 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR3M: A Universal Visual Representation for Robot Manipulation
Mar 23, 2022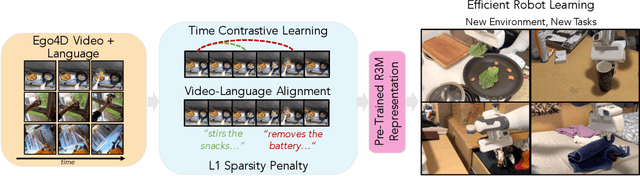
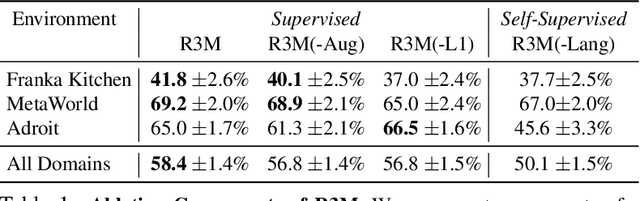
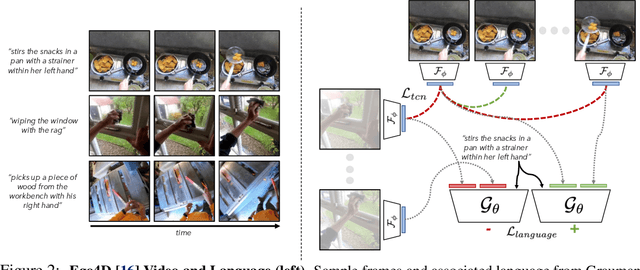
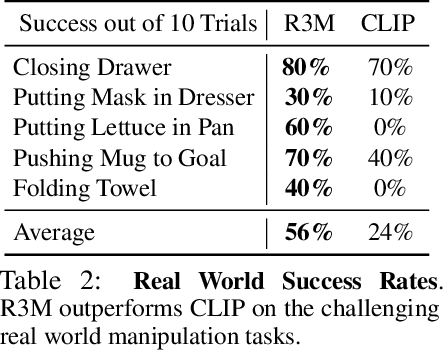
We study how visual representations pre-trained on diverse human video data can enable data-efficient learning of downstream robotic manipulation tasks. Concretely, we pre-train a visual representation using the Ego4D human video dataset using a combination of time-contrastive learning, video-language alignment, and an L1 penalty to encourage sparse and compact representations. The resulting representation, R3M, can be used as a frozen perception module for downstream policy learning. Across a suite of 12 simulated robot manipulation tasks, we find that R3M improves task success by over 20% compared to training from scratch and by over 10% compared to state-of-the-art visual representations like CLIP and MoCo. Furthermore, R3M enables a Franka Emika Panda arm to learn a range of manipulation tasks in a real, cluttered apartment given just 20 demonstrations. Code and pre-trained models are available at https://tinyurl.com/robotr3m.
RB2: Robotic Manipulation Benchmarking with a Twist
Mar 15, 2022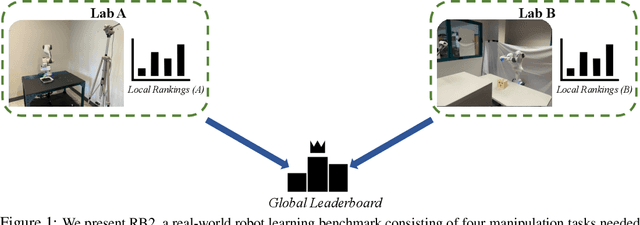
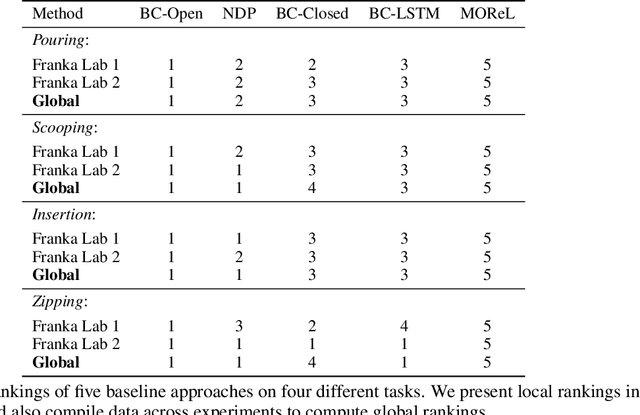


Benchmarks offer a scientific way to compare algorithms using objective performance metrics. Good benchmarks have two features: (a) they should be widely useful for many research groups; (b) and they should produce reproducible findings. In robotic manipulation research, there is a trade-off between reproducibility and broad accessibility. If the benchmark is kept restrictive (fixed hardware, objects), the numbers are reproducible but the setup becomes less general. On the other hand, a benchmark could be a loose set of protocols (e.g. object sets) but the underlying variation in setups make the results non-reproducible. In this paper, we re-imagine benchmarking for robotic manipulation as state-of-the-art algorithmic implementations, alongside the usual set of tasks and experimental protocols. The added baseline implementations will provide a way to easily recreate SOTA numbers in a new local robotic setup, thus providing credible relative rankings between existing approaches and new work. However, these local rankings could vary