 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Retrieval for Stable and Predictable Ad Recommendations
May 21, 2026Traditional ads recommendation systems have primarily focused on optimizing for prediction accuracy of click or conversion events using canonical metrics such as recall or normalized discounted cumulative gain (NDCG). With the hyper-growth of ads inventory and liquidity with generative AI technologies, the prediction stability and predictability is becoming increasingly critical. Intuitively, prediction stability and predictability can be defined to quantify system robustness with respect to minor/noisy input (ads, creatives) perturbations, the lack of which could lead to advertiser perceivable problems such as repeatability, cold start and under-exploration. In this paper, we introduce a new evaluation framework for quantifying stability and predictability of an ads recommender system, and present an online validated semantic candidate generation framework powered by fine-tuned Large Language Models (LLMs) that showed significant improvement along these metrics by fundamentally improving the semantic-awareness of the system. The approach extracts hierarchical semantic attributes from ad creatives to obtain LLM representations, which serve as the foundation for graph-based expansion, ensuring the retrieved candidates encapsulate semantic variants of an ad, guaranteeing that small creative variants from the advertiser yield consistent and explainable delivery results to the user. We tested this LLM ads retrieval framework in a large-scale industrial ads recommendation system, demonstrating significant improvements across offline and online A/B experiments, showcasing gains in both predictability and traditional performance metrics. Although evaluated in the ads stack, this is a general framework that can be applied broadly to any large-scale recommendation and retrieval systems facing similar scaling and predictability challenges.
Code-as-Room: Generating 3D Rooms from Top-Down View Images via Agentic Code Synthesis
May 18, 2026Designing realistic and functional 3D indoor rooms is essential for a wide range of applications, including interior design, virtual reality, gaming, and embodied AI. While recent MLLM-based approaches have shown great potential for 3D room synthesis from textual descriptions or reference images, text-based methods struggle to capture precise spatial information, and existing image-conditioned agents suffer from instability and infinite looping when tasked with holistic room generation from top-down views. To address these limitations, we propose Code-as-Room, an MLLM-based agentic framework equipped with a structured execution harness, which represents 3D rooms with Blender codes. Given a top-down room image, the framework parses the reference image to extract scene elements and their spatial relationships, and synthesizes executable Blender code for geometry, materials, and lighting in a principled, multi-stage pipeline. A cross-stage memory module is maintained throughout to mitigate context forgetting inherent to existing agent-based frameworks. We further introduce a dedicated benchmark for code-based 3D room synthesis, encompassing various evaluation protocols. Based on our benchmark, comprehensive comparisons against existing agent-based methods are conducted to validate the effectiveness of our proposed execution harness.
Decoupling and Interacting Multi-Task Learning Network for Joint Speech and Accent Recognition
Nov 17, 2023



Accents, as variations from standard pronunciation, pose significant challenges for speech recognition systems. Although joint automatic speech recognition (ASR) and accent recognition (AR) training has been proven effective in handling multi-accent scenarios, current multi-task ASR-AR approaches overlook the granularity differences between tasks. Fine-grained units capture pronunciation-related accent characteristics, while coarse-grained units are better for learning linguistic information. Moreover, an explicit interaction of two tasks can also provide complementary information and improve the performance of each other, but it is rarely used by existing approaches. In this paper, we propose a novel Decoupling and Interacting Multi-task Network (DIMNet) for joint speech and accent recognition, which is comprised of a connectionist temporal classification (CTC) branch, an AR branch, an ASR branch, and a bottom feature encoder. Specifically, AR and ASR are first decoupled by separated branches and two-granular modeling units to learn task-specific representations. The AR branch is from our previously proposed linguistic-acoustic bimodal AR model and the ASR branch is an encoder-decoder based Conformer model. Then, for the task interaction, the CTC branch provides aligned text for the AR task, while accent embeddings extracted from our AR model are incorporated into the ASR branch's encoder and decoder. Finally, during ASR inference, a cross-granular rescoring method is introduced to fuse the complementary information from the CTC and attention decoder after the decoupling. Our experiments on English and Chinese datasets demonstrate the effectiveness of the proposed model, which achieves 21.45%/28.53% AR accuracy relative improvement and 32.33%/14.55% ASR error rate relative reduction over a published standard baseline, respectively.
Linguistic-Acoustic Similarity Based Accent Shift for Accent Recognition
Apr 07, 2022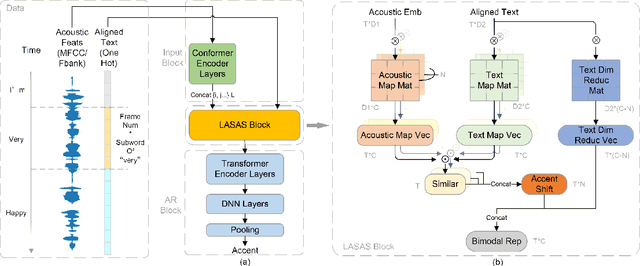
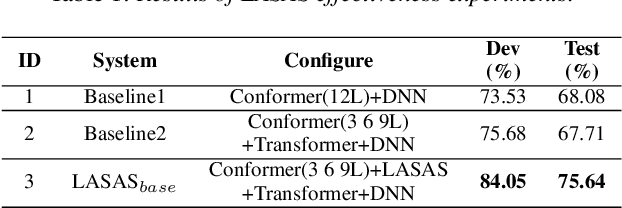
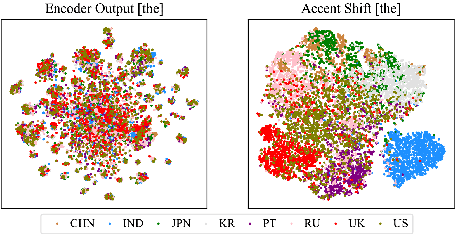
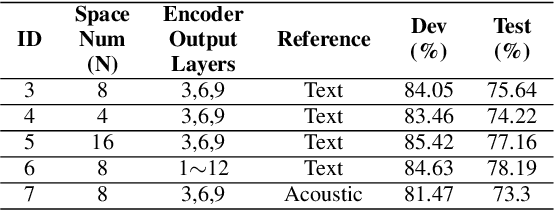
General accent recognition (AR) models tend to directly extract low-level information from spectrums, which always significantly overfit on speakers or channels. Considering accent can be regarded as a series of shifts relative to native pronunciation, distinguishing accents will be an easier task with accent shift as input. But due to the lack of native utterance as an anchor, estimating the accent shift is difficult. In this paper, we propose linguistic-acoustic similarity based accent shift (LASAS) for AR tasks. For an accent speech utterance, after mapping the corresponding text vector to multiple accent-associated spaces as anchors, its accent shift could be estimated by the similarities between the acoustic embedding and those anchors. Then, we concatenate the accent shift with a dimension-reduced text vector to obtain a linguistic-acoustic bimodal representation. Compared with pure acoustic embedding, the bimodal representation is richer and more clear by taking full advantage of both linguistic and acoustic information, which can effectively improve AR performance. Experiments on Accented English Speech Recognition Challenge (AESRC) dataset show that our method achieves 77.42% accuracy on Test set, obtaining a 6.94% relative improvement over a competitive system in the challenge.