 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized and Context-Aware Transformer Models for Predicting Post-Intervention Physiological Responses from Wearable Sensor Data
Apr 16, 2026Consumer wearables enable continuous measurement of physiological data related to stress and recovery, but turning these streams into actionable, personalized stress-management recommendations remains a challenge. In practice, users often do not know how a given intervention, defined as an activity intended to reduce stress, will affect heart rate (HR), heart rate variability (HRV), or inter-beat intervals (BBI) over the next 15 to 120 minutes. We present a framework that predicts post-intervention trajectories and the direction of change for these physiological indicators across time windows. Our methodology combines a Transformer model for multi-horizon trajectories of percent change relative to a pre-intervention baseline, direction-of-change calls (positive, negative, or neutral) at each horizon, and an empirical study using wearable sensor data overlaid with user-tagged events and interventions. This proof of concept shows that personalized post-intervention prediction is feasible. We encourage future integration into stress-management tools for personalized intervention recommendations tailored to each person's day following further validation in larger studies and, where applicable, appropriate regulatory review.
Hearing Touch: Audio-Visual Pretraining for Contact-Rich Manipulation
May 14, 2024



Although pre-training on a large amount of data is beneficial for robot learning, current paradigms only perform large-scale pretraining for visual representations, whereas representations for other modalities are trained from scratch. In contrast to the abundance of visual data, it is unclear what relevant internet-scale data may be used for pretraining other modalities such as tactile sensing. Such pretraining becomes increasingly crucial in the low-data regimes common in robotics applications. In this paper, we address this gap by using contact microphones as an alternative tactile sensor. Our key insight is that contact microphones capture inherently audio-based information, allowing us to leverage large-scale audio-visual pretraining to obtain representations that boost the performance of robotic manipulation. To the best of our knowledge, our method is the first approach leveraging large-scale multisensory pre-training for robotic manipulation. For supplementary information including videos of real robot experiments, please see https://sites.google.com/view/hearing-touch.
Train Offline, Test Online: A Real Robot Learning Benchmark
Jun 01, 2023



Three challenges limit the progress of robot learning research: robots are expensive (few labs can participate), everyone uses different robots (findings do not generalize across labs), and we lack internet-scale robotics data. We take on these challenges via a new benchmark: Train Offline, Test Online (TOTO). TOTO provides remote users with access to shared robotic hardware for evaluating methods on common tasks and an open-source dataset of these tasks for offline training. Its manipulation task suite requires challenging generalization to unseen objects, positions, and lighting. We present initial results on TOTO comparing five pretrained visual representations and four offline policy learning baselines, remotely contributed by five institutions. The real promise of TOTO, however, lies in the future: we release the benchmark for additional submissions from any user, enabling easy, direct comparison to several methods without the need to obtain hardware or collect data.
Interesting Object, Curious Agent: Learning Task-Agnostic Exploration
Nov 25, 2021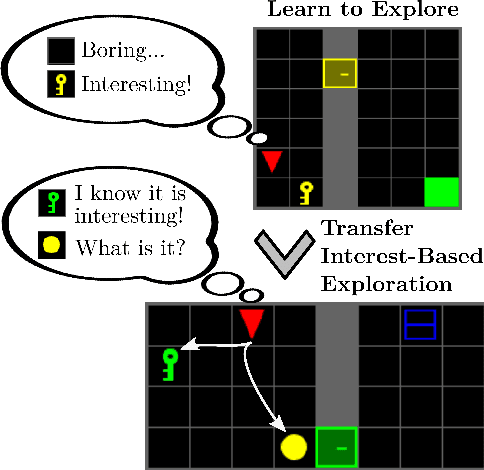

