 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
An Effective Transformer-based Contextual Model and Temporal Gate Pooling for Speaker Identification
Aug 22, 2023
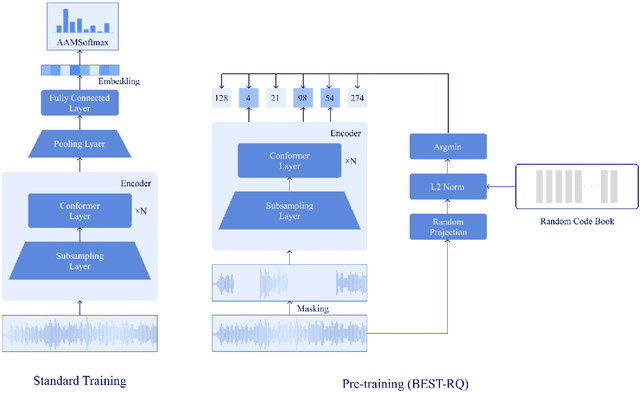
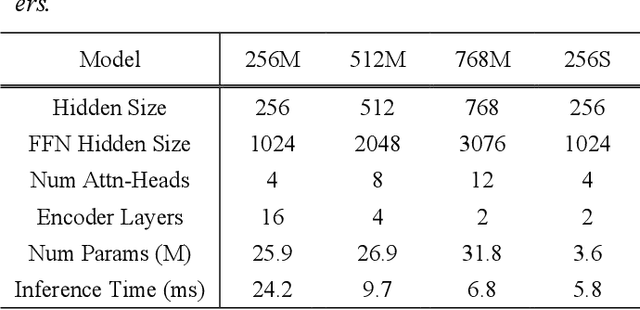
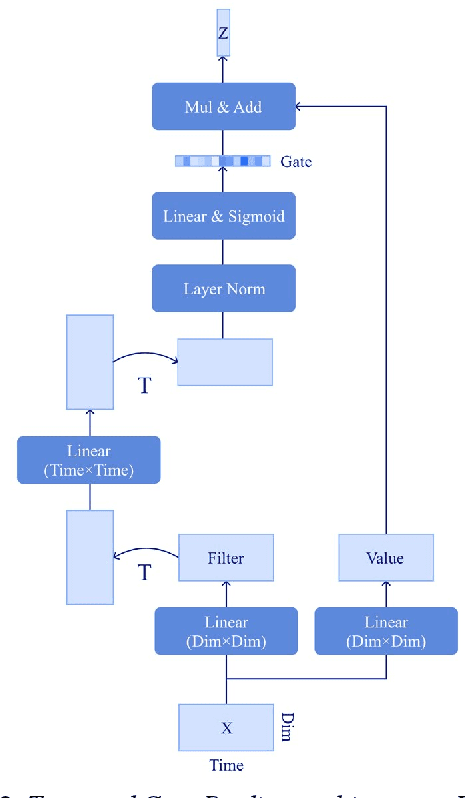
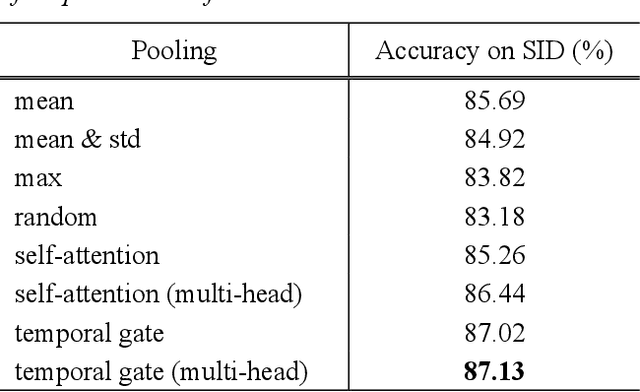
Wav2vec2 has achieved success in applying Transformer architecture and self-supervised learning to speech recognition. Recently, these have come to be used not only for speech recognition but also for the entire speech processing. This paper introduces an effective end-to-end speaker identification model applied Transformer-based contextual model. We explored the relationship between the parameters and the performance in order to discern the structure of an effective model. Furthermore, we propose a pooling method, Temporal Gate Pooling, with powerful learning ability for speaker identification. We applied Conformer as encoder and BEST-RQ for pre-training and conducted an evaluation utilizing the speaker identification of VoxCeleb1. The proposed method has achieved an accuracy of 85.9% with 28.5M parameters, demonstrating comparable precision to wav2vec2 with 317.7M parameters. Code is available at https://github.com/HarunoriKawano/speaker-identification-with-tgp.
