 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-MPO: On-Policy Maximum a Posteriori Policy Optimization for Discrete and Continuous Control
Sep 26, 2019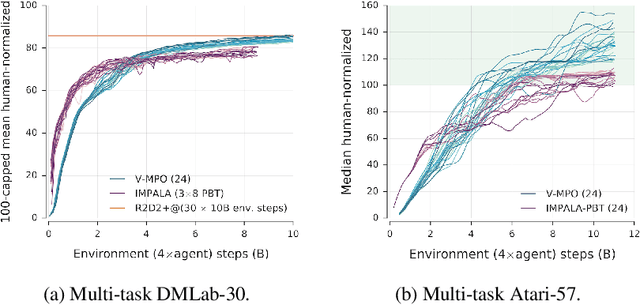
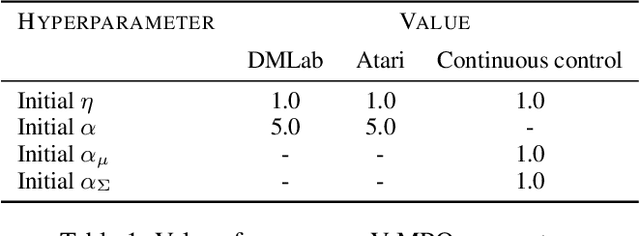
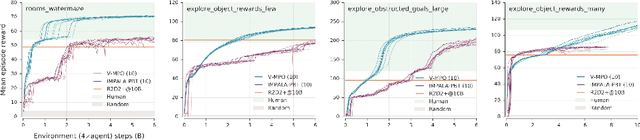

Some of the most successful applications of deep reinforcement learning to challenging domains in discrete and continuous control have used policy gradient methods in the on-policy setting. However, policy gradients can suffer from large variance that may limit performance, and in practice require carefully tuned entropy regularization to prevent policy collapse. As an alternative to policy gradient algorithms, we introduce V-MPO, an on-policy adaptation of Maximum a Posteriori Policy Optimization (MPO) that performs policy iteration based on a learned state-value function. We show that V-MPO surpasses previously reported scores for both the Atari-57 and DMLab-30 benchmark suites in the multi-task setting, and does so reliably without importance weighting, entropy regularization, or population-based tuning of hyperparameters. On individual DMLab and Atari levels, the proposed algorithm can achieve scores that are substantially higher than has previously been reported. V-MPO is also applicable to problems with high-dimensional, continuous action spaces, which we demonstrate in the context of learning to control simulated humanoids with 22 degrees of freedom from full state observations and 56 degrees of freedom from pixel observations, as well as example OpenAI Gym tasks where V-MPO achieves substantially higher asymptotic scores than previously reported.
Regularized Hierarchical Policies for Compositional Transfer in Robotics
Jun 27, 2019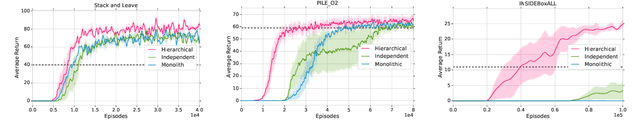

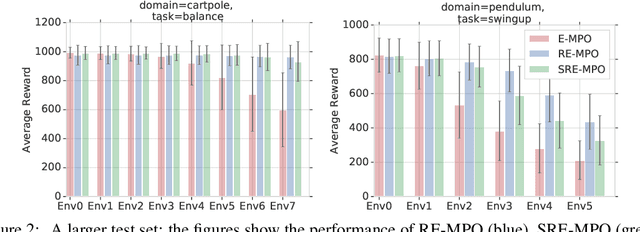
The successful application of flexible, general learning algorithms -- such as deep reinforcement learning -- to real-world robotics applications is often limited by their poor data-efficiency. Domains with more than a single dominant task of interest encourage algorithms that share partial solutions across tasks to limit the required experiment time. We develop and investigate simple hierarchical inductive biases -- in the form of structured policies -- as a mechanism for knowledge transfer across tasks in reinforcement learning (RL). To leverage the power of these structured policies we design an RL algorithm that enables stable and fast learning. We demonstrate the success of our method both in simulated robot environments (using locomotion and manipulation domains) as well as real robot experiments, demonstrating substantially better data-efficiency than competitive baselines.
