 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Policy Optimization
Mar 24, 2025



Despite its extreme sample inefficiency, on-policy reinforcement learning has become a fundamental tool in real-world applications. With recent advances in GPU-driven simulation, the ability to collect vast amounts of data for RL training has scaled exponentially. However, studies show that current on-policy methods, such as PPO, fail to fully leverage the benefits of parallelized environments, leading to performance saturation beyond a certain scale. In contrast, Evolutionary Algorithms (EAs) excel at increasing diversity through randomization, making them a natural complement to RL. However, existing EvoRL methods have struggled to gain widespread adoption due to their extreme sample inefficiency. To address these challenges, we introduce Evolutionary Policy Optimization (EPO), a novel policy gradient algorithm that combines the strengths of EA and policy gradients. We show that EPO significantly improves performance across diverse and challenging environments, demonstrating superior scalability with parallelized simulations.
One-shot Video Imitation via Parameterized Symbolic Abstraction Graphs
Aug 22, 2024



Learning to manipulate dynamic and deformable objects from a single demonstration video holds great promise in terms of scalability. Previous approaches have predominantly focused on either replaying object relationships or actor trajectories. The former often struggles to generalize across diverse tasks, while the latter suffers from data inefficiency. Moreover, both methodologies encounter challenges in capturing invisible physical attributes, such as forces. In this paper, we propose to interpret video demonstrations through Parameterized Symbolic Abstraction Graphs (PSAG), where nodes represent objects and edges denote relationships between objects. We further ground geometric constraints through simulation to estimate non-geometric, visually imperceptible attributes. The augmented PSAG is then applied in real robot experiments. Our approach has been validated across a range of tasks, such as Cutting Avocado, Cutting Vegetable, Pouring Liquid, Rolling Dough, and Slicing Pizza. We demonstrate successful generalization to novel objects with distinct visual and physical properties.
Robot Parkour Learning
Sep 12, 2023



Parkour is a grand challenge for legged locomotion that requires robots to overcome various obstacles rapidly in complex environments. Existing methods can generate either diverse but blind locomotion skills or vision-based but specialized skills by using reference animal data or complex rewards. However, autonomous parkour requires robots to learn generalizable skills that are both vision-based and diverse to perceive and react to various scenarios. In this work, we propose a system for learning a single end-to-end vision-based parkour policy of diverse parkour skills using a simple reward without any reference motion data. We develop a reinforcement learning method inspired by direct collocation to generate parkour skills, including climbing over high obstacles, leaping over large gaps, crawling beneath low barriers, squeezing through thin slits, and running. We distill these skills into a single vision-based parkour policy and transfer it to a quadrupedal robot using its egocentric depth camera. We demonstrate that our system can empower two different low-cost robots to autonomously select and execute appropriate parkour skills to traverse challenging real-world environments.
Manipulate by Seeing: Creating Manipulation Controllers from Pre-Trained Representations
Mar 15, 2023



The field of visual representation learning has seen explosive growth in the past years, but its benefits in robotics have been surprisingly limited so far. Prior work uses generic visual representations as a basis to learn (task-specific) robot action policies (e.g. via behavior cloning). While the visual representations do accelerate learning, they are primarily used to encode visual observations. Thus, action information has to be derived purely from robot data, which is expensive to collect! In this work, we present a scalable alternative where the visual representations can help directly infer robot actions. We observe that vision encoders express relationships between image observations as distances (e.g. via embedding dot product) that could be used to efficiently plan robot behavior. We operationalize this insight and develop a simple algorithm for acquiring a distance function and dynamics predictor, by fine-tuning a pre-trained representation on human collected video sequences. The final method is able to substantially outperform traditional robot learning baselines (e.g. 70% success v.s. 50% for behavior cloning on pick-place) on a suite of diverse real-world manipulation tasks. It can also generalize to novel objects, without using any robot demonstrations during train time. For visualizations of the learned policies please check: https://agi-labs.github.io/manipulate-by-seeing/
Curiosity Driven Self-supervised Tactile Exploration of Unknown Objects
Mar 31, 2022
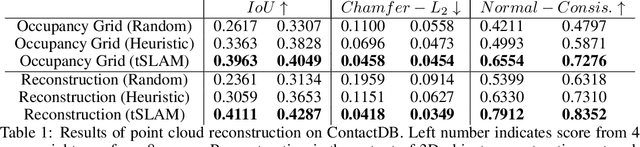

