 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Efficient Deep Speech Understanding at the Edge
Nov 22, 2023
Contemporary Speech Understanding (SU) involves a sophisticated pipeline: capturing real-time voice input, the pipeline encompasses a deep neural network with an encoder-decoder architecture enhanced by beam search. This network periodically assesses attention and Connectionist Temporal Classification (CTC) scores in its autoregressive output. This paper aims to enhance SU performance on edge devices with limited resources. It pursues two intertwined goals: accelerating on-device execution and efficiently handling inputs that surpass the on-device model's capacity. While these objectives are well-established, we introduce innovative solutions that specifically address SU's distinctive challenges: 1. Late contextualization: Enables the parallel execution of a model's attentive encoder during input ingestion. 2. Pilot decoding: Alleviates temporal load imbalances. 3. Autoregression offramps: Facilitate offloading decisions based on partial output sequences. Our techniques seamlessly integrate with existing SU models, pipelines, and frameworks, allowing for independent or combined application. Together, they constitute a hybrid solution for edge SU, exemplified by our prototype, XYZ. Evaluated on platforms equipped with 6-8 Arm cores, our system achieves State-of-the-Art (SOTA) accuracy, reducing end-to-end latency by 2x and halving offloading requirements.
Improving Label Assignments Learning by Dynamic Sample Dropout Combined with Layer-wise Optimization in Speech Separation
Nov 20, 2023In supervised speech separation, permutation invariant training (PIT) is widely used to handle label ambiguity by selecting the best permutation to update the model. Despite its success, previous studies showed that PIT is plagued by excessive label assignment switching in adjacent epochs, impeding the model to learn better label assignments. To address this issue, we propose a novel training strategy, dynamic sample dropout (DSD), which considers previous best label assignments and evaluation metrics to exclude the samples that may negatively impact the learned label assignments during training. Additionally, we include layer-wise optimization (LO) to improve the performance by solving layer-decoupling. Our experiments showed that combining DSD and LO outperforms the baseline and solves excessive label assignment switching and layer-decoupling issues. The proposed DSD and LO approach is easy to implement, requires no extra training sets or steps, and shows generality to various speech separation tasks.
GhostVec: A New Threat to Speaker Privacy of End-to-End Speech Recognition System
Nov 17, 2023Speaker adaptation systems face privacy concerns, for such systems are trained on private datasets and often overfitting. This paper demonstrates that an attacker can extract speaker information by querying speaker-adapted speech recognition (ASR) systems. We focus on the speaker information of a transformer-based ASR and propose GhostVec, a simple and efficient attack method to extract the speaker information from an encoder-decoder-based ASR system without any external speaker verification system or natural human voice as a reference. To make our results quantitative, we pre-process GhostVec using singular value decomposition (SVD) and synthesize it into waveform. Experiment results show that the synthesized audio of GhostVec reaches 10.83\% EER and 0.47 minDCF with target speakers, which suggests the effectiveness of the proposed method. We hope the preliminary discovery in this study to catalyze future speech recognition research on privacy-preserving topics.