Robust Reinforcement Learning for Continuous Control with Model Misspecification
Jun 18, 2019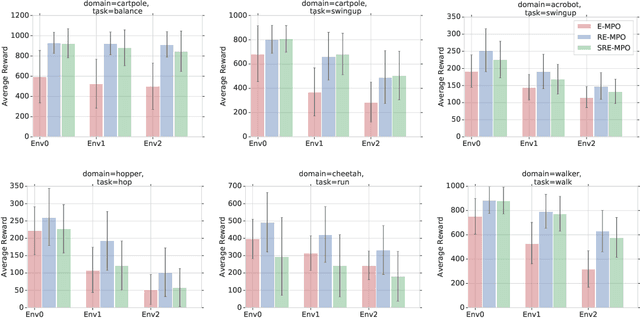

We provide a framework for incorporating robustness -- to perturbations in the transition dynamics which we refer to as model misspecification -- into continuous control Reinforcement Learning (RL) algorithms. We specifically focus on incorporating robustness into a state-of-the-art continuous control RL algorithm called Maximum a-posteriori Policy Optimization (MPO). We achieve this by learning a policy that optimizes for a worst case, entropy-regularized, expected return objective and derive a corresponding robust entropy-regularized Bellman contraction operator. In addition, we introduce a less conservative, soft-robust, entropy-regularized objective with a corresponding Bellman operator. We show that both, robust and soft-robust policies, outperform their non-robust counterparts in nine Mujoco domains with environment perturbations. Finally, we present multiple investigative experiments that provide a deeper insight into the robustness framework; including an adaptation to another continuous control RL algorithm as well as comparing this approach to domain randomization. Performance videos can be found online at https://sites.google.com/view/robust-rl.
Simultaneously Learning Vision and Feature-based Control Policies for Real-world Ball-in-a-Cup
Feb 18, 2019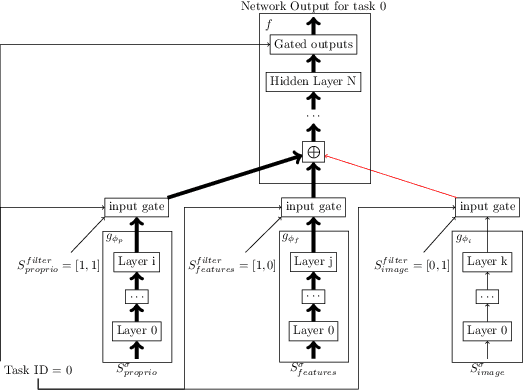

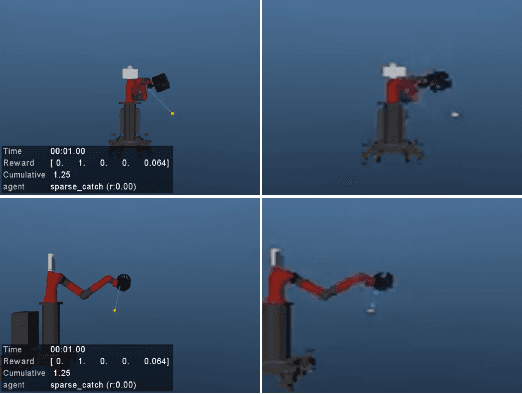

We present a method for fast training of vision based control policies on real robots. The key idea behind our method is to perform multi-task Reinforcement Learning with auxiliary tasks that differ not only in the reward to be optimized but also in the state-space in which they operate. In particular, we allow auxiliary task policies to utilize task features that are available only at training-time. This allows for fast learning of auxiliary policies, which subsequently generate good data for training the main, vision-based control policies. This method can be seen as an extension of the Scheduled Auxiliary Control (SAC-X) framework. We demonstrate the efficacy of our method by using both a simulated and real-world Ball-in-a-Cup game controlled by a robot arm. In simulation, our approach leads to significant learning speed-ups when compared to standard SAC-X. On the real robot we show that the task can be learned from-scratch, i.e., with no transfer from simulation and no imitation learning. Videos of our learned policies running on the real robot can be found at https://sites.google.com/view/rss-2019-sawyer-bic/.