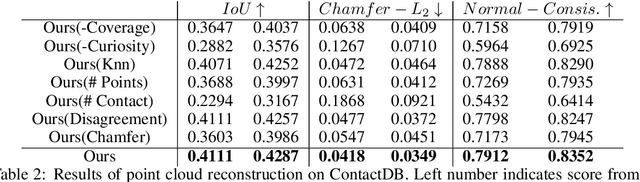
Intricate behaviors an organism can exhibit is predicated on its ability to sense and effectively interpret complexities of its surroundings. Relevant information is often distributed between multiple modalities, and requires the organism to exhibit information assimilation capabilities in addition to information seeking behaviors. While biological beings leverage multiple sensing modalities for decision making, current robots are overly reliant on visual inputs. In this work, we want to augment our robots with the ability to leverage the (relatively under-explored) modality of touch. To focus our investigation, we study the problem of scene reconstruction where touch is the only available sensing modality. We present Tactile Slam (tSLAM) -- which prepares an agent to acquire information seeking behavior and use implicit understanding of common household items to reconstruct the geometric details of the object under exploration. Using the anthropomorphic `ADROIT' hand, we demonstrate that tSLAM is highly effective in reconstructing objects of varying complexities within 6 seconds of interactions. We also established the generality of tSLAM by training only on 3D Warehouse objects and testing on ContactDB objects.
RB2: Robotic Manipulation Benchmarking with a Twist
Mar 15, 2022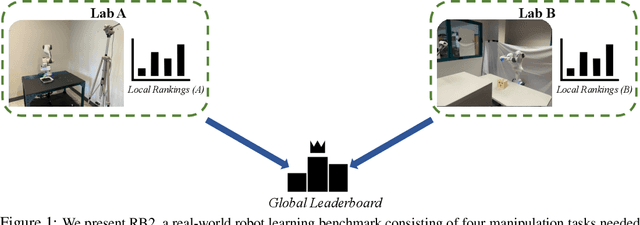
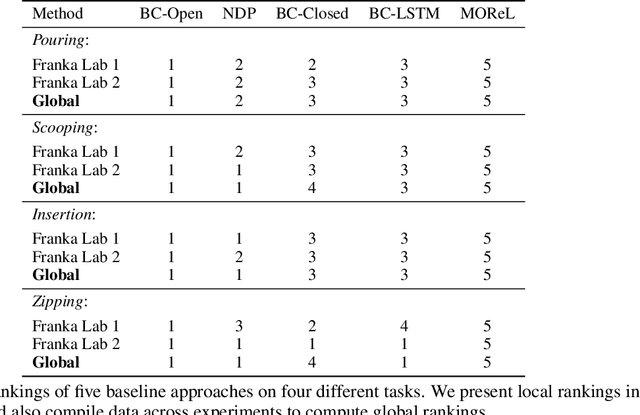


Benchmarks offer a scientific way to compare algorithms using objective performance metrics. Good benchmarks have two features: (a) they should be widely useful for many research groups; (b) and they should produce reproducible findings. In robotic manipulation research, there is a trade-off between reproducibility and broad accessibility. If the benchmark is kept restrictive (fixed hardware, objects), the numbers are reproducible but the setup becomes less general. On the other hand, a benchmark could be a loose set of protocols (e.g. object sets) but the underlying variation in setups make the results non-reproducible. In this paper, we re-imagine benchmarking for robotic manipulation as state-of-the-art algorithmic implementations, alongside the usual set of tasks and experimental protocols. The added baseline implementations will provide a way to easily recreate SOTA numbers in a new local robotic setup, thus providing credible relative rankings between existing approaches and new work. However, these local rankings could vary between different setups. To resolve this issue, we build a mechanism for pooling experimental data between labs, and thus we establish a single global ranking for existing (and proposed) SOTA algorithms. Our benchmark, called Ranking-Based Robotics Benchmark (RB2), is evaluated on tasks that are inspired from clinically validated Southampton Hand Assessment Procedures. Our benchmark was run across two different labs and reveals several surprising findings. For example, extremely simple baselines like open-loop behavior cloning, outperform more complicated models (e.g. closed loop, RNN, Offline-RL, etc.) that are preferred by the field. We hope our fellow researchers will use RB2 to improve their research's quality and rigor.
Semi-supervised 3D Object Detection via Temporal Graph Neural Networks
Feb 01, 2022