GEmo-CLAP: Gender-Attribute-Enhanced Contrastive Language-Audio Pretraining for Speech Emotion Recognition
Jun 16, 2023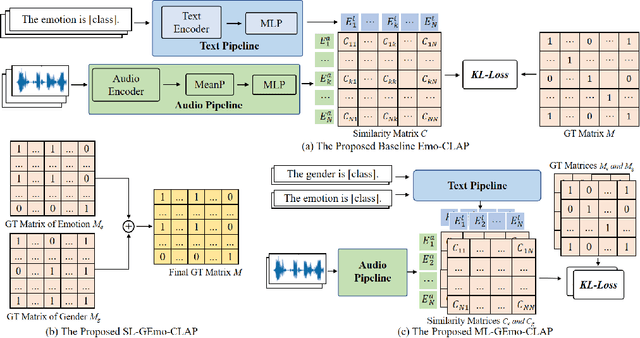
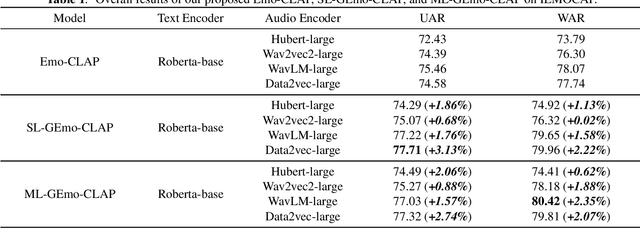
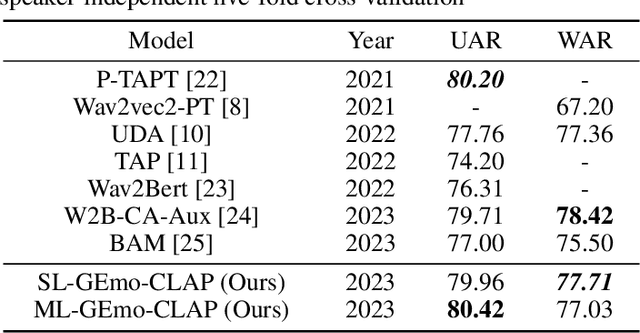
Contrastive learning based pretraining methods have recently exhibited impressive success in diverse fields. In this paper, we propose GEmo-CLAP, a kind of efficient gender-attribute-enhanced contrastive language-audio pretraining (CLAP) model for speech emotion recognition. To be specific, we first build an effective emotion CLAP model Emo-CLAP for emotion recognition, utilizing various self-supervised learning based pre-trained models. Then, considering the importance of the gender attribute in speech emotion modeling, two GEmo-CLAP approaches are further proposed to integrate the emotion and gender information of speech signals, forming more reasonable objectives. Extensive experiments on the IEMOCAP corpus demonstrate that our proposed two GEmo-CLAP approaches consistently outperform the baseline Emo-CLAP with different pre-trained models, while also achieving superior recognition performance compared with other state-of-the-art methods.