between different setups. To resolve this issue, we build a mechanism for pooling experimental data between labs, and thus we establish a single global ranking for existing (and proposed) SOTA algorithms. Our benchmark, called Ranking-Based Robotics Benchmark (RB2), is evaluated on tasks that are inspired from clinically validated Southampton Hand Assessment Procedures. Our benchmark was run across two different labs and reveals several surprising findings. For example, extremely simple baselines like open-loop behavior cloning, outperform more complicated models (e.g. closed loop, RNN, Offline-RL, etc.) that are preferred by the field. We hope our fellow researchers will use RB2 to improve their research's quality and rigor.
The Unsurprising Effectiveness of Pre-Trained Vision Models for Control
Mar 07, 2022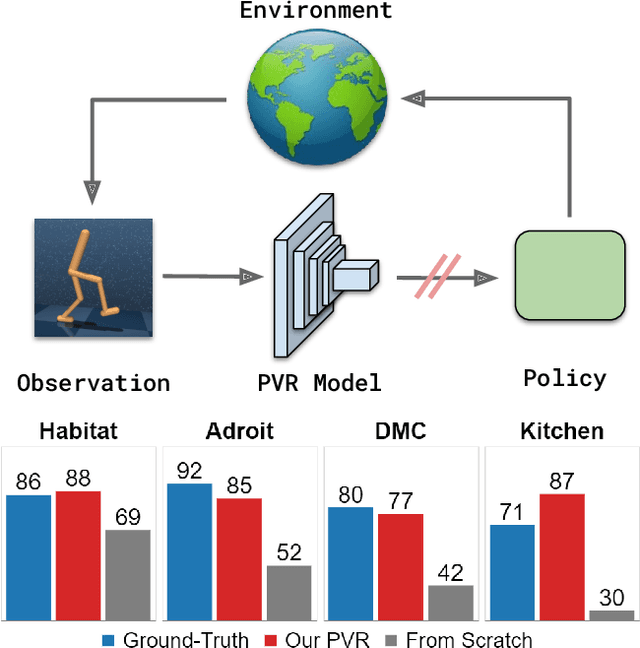



Recent years have seen the emergence of pre-trained representations as a powerful abstraction for AI applications in computer vision, natural language, and speech. However, policy learning for control is still dominated by a tabula-rasa learning paradigm, with visuo-motor policies often trained from scratch using data from deployment environments. In this context, we revisit and study the role of pre-trained visual representations for control, and in particular representations trained on large-scale computer vision datasets. Through extensive empirical evaluation in diverse control domains (Habitat, DeepMind Control, Adroit, Franka Kitchen), we isolate and study the importance of different representation training methods, data augmentations, and feature hierarchies. Overall, we find that pre-trained visual representations can be competitive or even better than ground-truth state representations to train control policies. This is in spite of using only out-of-domain data from standard vision datasets, without any in-domain data from the deployment environments. Additional details and source code is available at https://sites.google.com/view/pvr-control
Interesting Object, Curious Agent: Learning Task-Agnostic Exploration
Nov 25, 2021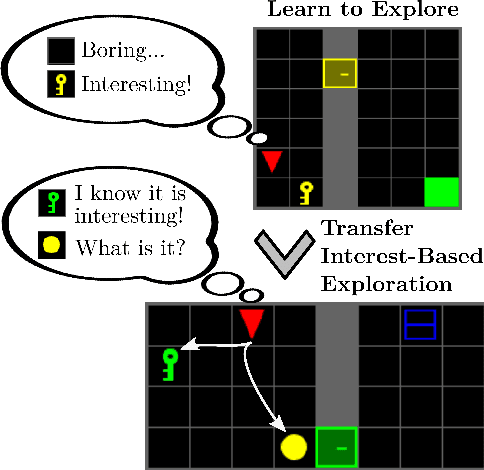

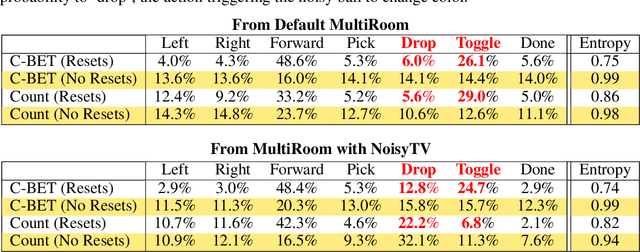
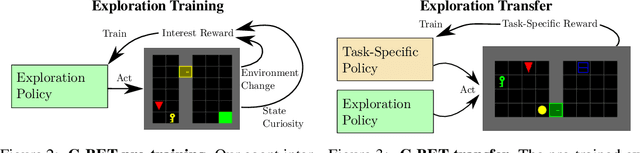