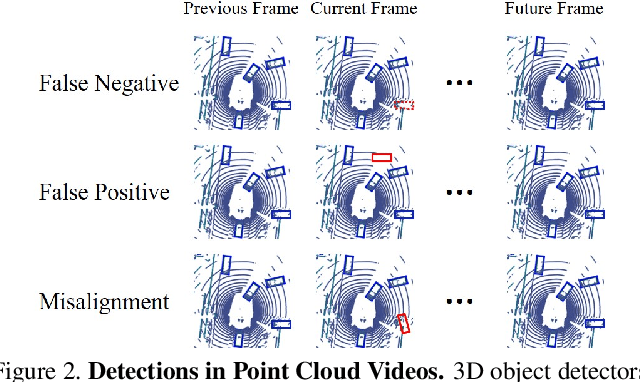
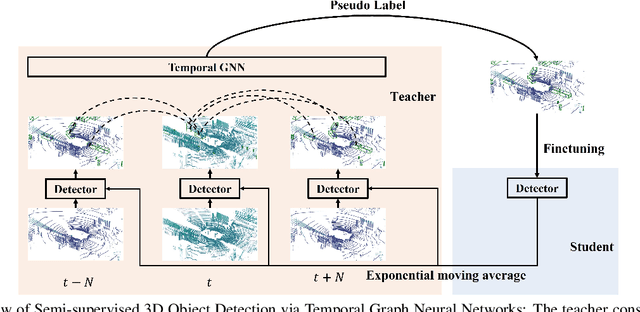
3D object detection plays an important role in autonomous driving and other robotics applications. However, these detectors usually require training on large amounts of annotated data that is expensive and time-consuming to collect. Instead, we propose leveraging large amounts of unlabeled point cloud videos by semi-supervised learning of 3D object detectors via temporal graph neural networks. Our insight is that temporal smoothing can create more accurate detection results on unlabeled data, and these smoothed detections can then be used to retrain the detector. We learn to perform this temporal reasoning with a graph neural network, where edges represent the relationship between candidate detections in different time frames. After semi-supervised learning, our method achieves state-of-the-art detection performance on the challenging nuScenes and H3D benchmarks, compared to baselines trained on the same amount of labeled data. Project and code are released at https://www.jianrenw.com/SOD-TGNN/.
Wanderlust: Online Continual Object Detection in the Real World
Sep 07, 2021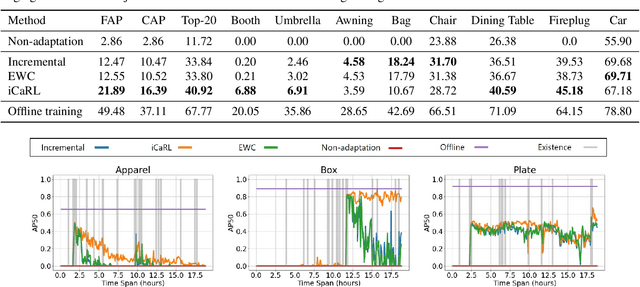