TRAVID: An End-to-End Video Translation Framework
Sep 20, 2023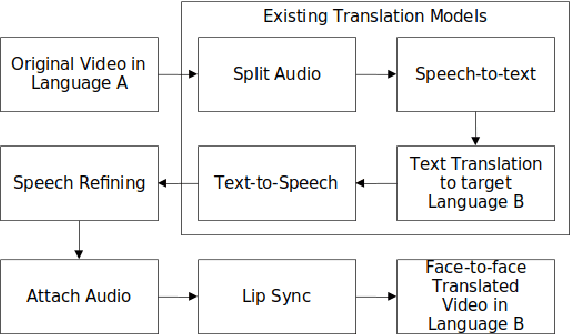
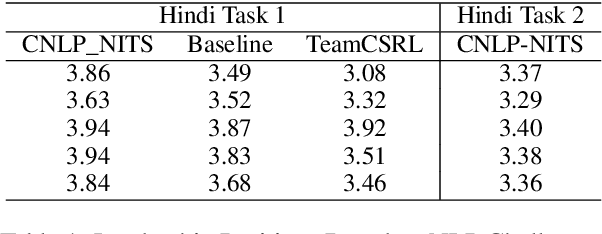
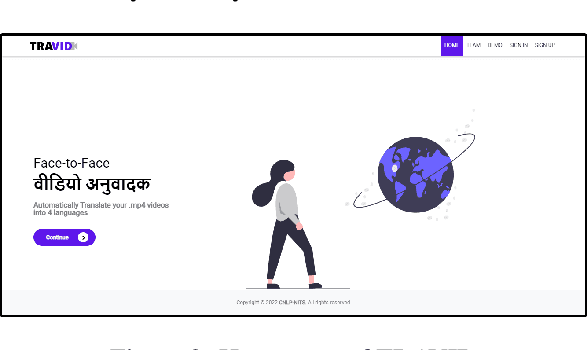

In today's globalized world, effective communication with people from diverse linguistic backgrounds has become increasingly crucial. While traditional methods of language translation, such as written text or voice-only translations, can accomplish the task, they often fail to capture the complete context and nuanced information conveyed through nonverbal cues like facial expressions and lip movements. In this paper, we present an end-to-end video translation system that not only translates spoken language but also synchronizes the translated speech with the lip movements of the speaker. Our system focuses on translating educational lectures in various Indian languages, and it is designed to be effective even in low-resource system settings. By incorporating lip movements that align with the target language and matching them with the speaker's voice using voice cloning techniques, our application offers an enhanced experience for students and users. This additional feature creates a more immersive and realistic learning environment, ultimately making the learning process more effective and engaging.
AV-SUPERB: A Multi-Task Evaluation Benchmark for Audio-Visual Representation Models
Sep 19, 2023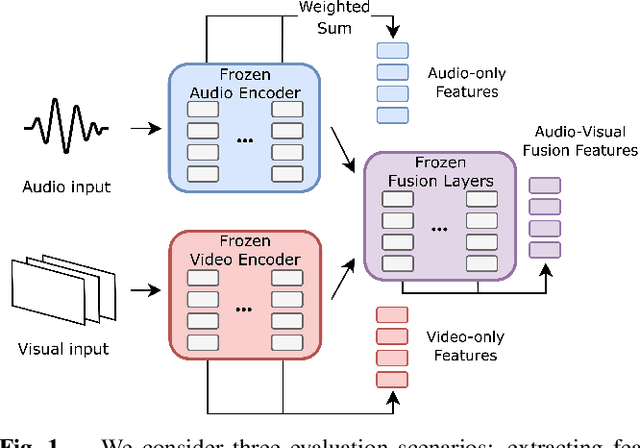
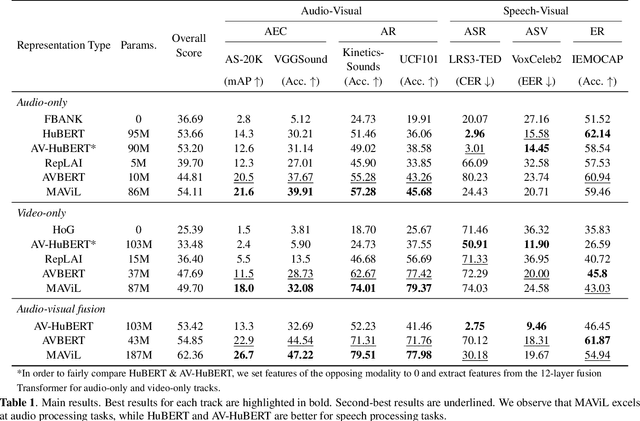
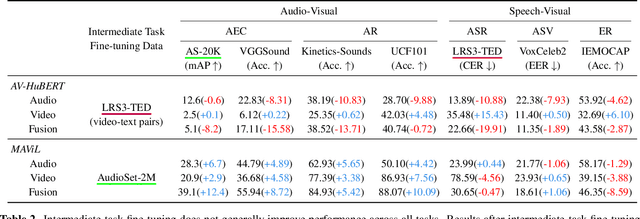
Audio-visual representation learning aims to develop systems with human-like perception by utilizing correlation between auditory and visual information. However, current models often focus on a limited set of tasks, and generalization abilities of learned representations are unclear. To this end, we propose the AV-SUPERB benchmark that enables general-purpose