Value constrained model-free continuous control
Feb 12, 2019
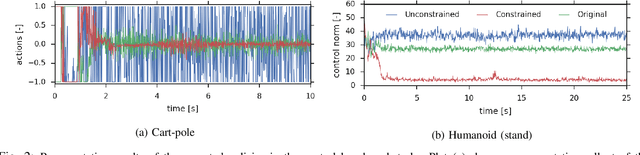

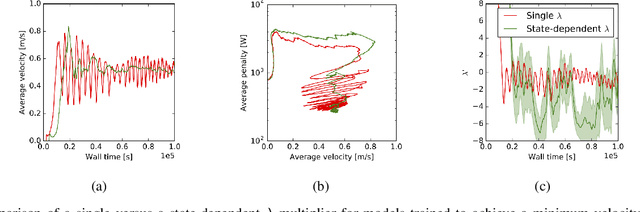
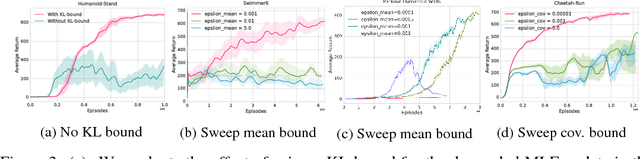
The naive application of Reinforcement Learning algorithms to continuous control problems -- such as locomotion and manipulation -- often results in policies which rely on high-amplitude, high-frequency control signals, known colloquially as bang-bang control. Although such solutions may indeed maximize task reward, they can be unsuitable for real world systems. Bang-bang control may lead to increased wear and tear or energy consumption, and tends to excite undesired second-order dynamics. To counteract this issue, multi-objective optimization can be used to simultaneously optimize both the reward and some auxiliary cost that discourages undesired (e.g. high-amplitude) control. In principle, such an approach can yield the sought after, smooth, control policies. It can, however, be hard to find the correct trade-off between cost and return that results in the desired behavior. In this paper we propose a new constraint-based reinforcement learning approach that ensures task success while minimizing one or more auxiliary costs (such as control effort). We employ Lagrangian relaxation to learn both (a) the parameters of a control policy that satisfies the desired constraints and (b) the Lagrangian multipliers for the optimization. Moreover, we demonstrate that we can satisfy constraints either in expectation or in a per-step fashion, and can even learn a single policy that is able to dynamically trade-off between return and cost. We demonstrate the efficacy of our approach using a number of continuous control benchmark tasks, a realistic, energy-optimized quadruped locomotion task, as well as a reaching task on a real robot arm.
Relative Entropy Regularized Policy Iteration
Dec 05, 2018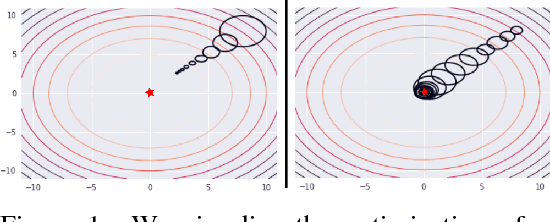
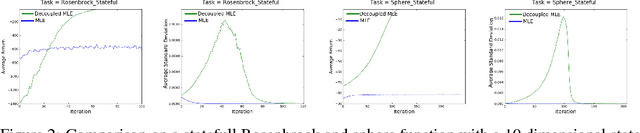

We present an off-policy actor-critic algorithm for Reinforcement Learning (RL) that combines ideas from gradient-free optimization via stochastic search with learned action-value function. The result is a simple procedure consisting of three steps: i) policy evaluation by estimating a parametric action-value function; ii) policy improvement via the estimation of a local non-parametric policy; and iii) generalization by fitting a parametric policy. Each step can be implemented in different ways, giving rise to several algorithm variants. Our algorithm draws on connections to existing literature on black-box optimization and 'RL as an inference' and it can be seen either as an extension of the Maximum a Posteriori Policy Optimisation algorithm (MPO) [Abdolmaleki et al., 2018a], or as an extension of Trust Region Covariance Matrix Adaptation Evolutionary Strategy (CMA-ES) [Abdolmaleki et al., 2017b; Hansen et al., 1997] to a policy iteration scheme. Our comparison on 31 continuous control tasks from parkour suite [Heess et al., 2017], DeepMind control suite [Tassa et al., 2018] and OpenAI Gym [Brockman et al., 2016] with diverse properties, limited amount of compute and a single set of hyperparameters, demonstrate the effectiveness of our method and the state of art results. Videos, summarizing results, can be found at goo.gl/HtvJKR .