Evaluating Speech Synthesis by Training Recognizers on Synthetic Speech
Oct 01, 2023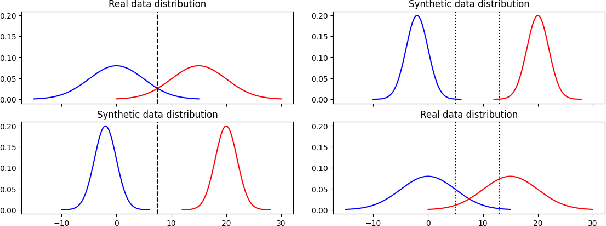
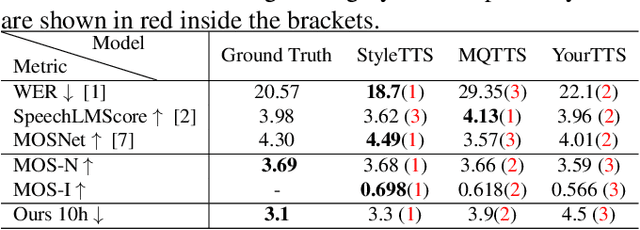
Modern speech synthesis systems have improved significantly, with synthetic speech being indistinguishable from real speech. However, efficient and holistic evaluation of synthetic speech still remains a significant challenge. Human evaluation using Mean Opinion Score (MOS) is ideal, but inefficient due to high costs. Therefore, researchers have developed auxiliary automatic metrics like Word Error Rate (WER) to measure intelligibility. Prior works focus on evaluating synthetic speech based on pre-trained speech recognition models, however, this can be limiting since this approach primarily measures speech intelligibility. In this paper, we propose an evaluation technique involving the training of an ASR model on synthetic speech and assessing its performance on real speech. Our main assumption is that by training the ASR model on the synthetic speech, the WER on real speech reflects the similarity between distributions, a broader assessment of synthetic speech quality beyond intelligibility. Our proposed metric demonstrates a strong correlation with both MOS naturalness and MOS intelligibility when compared to SpeechLMScore and MOSNet on three recent Text-to-Speech (TTS) systems: MQTTS, StyleTTS, and YourTTS.
Towards Real-World Streaming Speech Translation for Code-Switched Speech
Oct 19, 2023Code-switching (CS), i.e. mixing different languages in a single sentence, is a common phenomenon in communication and can be challenging in many Natural Language Processing (NLP) settings. Previous studies on CS speech have shown promising results for end-to-end speech translation (ST), but have been limited to offline scenarios and to translation to one of the languages present in the source (\textit{monolingual transcription}). In this paper, we focus on two essential yet unexplored areas for real-world CS speech translation: streaming settings, and translation to a third language (i.e., a language not included in the source). To this end, we extend the Fisher and Miami test and validation datasets to include new targets in Spanish and German. Using this data, we train a model for both offline and streaming ST and we establish baseline results for the two settings mentioned earlier.
Towards a Deep Understanding of Multilingual End-to-End Speech Translation
Oct 31, 2023In this paper, we employ Singular Value Canonical Correlation Analysis (SVCCA) to analyze representations learnt in a multilingual end-to-end speech translation model trained over 22 languages. SVCCA enables us to estimate representational similarity across languages and layers, enhancing our understanding of the functionality of multilingual speech translation and its potential connection to multilingual neural machine translation. The multilingual speech translation model is trained on the CoVoST 2 dataset in all possible directions, and we utilize LASER to extract parallel bitext data for SVCCA analysis. We derive three major findings from our analysis: (I) Linguistic similarity loses its efficacy in multilingual speech translation when the training data for a specific language is limited. (II) Enhanced encoder representations and well-aligned audio-text data significantly improve translation quality, surpassing the bilingual counterparts when the training data is not compromised. (III) The encoder representations of multilingual speech translation demonstrate superior performance in predicting phonetic features in linguistic typology prediction. With these findings, we propose that releasing the constraint of limited data for low-resource languages and subsequently combining them with linguistically related high-resource languages could offer a more effective approach for multilingual end-to-end speech translation.
SALM: Speech-augmented Language Model with In-context Learning for Speech Recognition and Translation
Oct 13, 2023We present a novel Speech Augmented Language Model (SALM) with {\em multitask} and {\em in-context} learning capabilities. SALM comprises a frozen text LLM, a audio encoder, a modality adapter module, and LoRA layers to accommodate speech input and associated task instructions. The unified SALM not only achieves performance on par with task-specific Conformer baselines for Automatic Speech Recognition (ASR) and Speech Translation (AST), but also exhibits zero-shot in-context learning capabilities, demonstrated through keyword-boosting task for ASR and AST. Moreover, {\em speech supervised in-context training} is proposed to bridge the gap between LLM training and downstream speech tasks, which further boosts the in-context learning ability of speech-to-text models. Proposed model is open-sourced via NeMo toolkit.