evaluation of unimodal audio/visual and bimodal fusion representations on 7 datasets covering 5 audio-visual tasks in speech and audio processing. We evaluate 5 recent self-supervised models and show that none of these models generalize to all tasks, emphasizing the need for future study on improving universal model performance. In addition, we show that representations may be improved with intermediate-task fine-tuning and audio event classification with AudioSet serves as a strong intermediate task. We release our benchmark with evaluation code and a model submission platform to encourage further research in audio-visual learning.
Multimodal Modeling For Spoken Language Identification
Sep 19, 2023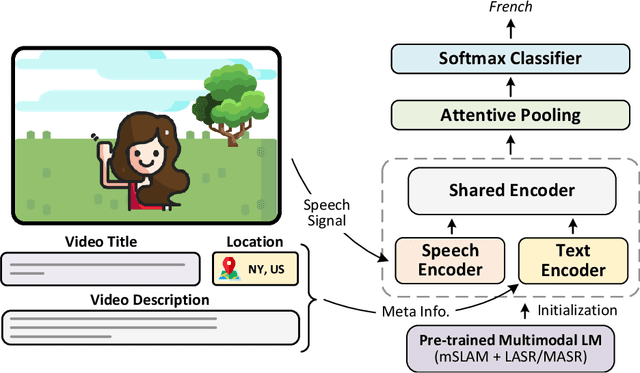
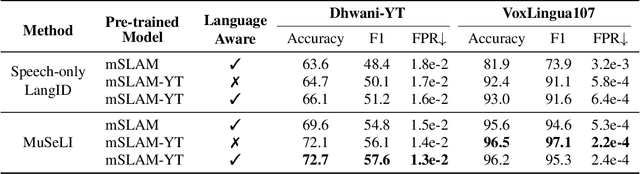
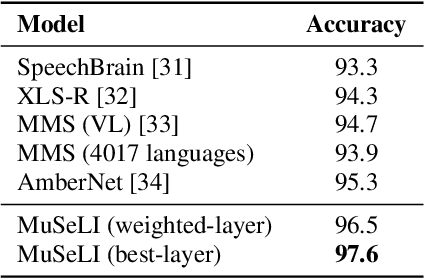
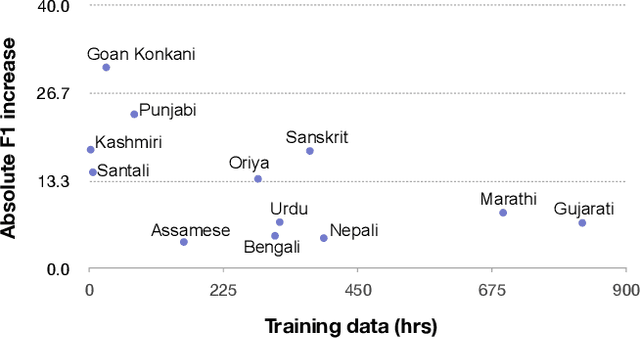
Spoken language identification refers to the task of automatically predicting the spoken language in a given utterance. Conventionally, it is modeled as a speech-based language identification task. Prior techniques have been constrained to a single modality; however in the case of video data there is a wealth of other metadata that may be beneficial for this task. In this work, we propose MuSeLI, a Multimodal Spoken Language Identification method, which delves into the use of various metadata sources to enhance language identification. Our study reveals that metadata such as video title, description and geographic location provide substantial information to identify the spoken language of the multimedia recording. We conduct experiments using two diverse public datasets of YouTube videos, and obtain state-of-the-art results on the language identification task. We additionally conduct an ablation study that describes the distinct contribution of each modality for language recognition.
