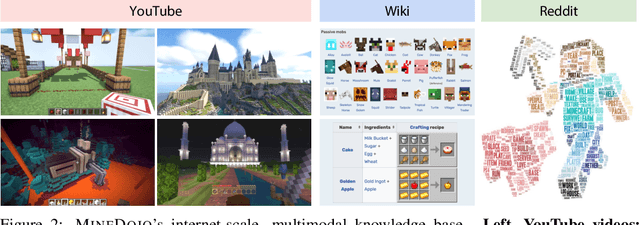

Autonomous agents have made great strides in specialist domains like Atari games and Go. However, they typically learn tabula rasa in isolated environments with limited and manually conceived objectives, thus failing to generalize across a wide spectrum of tasks and capabilities. Inspired by how humans continually learn and adapt in the open world, we advocate a trinity of ingredients for building generalist agents: 1) an environment that supports a multitude of tasks and goals, 2) a large-scale database of multimodal knowledge, and 3) a flexible and scalable agent architecture. We introduce MineDojo, a new framework built on the popular Minecraft game that features a simulation suite with thousands of diverse open-ended tasks and an internet-scale knowledge base with Minecraft videos, tutorials, wiki pages, and forum discussions. Using MineDojo's data, we propose a novel agent learning algorithm that leverages large pre-trained video-language models as a learned reward function. Our agent is able to solve a variety of open-ended tasks specified in free-form language without any manually designed dense shaping reward. We open-source the simulation suite and knowledge bases (https://minedojo.org) to promote research towards the goal of generally capable embodied agents.
Error-Aware Imitation Learning from Teleoperation Data for Mobile Manipulation
Dec 09, 2021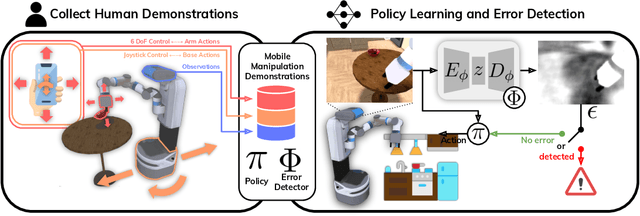
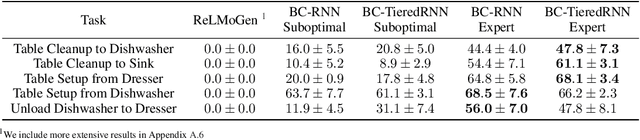

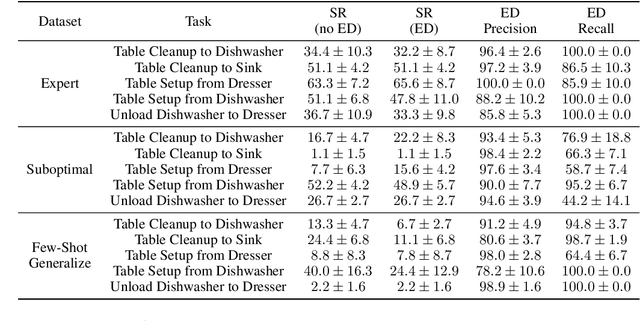
In mobile manipulation (MM), robots can both navigate within and interact with their environment and are thus able to complete many more tasks than robots only capable of navigation or manipulation. In this work, we explore how to apply imitation learning (IL) to learn continuous visuo-motor policies for MM tasks. Much prior work has shown that IL can train visuo-motor policies for either manipulation or navigation domains, but few works have applied IL to the MM domain. Doing this is challenging for two reasons: on the data side, current interfaces make collecting high-quality human demonstrations difficult, and on the learning side, policies trained on limited data can suffer from covariate shift when deployed. To address these problems, we first propose Mobile Manipulation RoboTurk (MoMaRT), a novel teleoperation framework allowing simultaneous navigation and manipulation of mobile manipulators, and collect a first-of-its-kind large scale dataset in a realistic simulated kitchen setting. We then propose a learned error detection system to address the covariate shift by detecting when an agent is in a potential failure state. We train performant IL policies and error detectors from this data, and achieve over 45% task success rate and 85% error detection success rate across multiple multi-stage tasks when trained on expert data. Codebase, datasets, visualization, and more available at https://sites.google.com/view/il-for-mm/home.
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Aug 06, 2021
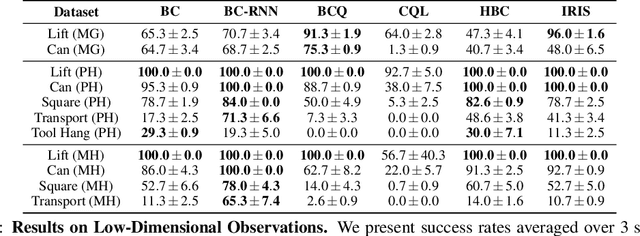
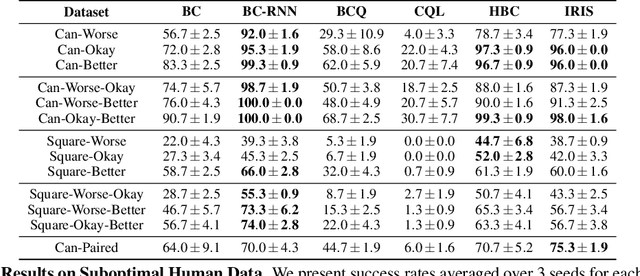
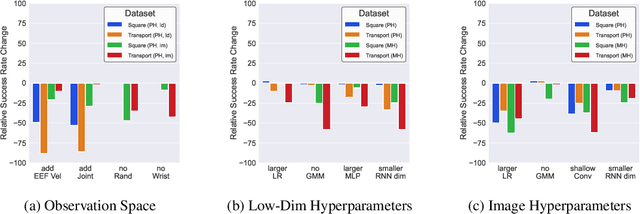
Imitating human demonstrations is a promising approach to endow robots with various manipulation capabilities. While recent advances have been made in imitation learning and batch (offline) reinforcement learning, a lack of open-source human datasets and reproducible learning methods make assessing the state of the field difficult. In this paper, we conduct an extensive study of six offline learning algorithms for robot manipulation on five simulated and three real-world multi-stage manipulation tasks of varying complexity, and with datasets of varying quality. Our study analyzes the most critical challenges when learning from offline human data for manipulation. Based on the study, we derive a series of lessons including the sensitivity to different algorithmic design choices, the dependence on the quality of the demonstrations, and the variability based on the stopping criteria due to the different objectives in training and evaluation. We also highlight opportunities for learning from human datasets, such as the ability to learn proficient policies on challenging, multi-stage tasks beyond the scope of current reinforcement learning methods, and the ability to easily scale to natural, real-world manipulation scenarios where only raw sensory signals are available. We have open-sourced our datasets and all algorithm implementations to facilitate future research and fair comparisons in learning from human demonstration data. Codebase, datasets, trained models, and more available at https://arise-initiative.github.io/robomimic-web/