 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Gradient Guidance of Flow Policies in Reinforcement Learning
Jun 09, 2026Expressive continuous control policies, such as diffusion and flow models, form the backbone of recent advances in scaling imitation learning for simulated and real robot control. While they are known to scale stably in the supervised imitation learning setting, incorporating them into reinforcement learning (RL) pipelines for policy improvement has proven more difficult. It often requires specialized training objectives or backpropagating through denoising processes, which cause well-known issues with stability and affect scalability. In this paper we study the question of whether simple policy improvement schemes at test time alone, leaving stable supervised policy training intact, can be a competitive alternative which sidesteps these issues. To this end, we propose QGF (Q-Guided Flow), an RL algorithm that performs policy optimization entirely at test time. QGF works by pre-training both a reference flow policy (via a standard behavioral cloning objective) and a value function critic and, at test time, using the value gradient to guide the reference policy to generate higher-value actions without any additional policy learning. Empirically, QGF outperforms prior test-time RL methods on single-task and goal-conditioned offline RL benchmarks with high-dimensional action spaces, and is competitive with state-of-the-art training-time algorithms while being much cheaper to run. Moreover, it exhibits favorable scaling with model size by avoiding the instability of actor-critic training, offering a practical and effective alternative RL algorithm with expressive policies.
Simultaneously Learning Vision and Feature-based Control Policies for Real-world Ball-in-a-Cup
Feb 18, 2019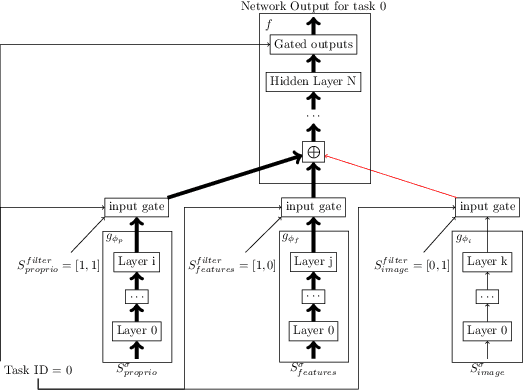

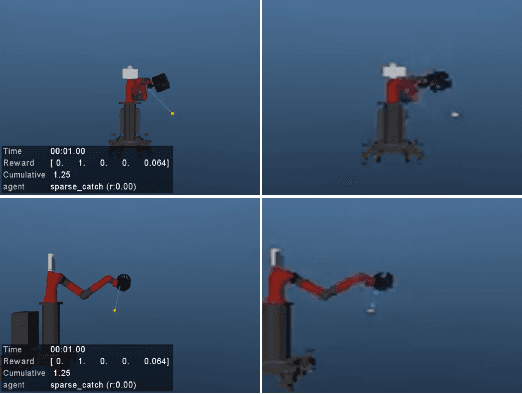

We present a method for fast training of vision based control policies on real robots. The key idea behind our method is to perform multi-task Reinforcement Learning with auxiliary tasks that differ not only in the reward to be optimized but also in the state-space in which they operate. In particular, we allow auxiliary task policies to utilize task features that are available only at training-time. This allows for fast learning of auxiliary policies, which subsequently generate good data for training the main, vision-based control policies. This method can be seen as an extension of the Scheduled Auxiliary Control (SAC-X) framework. We demonstrate the efficacy of our method by using both a simulated and real-world Ball-in-a-Cup game controlled by a robot arm. In simulation, our approach leads to significant learning speed-ups when compared to standard SAC-X. On the real robot we show that the task can be learned from-scratch, i.e., with no transfer from simulation and no imitation learning. Videos of our learned policies running on the real robot can be found at https://sites.google.com/view/rss-2019-sawyer-bic/.