Leveraging Pretrained ASR Encoders for Effective and Efficient End-to-End Speech Intent Classification and Slot Filling
Jul 13, 2023
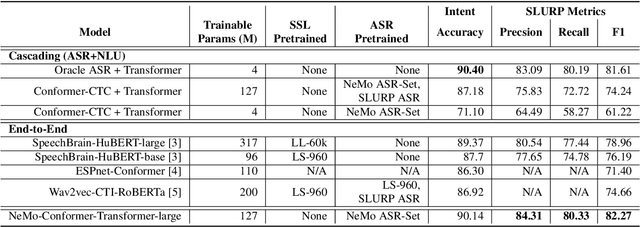

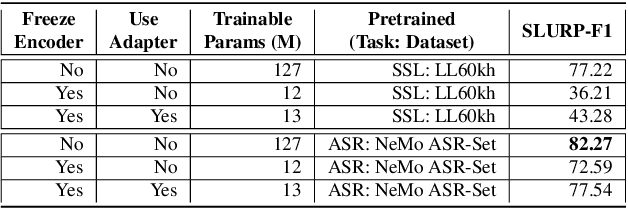
We study speech intent classification and slot filling (SICSF) by proposing to use an encoder pretrained on speech recognition (ASR) to initialize an end-to-end (E2E) Conformer-Transformer model, which achieves the new state-of-the-art results on the SLURP dataset, with 90.14% intent accuracy and 82.27% SLURP-F1. We compare our model with encoders pretrained on self-supervised learning (SSL), and show that ASR pretraining is much more effective than SSL for SICSF. To explore parameter efficiency, we freeze the encoder and add Adapter modules, and show that parameter efficiency is only achievable with an ASR-pretrained encoder, while the SSL encoder needs full finetuning to achieve comparable results. In addition, we provide an in-depth comparison on end-to-end models versus cascading models (ASR+NLU), and show that E2E models are better than cascaded models unless an oracle ASR model is provided. Last but not least, our model is the first E2E model that achieves the same performance as cascading models with oracle ASR. Code, checkpoints and configs are available.
SPEECH: Structured Prediction with Energy-Based Event-Centric Hyperspheres
May 26, 2023
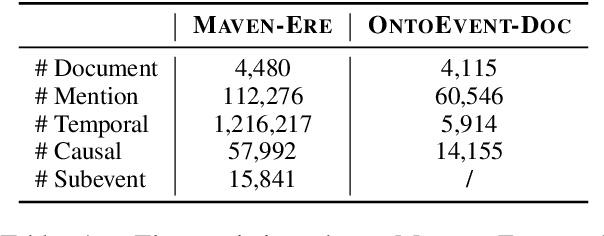
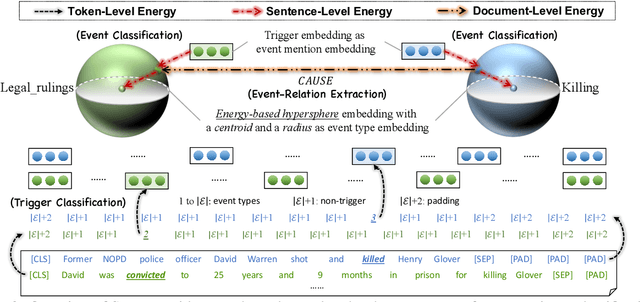
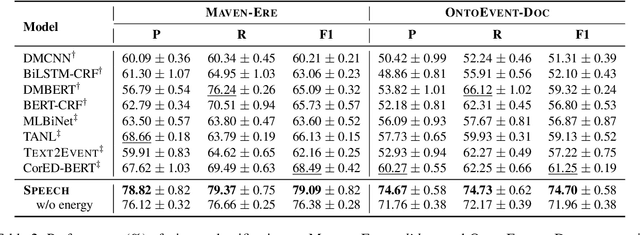
Event-centric structured prediction involves predicting structured outputs of events. In most NLP cases, event structures are complex with manifold dependency, and it is challenging to effectively represent these complicated structured events. To address these issues, we propose Structured Prediction with Energy-based Event-Centric Hyperspheres (SPEECH). SPEECH models complex dependency among event structured components with energy-based modeling, and represents event classes with simple but effective hyperspheres. Experiments on two unified-annotated event datasets indicate that SPEECH is predominant in event detection and event-relation extraction tasks.