Common approaches for task-agnostic exploration learn tabula-rasa --the agent assumes isolated environments and no prior knowledge or experience. However, in the real world, agents learn in many environments and always come with prior experiences as they explore new ones. Exploration is a lifelong process. In this paper, we propose a paradigm change in the formulation and evaluation of task-agnostic exploration. In this setup, the agent first learns to explore across many environments without any extrinsic goal in a task-agnostic manner. Later on, the agent effectively transfers the learned exploration policy to better explore new environments when solving tasks. In this context, we evaluate several baseline exploration strategies and present a simple yet effective approach to learning task-agnostic exploration policies. Our key idea is that there are two components of exploration: (1) an agent-centric component encouraging exploration of unseen parts of the environment based on an agent's belief; (2) an environment-centric component encouraging exploration of inherently interesting objects. We show that our formulation is effective and provides the most consistent exploration across several training-testing environment pairs. We also introduce benchmarks and metrics for evaluating task-agnostic exploration strategies. The source code is available at https://github.com/sparisi/cbet/.
A Differentiable Recipe for Learning Visual Non-Prehensile Planar Manipulation
Nov 09, 2021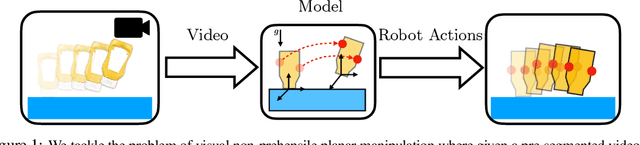

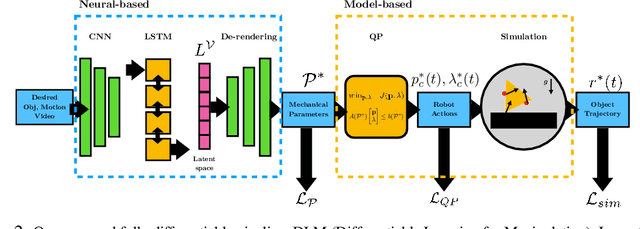
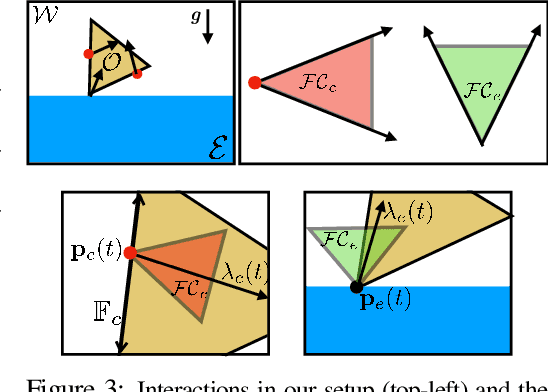
Specifying tasks with videos is a powerful technique towards acquiring novel and general robot skills. However, reasoning over mechanics and dexterous interactions can make it challenging to scale learning contact-rich manipulation. In this work, we focus on the problem of visual non-prehensile planar manipulation: given a video of an object in planar motion, find contact-aware robot actions that reproduce the same object motion. We propose a novel architecture, Differentiable Learning for Manipulation (\ours), that combines video decoding neural models with priors from contact mechanics by leveraging differentiable optimization and finite difference based simulation. Through extensive simulated experiments, we investigate the interplay between traditional model-based techniques and modern deep learning approaches. We find that our modular and fully differentiable architecture performs better than learning-only methods on unseen objects and motions. \url{https://github.com/baceituno/dlm}.
