 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Imitation from Observation
Oct 07, 2024Learning from observation (LfO) aims to imitate experts by learning from state-only demonstrations without requiring action labels. Existing adversarial imitation learning approaches learn a generator agent policy to produce state transitions that are indistinguishable to a discriminator that learns to classify agent and expert state transitions. Despite its simplicity in formulation, these methods are often sensitive to hyperparameters and brittle to train. Motivated by the recent success of diffusion models in generative modeling, we propose to integrate a diffusion model into the adversarial imitation learning from observation framework. Specifically, we employ a diffusion model to capture expert and agent transitions by generating the next state, given the current state. Then, we reformulate the learning objective to train the diffusion model as a binary classifier and use it to provide "realness" rewards for policy learning. Our proposed framework, Diffusion Imitation from Observation (DIFO), demonstrates superior performance in various continuous control domains, including navigation, locomotion, manipulation, and games. Project page: https://nturobotlearninglab.github.io/DIFO
Diffusion-Reward Adversarial Imitation Learning
May 25, 2024



Imitation learning aims to learn a policy from observing expert demonstrations without access to reward signals from environments. Generative adversarial imitation learning (GAIL) formulates imitation learning as adversarial learning, employing a generator policy learning to imitate expert behaviors and discriminator learning to distinguish the expert demonstrations from agent trajectories. Despite its encouraging results, GAIL training is often brittle and unstable. Inspired by the recent dominance of diffusion models in generative modeling, this work proposes Diffusion-Reward Adversarial Imitation Learning (DRAIL), which integrates a diffusion model into GAIL, aiming to yield more precise and smoother rewards for policy learning. Specifically, we propose a diffusion discriminative classifier to construct an enhanced discriminator; then, we design diffusion rewards based on the classifier's output for policy learning. We conduct extensive experiments in navigation, manipulation, and locomotion, verifying DRAIL's effectiveness compared to prior imitation learning methods. Moreover, additional experimental results demonstrate the generalizability and data efficiency of DRAIL. Visualized learned reward functions of GAIL and DRAIL suggest that DRAIL can produce more precise and smoother rewards.
AV-SUPERB: A Multi-Task Evaluation Benchmark for Audio-Visual Representation Models
Sep 19, 2023


Audio-visual representation learning aims to develop systems with human-like perception by utilizing correlation between auditory and visual information. However, current models often focus on a limited set of tasks, and generalization abilities of learned representations are unclear. To this end, we propose the AV-SUPERB benchmark that enables general-purpose evaluation of unimodal audio/visual and bimodal fusion representations on 7 datasets covering 5 audio-visual tasks in speech and audio processing. We evaluate 5 recent self-supervised models and show that none of these models generalize to all tasks, emphasizing the need for future study on improving universal model performance. In addition, we show that representations may be improved with intermediate-task fine-tuning and audio event classification with AudioSet serves as a strong intermediate task. We release our benchmark with evaluation code and a model submission platform to encourage further research in audio-visual learning.
Controllable User Dialogue Act Augmentation for Dialogue State Tracking
Jul 26, 2022
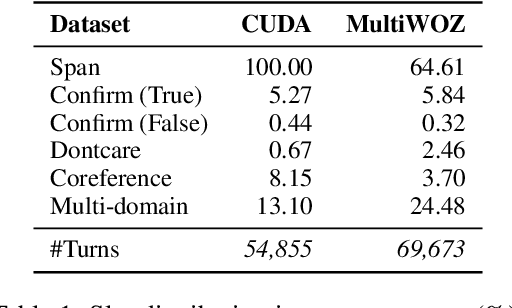
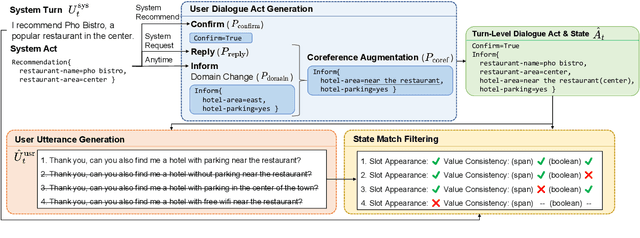
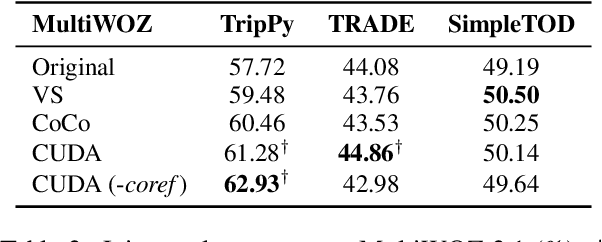
Prior work has demonstrated that data augmentation is useful for improving dialogue state tracking. However, there are many types of user utterances, while the prior method only considered the simplest one for augmentation, raising the concern about poor generalization capability. In order to better cover diverse dialogue acts and control the generation quality, this paper proposes controllable user dialogue act augmentation (CUDA-DST) to augment user utterances with diverse behaviors. With the augmented data, different state trackers gain improvement and show better robustness, achieving the state-of-the-art performance on MultiWOZ 2.1