Multi-Loss Convolutional Network with Time-Frequency Attention for Speech Enhancement
Jun 15, 2023
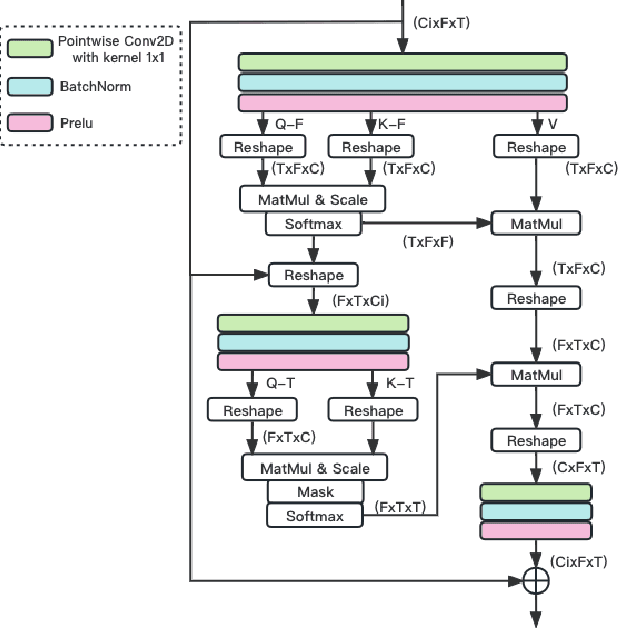
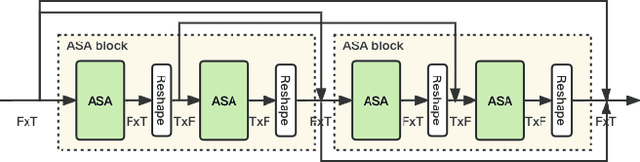
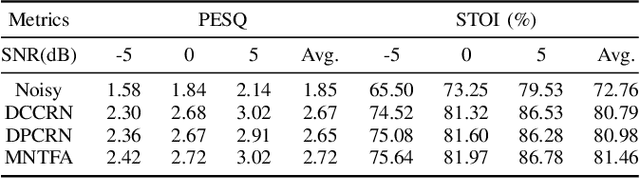
The Dual-Path Convolution Recurrent Network (DPCRN) was proposed to effectively exploit time-frequency domain information. By combining the DPRNN module with Convolution Recurrent Network (CRN), the DPCRN obtained a promising performance in speech separation with a limited model size. In this paper, we explore self-attention in the DPCRN module and design a model called Multi-Loss Convolutional Network with Time-Frequency Attention(MNTFA) for speech enhancement. We use self-attention modules to exploit the long-time information, where the intra-chunk self-attentions are used to model the spectrum pattern and the inter-chunk self-attention are used to model the dependence between consecutive frames. Compared to DPRNN, axial self-attention greatly reduces the need for memory and computation, which is more suitable for long sequences of speech signals. In addition, we propose a joint training method of a multi-resolution STFT loss and a WavLM loss using a pre-trained WavLM network. Experiments show that with only 0.23M parameters, the proposed model achieves a better performance than DPCRN.