SEF-VC: Speaker Embedding Free Zero-Shot Voice Conversion with Cross Attention
Dec 14, 2023Zero-shot voice conversion (VC) aims to transfer the source speaker timbre to arbitrary unseen target speaker timbre, while keeping the linguistic content unchanged. Although the voice of generated speech can be controlled by providing the speaker embedding of the target speaker, the speaker similarity still lags behind the ground truth recordings. In this paper, we propose SEF-VC, a speaker embedding free voice conversion model, which is designed to learn and incorporate speaker timbre from reference speech via a powerful position-agnostic cross-attention mechanism, and then reconstruct waveform from HuBERT semantic tokens in a non-autoregressive manner. The concise design of SEF-VC enhances its training stability and voice conversion performance. Objective and subjective evaluations demonstrate the superiority of SEF-VC to generate high-quality speech with better similarity to target reference than strong zero-shot VC baselines, even for very short reference speeches.
Decoupling and Interacting Multi-Task Learning Network for Joint Speech and Accent Recognition
Nov 17, 2023Accents, as variations from standard pronunciation, pose significant challenges for speech recognition systems. Although joint automatic speech recognition (ASR) and accent recognition (AR) training has been proven effective in handling multi-accent scenarios, current multi-task ASR-AR approaches overlook the granularity differences between tasks. Fine-grained units capture pronunciation-related accent characteristics, while coarse-grained units are better for learning linguistic information. Moreover, an explicit interaction of two tasks can also provide complementary information and improve the performance of each other, but it is rarely used by existing approaches. In this paper, we propose a novel Decoupling and Interacting Multi-task Network (DIMNet) for joint speech and accent recognition, which is comprised of a connectionist temporal classification (CTC) branch, an AR branch, an ASR branch, and a bottom feature encoder. Specifically, AR and ASR are first decoupled by separated branches and two-granular modeling units to learn task-specific representations. The AR branch is from our previously proposed linguistic-acoustic bimodal AR model and the ASR branch is an encoder-decoder based Conformer model. Then, for the task interaction, the CTC branch provides aligned text for the AR task, while accent embeddings extracted from our AR model are incorporated into the ASR branch's encoder and decoder. Finally, during ASR inference, a cross-granular rescoring method is introduced to fuse the complementary information from the CTC and attention decoder after the decoupling. Our experiments on English and Chinese datasets demonstrate the effectiveness of the proposed model, which achieves 21.45%/28.53% AR accuracy relative improvement and 32.33%/14.55% ASR error rate relative reduction over a published standard baseline, respectively.
GOAT-Bench: Safety Insights to Large Multimodal Models through Meme-Based Social Abuse
Jan 03, 2024The exponential growth of social media has profoundly transformed how information is created, disseminated, and absorbed, exceeding any precedent in the digital age. Regrettably, this explosion has also spawned a significant increase in the online abuse of memes. Evaluating the negative impact of memes is notably challenging, owing to their often subtle and implicit meanings, which are not directly conveyed through the overt text and imagery. In light of this, large multimodal models (LMMs) have emerged as a focal point of interest due to their remarkable capabilities in handling diverse multimodal tasks. In response to this development, our paper aims to thoroughly examine the capacity of various LMMs (e.g. GPT-4V) to discern and respond to the nuanced aspects of social abuse manifested in memes. We introduce the comprehensive meme benchmark, GOAT-Bench, comprising over 6K varied memes encapsulating themes such as implicit hate speech, sexism, and cyberbullying, etc. Utilizing GOAT-Bench, we delve into the ability of LMMs to accurately assess hatefulness, misogyny, offensiveness, sarcasm, and harmful content. Our extensive experiments across a range of LMMs reveal that current models still exhibit a deficiency in safety awareness, showing insensitivity to various forms of implicit abuse. We posit that this shortfall represents a critical impediment to the realization of safe artificial intelligence. The GOAT-Bench and accompanying resources are publicly accessible at https://goatlmm.github.io/, contributing to ongoing research in this vital field.