ReSkin: versatile, replaceable, lasting tactile skins
Oct 29, 2021


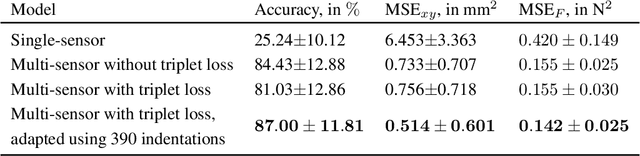
Soft sensors have continued growing interest in robotics, due to their ability to enable both passive conformal contact from the material properties and active contact data from the sensor properties. However, the same properties of conformal contact result in faster deterioration of soft sensors and larger variations in their response characteristics over time and across samples, inhibiting their ability to be long-lasting and replaceable. ReSkin is a tactile soft sensor that leverages machine learning and magnetic sensing to offer a low-cost, diverse and compact solution for long-term use. Magnetic sensing separates the electronic circuitry from the passive interface, making it easier to replace interfaces as they wear out while allowing for a wide variety of form factors. Machine learning allows us to learn sensor response models that are robust to variations across fabrication and time, and our self-supervised learning algorithm enables finer performance enhancement with small, inexpensive data collection procedures. We believe that ReSkin opens the door to more versatile, scalable and inexpensive tactile sensation modules than existing alternatives.
Dynamic population-based meta-learning for multi-agent communication with natural language
Oct 27, 2021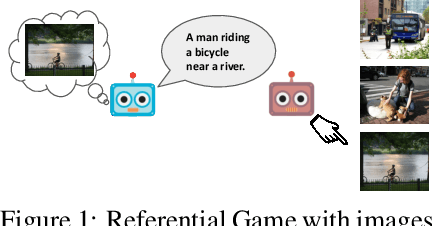
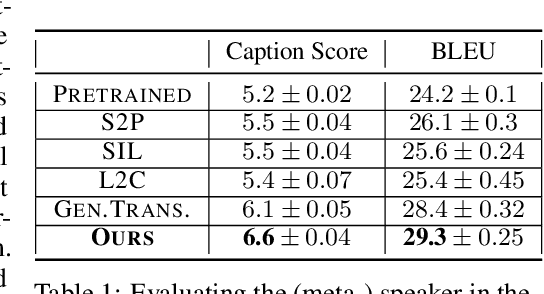
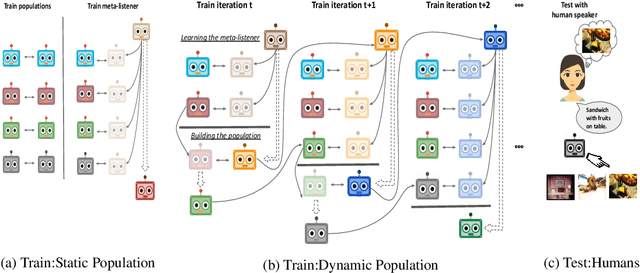
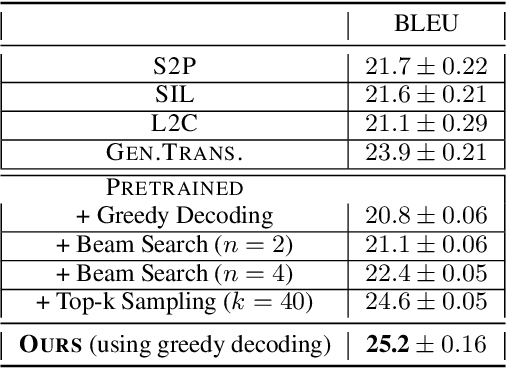
In this work, our goal is to train agents that can coordinate with seen, unseen as well as human partners in a multi-agent communication environment involving natural language. Previous work using a single set of agents has shown great progress in generalizing to known partners, however it struggles when coordinating with unfamiliar agents. To mitigate that, recent work explored the use of population-based approaches, where multiple agents interact with each other with the goal of learning more generic protocols. These methods, while able to result in good coordination between unseen partners, still only achieve so in cases of simple languages, thus failing to adapt to human partners using natural language. We attribute this to the use of static populations and instead propose a dynamic population-based meta-learning approach that builds such a population in an iterative manner. We perform a holistic evaluation of our method on two different referential games, and show that our agents outperform all prior work when communicating with seen partners and humans. Furthermore, we analyze the natural language generation skills of our agents, where we find that our agents also outperform strong baselines. Finally, we test the robustness of our agents when communicating with out-of-population agents and carefully test the importance of each component of our method through ablation studies.