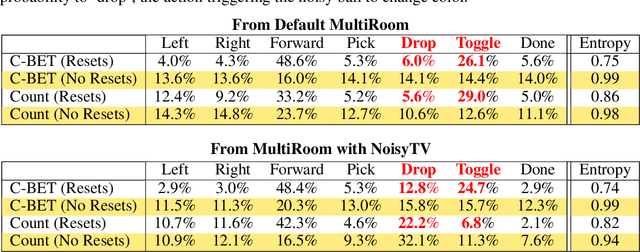
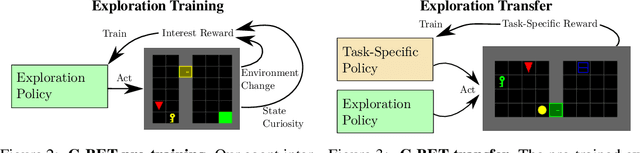
Common approaches for task-agnostic exploration learn tabula-rasa --the agent assumes isolated environments and no prior knowledge or experience. However, in the real world, agents learn in many environments and always come with prior experiences as they explore new ones. Exploration is a lifelong process. In this paper, we propose a paradigm change in the formulation and evaluation of task-agnostic exploration. In this setup, the agent first learns to explore across many environments without any extrinsic goal in a task-agnostic manner. Later on, the agent effectively transfers the learned exploration policy to better explore new environments when solving tasks. In this context, we evaluate several baseline exploration strategies and present a simple yet effective approach to learning task-agnostic exploration policies. Our key idea is that there are two components of exploration: (1) an agent-centric component encouraging exploration of unseen parts of the environment based on an agent's belief; (2) an environment-centric component encouraging exploration of inherently interesting objects. We show that our formulation is effective and provides the most consistent exploration across several training-testing environment pairs. We also introduce benchmarks and metrics for evaluating task-agnostic exploration strategies. The source code is available at https://github.com/sparisi/cbet/.
See, Hear, Explore: Curiosity via Audio-Visual Association
Jul 07, 2020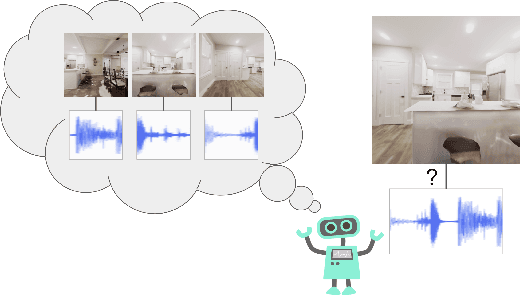
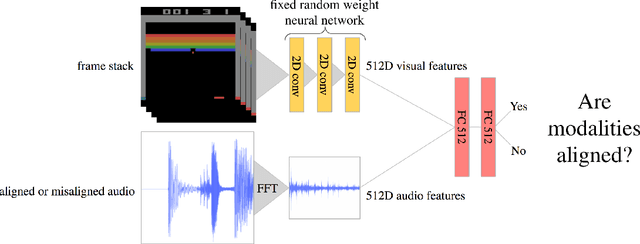
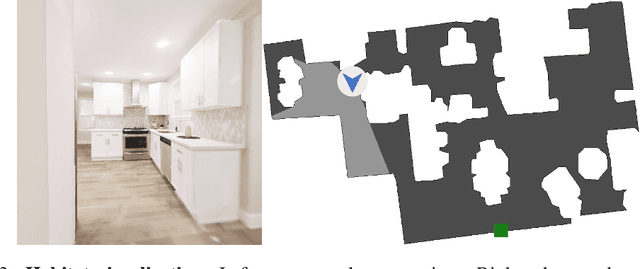
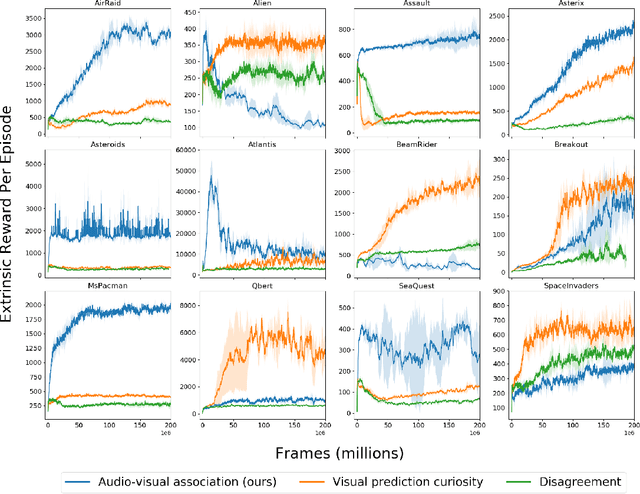
Exploration is one of the core challenges in reinforcement learning. A common formulation of curiosity-driven exploration uses the difference between the real future and the future predicted by a learned model. However, predicting the future is an inherently difficult task which can be ill-posed in the face of stochasticity. In this paper, we introduce an alternative form of curiosity that rewards novel associations between different senses. Our approach exploits multiple modalities to provide a stronger signal for more efficient exploration. Our method is inspired by the fact that, for humans, both sight and sound play a critical role in exploration. We present results on several Atari environments and Habitat (a photorealistic navigation simulator), showing the benefits of using an audio-visual association model for intrinsically guiding learning agents in the absence of external rewards. For videos and code, see https://vdean.github.io/audio-curiosity.html.