Model-Free Trajectory-based Policy Optimization with Monotonic Improvement
Jul 02, 2018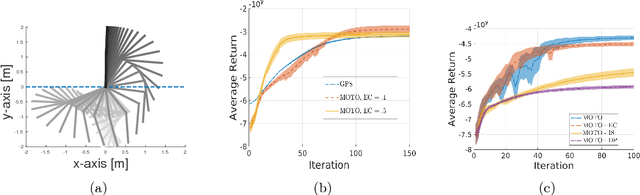
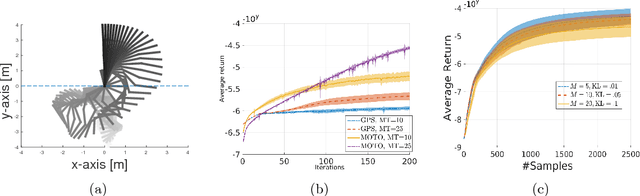
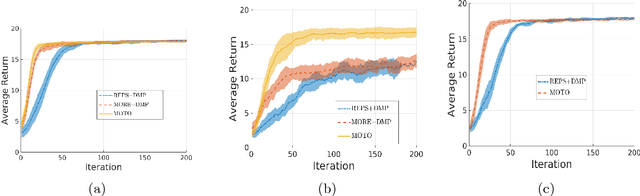
Many of the recent trajectory optimization algorithms alternate between linear approximation of the system dynamics around the mean trajectory and conservative policy update. One way of constraining the policy change is by bounding the Kullback-Leibler (KL) divergence between successive policies. These approaches already demonstrated great experimental success in challenging problems such as end-to-end control of physical systems. However, the linear approximation of the system dynamics can introduce a bias in the policy update and prevent convergence to the optimal policy. In this article, we propose a new model-free trajectory-based policy optimization algorithm with guaranteed monotonic improvement. The algorithm backpropagates a local, quadratic and time-dependent \qfunc~learned from trajectory data instead of a model of the system dynamics. Our policy update ensures exact KL-constraint satisfaction without simplifying assumptions on the system dynamics. We experimentally demonstrate on highly non-linear control tasks the improvement in performance of our algorithm in comparison to approaches linearizing the system dynamics. In order to show the monotonic improvement of our algorithm, we additionally conduct a theoretical analysis of our policy update scheme to derive a lower bound of the change in policy return between successive iterations.
Maximum a Posteriori Policy Optimisation
Jun 14, 2018
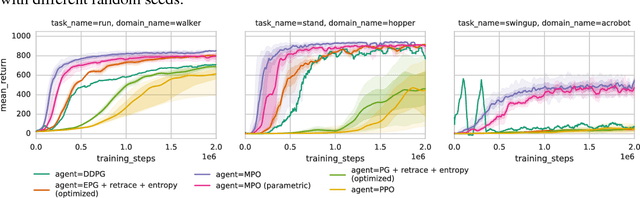
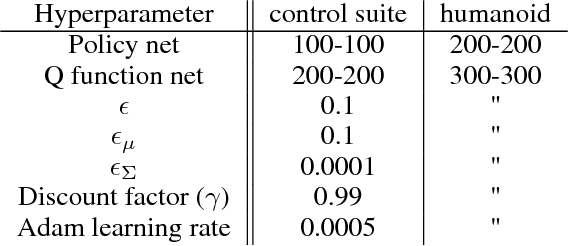
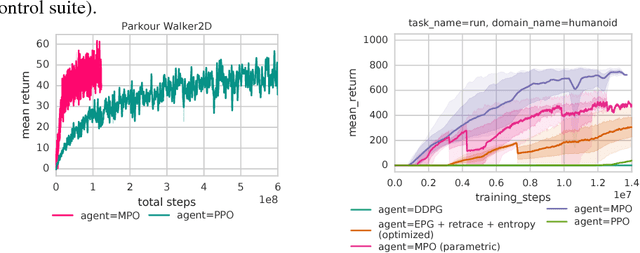
We introduce a new algorithm for reinforcement learning called Maximum aposteriori Policy Optimisation (MPO) based on coordinate ascent on a relative entropy objective. We show that several existing methods can directly be related to our derivation. We develop two off-policy algorithms and demonstrate that they are competitive with the state-of-the-art in deep reinforcement learning. In particular, for continuous control, our method outperforms existing methods with respect to sample efficiency, premature convergence and robustness to hyperparameter settings while achieving similar or better final performance.