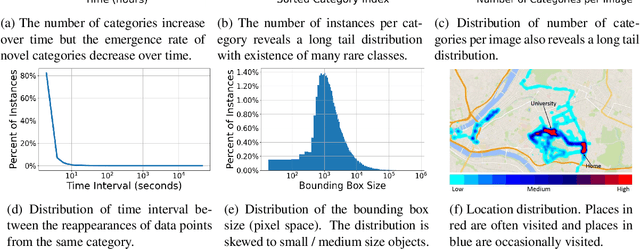
Online continual learning from data streams in dynamic environments is a critical direction in the computer vision field. However, realistic benchmarks and fundamental studies in this line are still missing. To bridge the gap, we present a new online continual object detection benchmark with an egocentric video dataset, Objects Around Krishna (OAK). OAK adopts the KrishnaCAM videos, an ego-centric video stream collected over nine months by a graduate student. OAK provides exhaustive bounding box annotations of 80 video snippets (~17.5 hours) for 105 object categories in outdoor scenes. The emergence of new object categories in our benchmark follows a pattern similar to what a single person might see in their day-to-day life. The dataset also captures the natural distribution shifts as the person travels to different places. These egocentric long-running videos provide a realistic playground for continual learning algorithms, especially in online embodied settings. We also introduce new evaluation metrics to evaluate the model performance and catastrophic forgetting and provide baseline studies for online continual object detection. We believe this benchmark will pose new exciting challenges for learning from non-stationary data in continual learning. The OAK dataset and the associated benchmark are released at https://oakdata.github.io/.
MolCLR: Molecular Contrastive Learning of Representations via Graph Neural Networks
Feb 19, 2021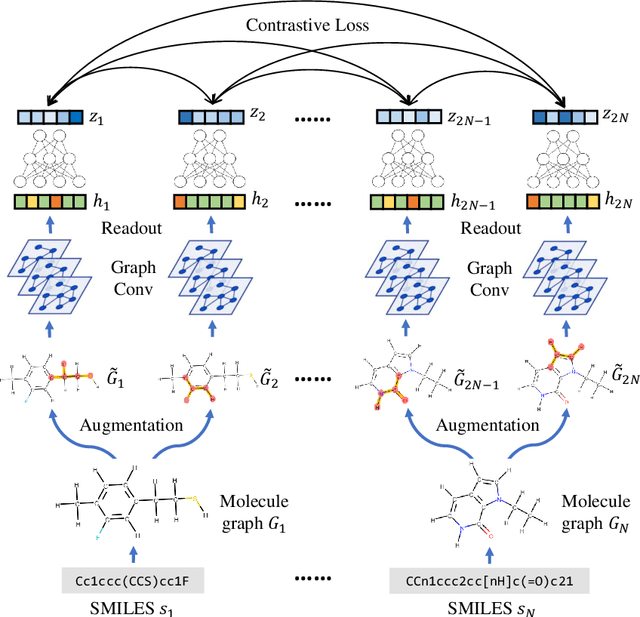
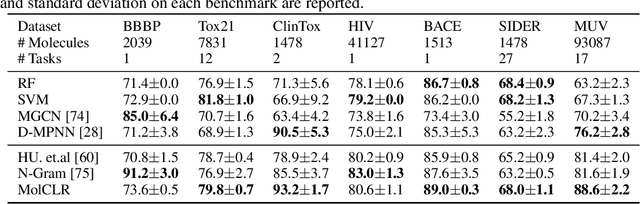
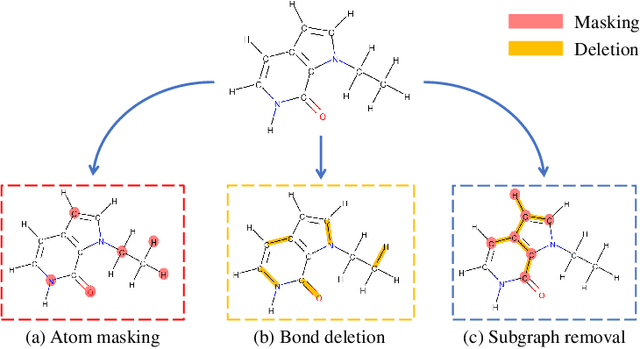

Molecular machine learning bears promise for efficient molecule property prediction and drug discovery. However, due to the limited labeled data and the giant chemical space, machine learning models trained via supervised learning perform poorly in generalization. This greatly limits the applications of machine learning methods for molecular design and discovery. In this work, we present MolCLR: Molecular Contrastive Learning of Representations via Graph Neural Networks (GNNs), a self-supervised learning framework for large unlabeled molecule datasets. Specifically, we first build a molecular graph, where each node represents an atom and each edge represents a chemical bond. A GNN is then used to encode the molecule graph. We propose three novel molecule graph augmentations: atom masking, bond deletion, and subgraph removal. A contrastive estimator is utilized to maximize the agreement of different graph augmentations from the same molecule. Experiments show that molecule representations learned by MolCLR can be transferred to multiple downstream molecular property prediction tasks. Our method thus achieves state-of-the-art performance on many challenging datasets. We also prove the efficiency of our proposed molecule graph augmentations on supervised molecular classification tasks.
PanoNet3D: Combining Semantic and Geometric Understanding for LiDARPoint Cloud Detection
Dec 17, 2020

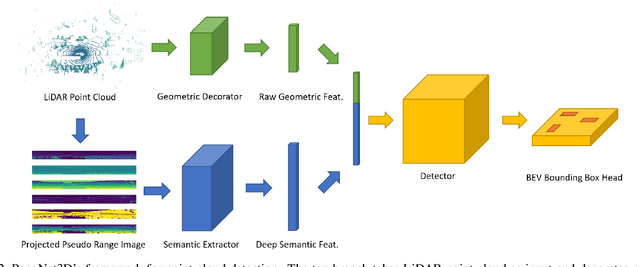

Visual data in autonomous driving perception, such as camera image and LiDAR point cloud, can be interpreted as a mixture of two aspects: semantic feature and geometric structure. Semantics come from the appearance and context of objects to the sensor, while geometric structure is the actual 3D shape of point clouds. Most detectors on LiDAR point clouds focus only on analyzing the geometric structure of objects in real 3D space. Unlike previous works, we propose to learn both semantic feature and geometric structure via a unified multi-view framework. Our method exploits the nature of LiDAR scans -- 2D range images, and applies well-studied 2D convolutions to extract semantic features. By fusing semantic and geometric features, our method outperforms state-of-the-art approaches in all categories by a large margin. The methodology of combining semantic and geometric features provides a unique perspective of looking at the problems in real-world 3D point cloud detection.