No RL, No Simulation: Learning to Navigate without Navigating
Oct 22, 2021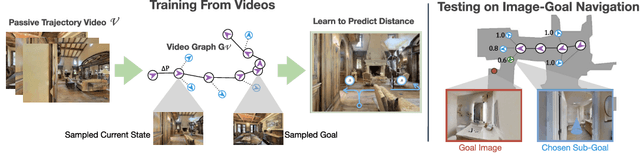
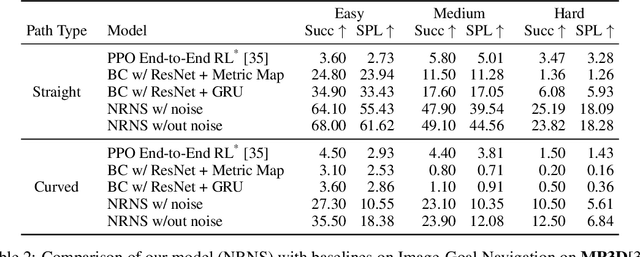
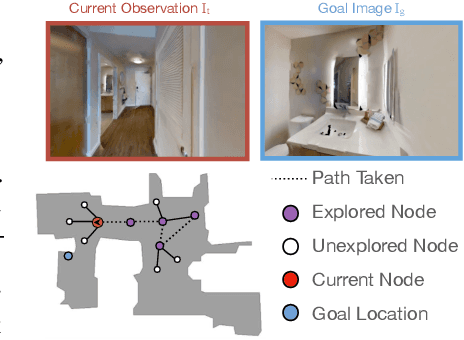
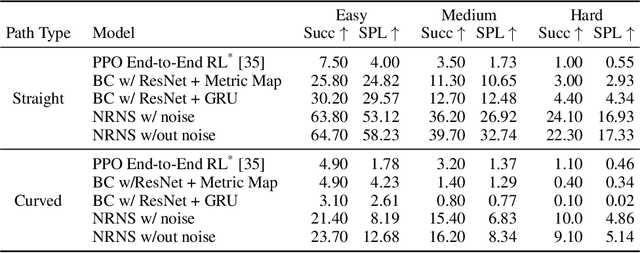
Most prior methods for learning navigation policies require access to simulation environments, as they need online policy interaction and rely on ground-truth maps for rewards. However, building simulators is expensive (requires manual effort for each and every scene) and creates challenges in transferring learned policies to robotic platforms in the real-world, due to the sim-to-real domain gap. In this paper, we pose a simple question: Do we really need active interaction, ground-truth maps or even reinforcement-learning (RL) in order to solve the image-goal navigation task? We propose a self-supervised approach to learn to navigate from only passive videos of roaming. Our approach, No RL, No Simulator (NRNS), is simple and scalable, yet highly effective. NRNS outperforms RL-based formulations by a significant margin. We present NRNS as a strong baseline for any future image-based navigation tasks that use RL or Simulation.
CORA: Benchmarks, Baselines, and Metrics as a Platform for Continual Reinforcement Learning Agents
Oct 19, 2021Progress in continual reinforcement learning has been limited due to several barriers to entry: missing code, high compute requirements, and a lack of suitable benchmarks. In this work, we present CORA, a platform for Continual Reinforcement Learning Agents that provides benchmarks, baselines, and metrics in a single code package. The benchmarks we provide are designed to evaluate different aspects of the continual RL challenge, such as catastrophic forgetting, plasticity, ability to generalize, and sample-efficient learning. Three of the benchmarks utilize video game environments (Atari, Procgen, NetHack). The fourth benchmark, CHORES, consists of four different task sequences in a visually realistic home simulator, drawn from a diverse set of task and scene parameters. To compare continual RL methods on these benchmarks, we prepare three metrics in CORA: continual evaluation, forgetting, and zero-shot forward transfer. Finally, CORA includes a set of performant, open-source baselines of existing algorithms for researchers to use and expand on. We release CORA and hope that the continual RL community can benefit from our contributions, to accelerate the development of new continual RL algorithms.