Guide Actor-Critic for Continuous Control
Feb 22, 2018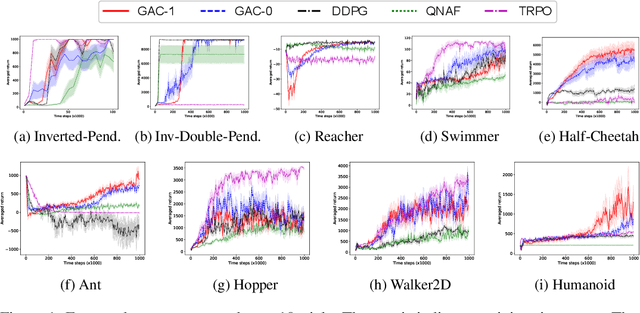
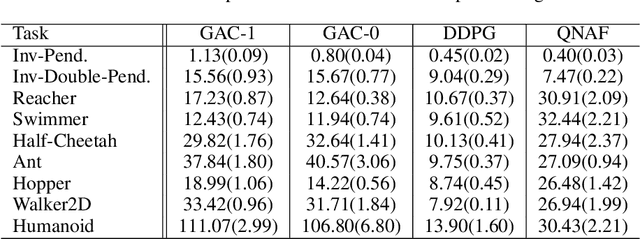
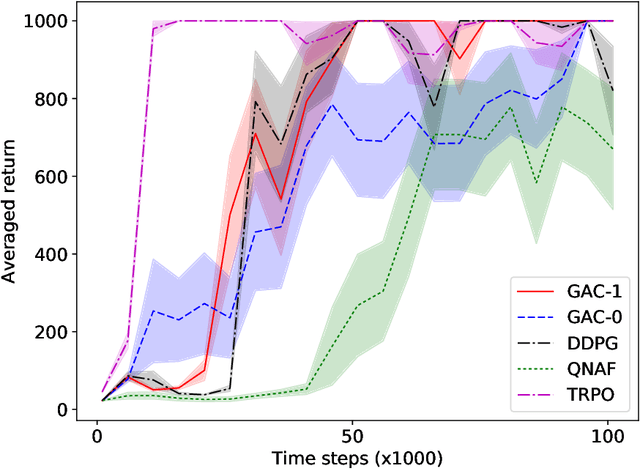
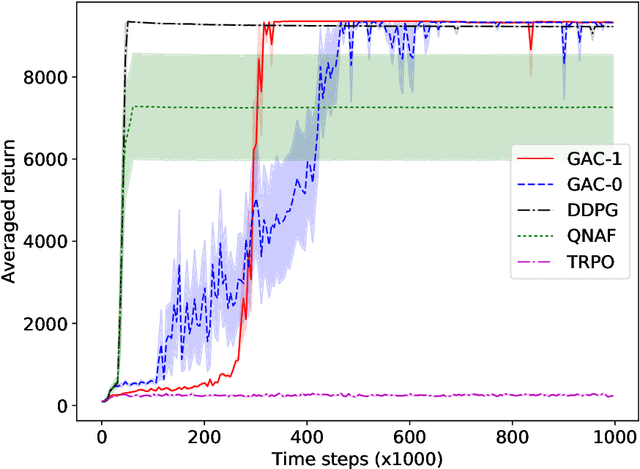
Actor-critic methods solve reinforcement learning problems by updating a parameterized policy known as an actor in a direction that increases an estimate of the expected return known as a critic. However, existing actor-critic methods only use values or gradients of the critic to update the policy parameter. In this paper, we propose a novel actor-critic method called the guide actor-critic (GAC). GAC firstly learns a guide actor that locally maximizes the critic and then it updates the policy parameter based on the guide actor by supervised learning. Our main theoretical contributions are two folds. First, we show that GAC updates the guide actor by performing second-order optimization in the action space where the curvature matrix is based on the Hessians of the critic. Second, we show that the deterministic policy gradient method is a special case of GAC when the Hessians are ignored. Through experiments, we show that our method is a promising reinforcement learning method for continuous controls.