Ripple sparse self-attention for monaural speech enhancement
May 15, 2023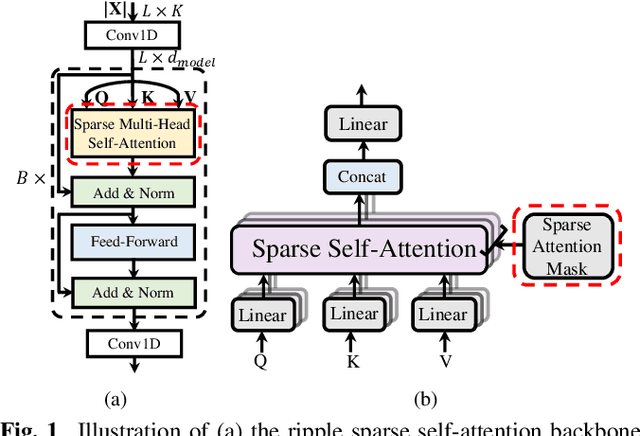
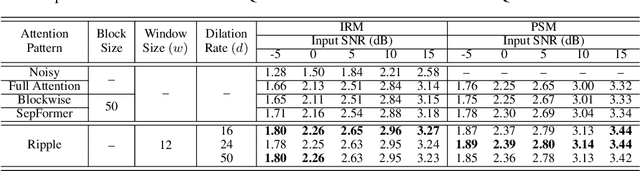
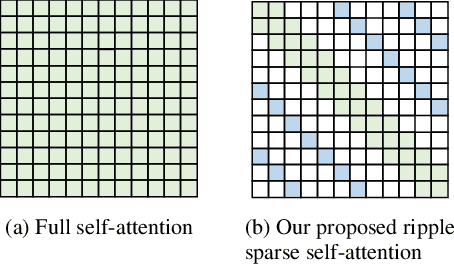
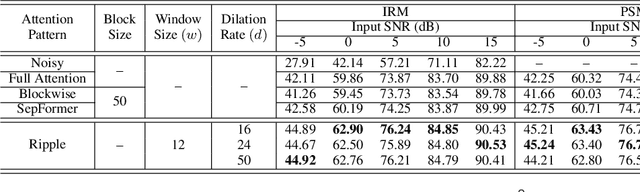
The use of Transformer represents a recent success in speech enhancement. However, as its core component, self-attention suffers from quadratic complexity, which is computationally prohibited for long speech recordings. Moreover, it allows each time frame to attend to all time frames, neglecting the strong local correlations of speech signals. This study presents a simple yet effective sparse self-attention for speech enhancement, called ripple attention, which simultaneously performs fine- and coarse-grained modeling for local and global dependencies, respectively. Specifically, we employ local band attention to enable each frame to attend to its closest neighbor frames in a window at fine granularity, while employing dilated attention outside the window to model the global dependencies at a coarse granularity. We evaluate the efficacy of our ripple attention for speech enhancement on two commonly used training objectives. Extensive experimental results consistently confirm the superior performance of the ripple attention design over standard full self-attention, blockwise attention, and dual-path attention (Sep-Former) in terms of speech quality and intelligibility.
Efficient Face Detection with Audio-Based Region Proposals
Sep 14, 2023Robot vision often involves a large computational load due to large images to process in a short amount of time. Existing solutions often involve reducing image quality which can negatively impact processing. Another approach is to generate regions of interest with expensive vision algorithms. In this paper, we evaluate how audio can be used to generate regions of interest in optical images. To achieve this, we propose a unique attention mechanism to localize speech sources and evaluate its impact on a face detection algorithm. Our results show that the attention mechanism reduces the computational load. The proposed pipeline is flexible and can be easily adapted for human-robot interactions, robot surveillance, video-conferences or smart glasses.