Learning Multi-Objective Curricula for Deep Reinforcement Learning
Oct 06, 2021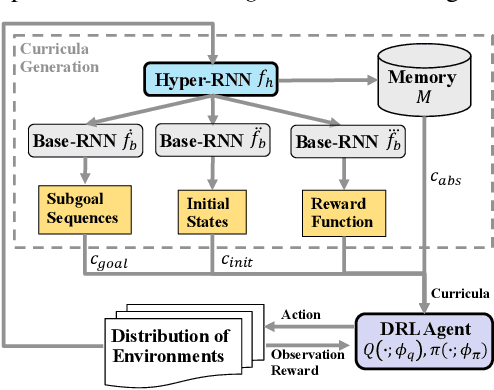

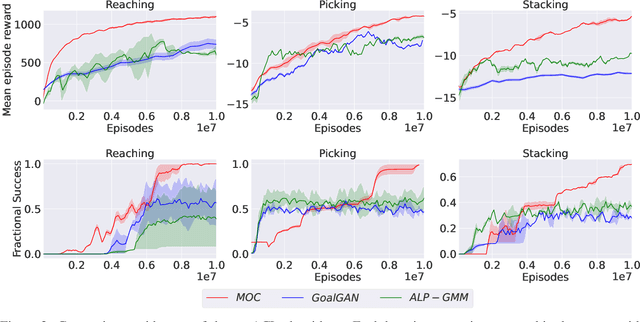
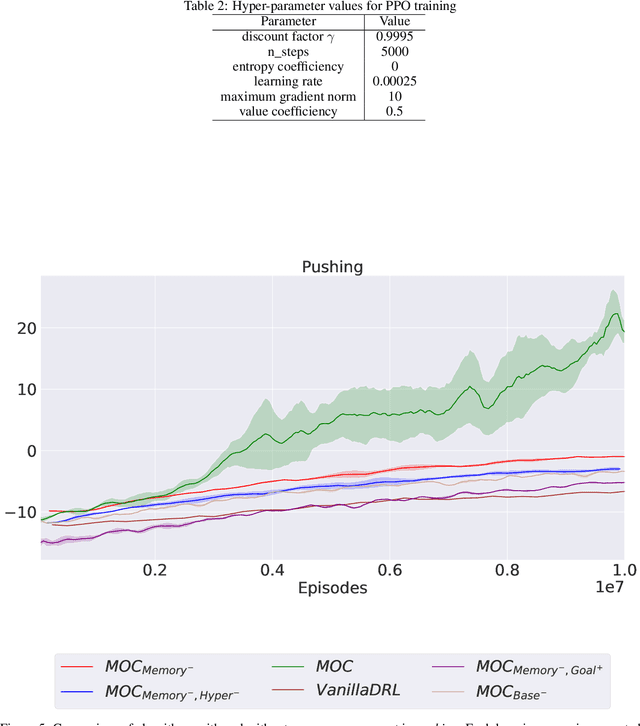
Various automatic curriculum learning (ACL) methods have been proposed to improve the sample efficiency and final performance of deep reinforcement learning (DRL). They are designed to control how a DRL agent collects data, which is inspired by how humans gradually adapt their learning processes to their capabilities. For example, ACL can be used for subgoal generation, reward shaping, environment generation, or initial state generation. However, prior work only considers curriculum learning following one of the aforementioned predefined paradigms. It is unclear which of these paradigms are complementary, and how the combination of them can be learned from interactions with the environment. Therefore, in this paper, we propose a unified automatic curriculum learning framework to create multi-objective but coherent curricula that are generated by a set of parametric curriculum modules. Each curriculum module is instantiated as a neural network and is responsible for generating a particular curriculum. In order to coordinate those potentially conflicting modules in unified parameter space, we propose a multi-task hyper-net learning framework that uses a single hyper-net to parameterize all those curriculum modules. In addition to existing hand-designed curricula paradigms, we further design a flexible memory mechanism to learn an abstract curriculum, which may otherwise be difficult to design manually. We evaluate our method on a series of robotic manipulation tasks and demonstrate its superiority over other state-of-the-art ACL methods in terms of sample efficiency and final performance.