DeepMind Control Suite
Jan 02, 2018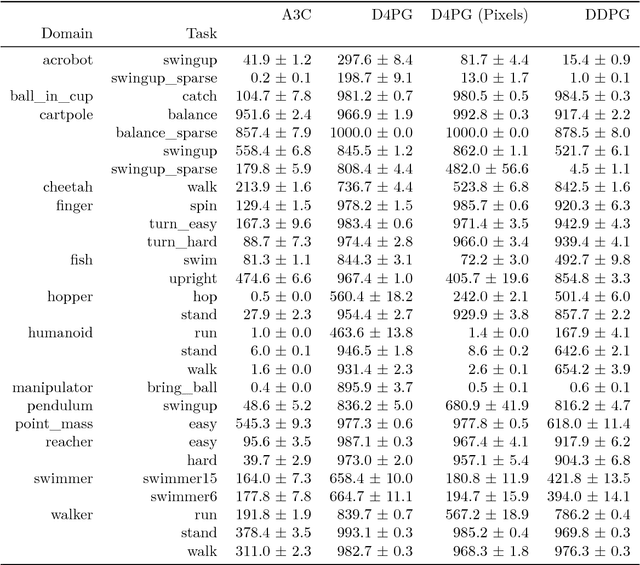
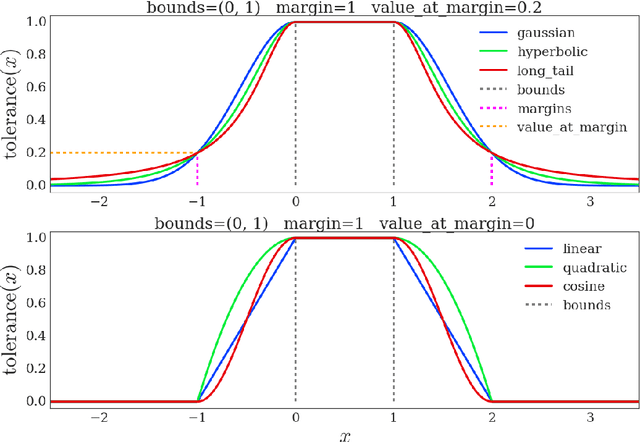
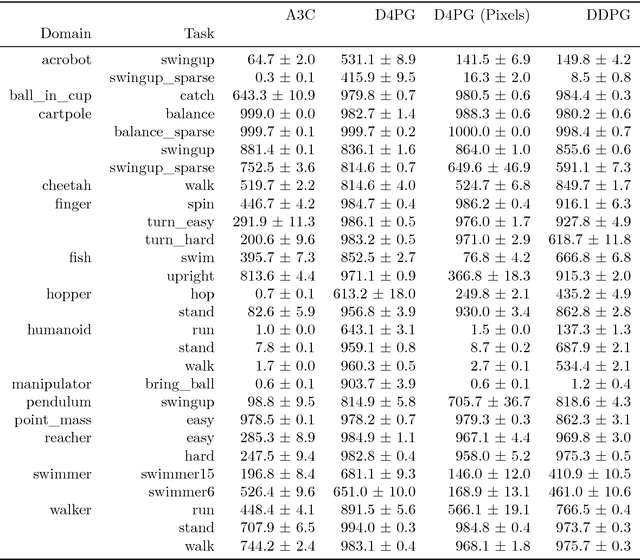
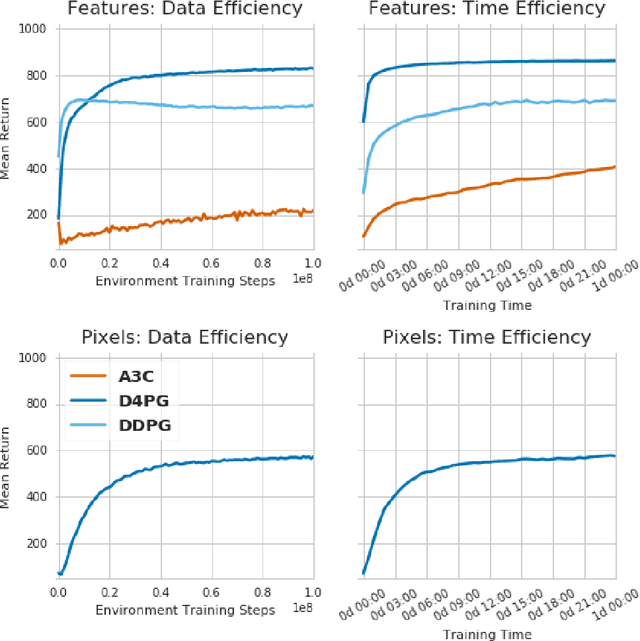
The DeepMind Control Suite is a set of continuous control tasks with a standardised structure and interpretable rewards, intended to serve as performance benchmarks for reinforcement learning agents. The tasks are written in Python and powered by the MuJoCo physics engine, making them easy to use and modify. We include benchmarks for several learning algorithms. The Control Suite is publicly available at https://www.github.com/deepmind/dm_control . A video summary of all tasks is available at http://youtu.be/rAai4QzcYbs .