 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Factorised Speaker-environment Adaptive Training of Conformer Speech Recognition Systems
Jun 26, 2023
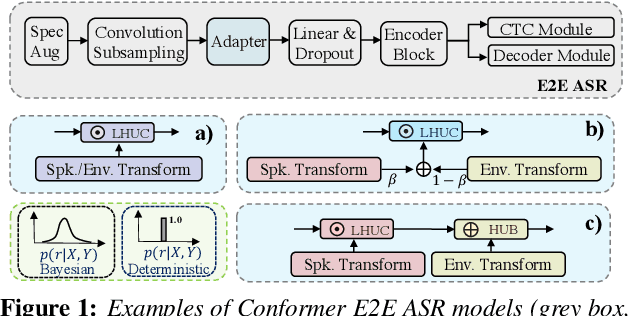
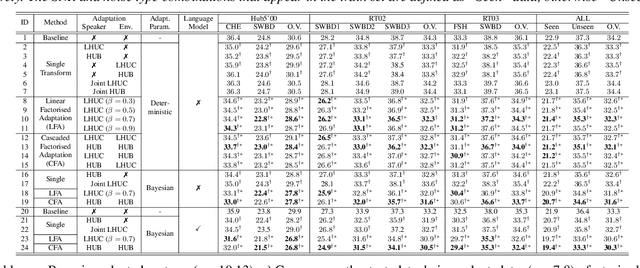
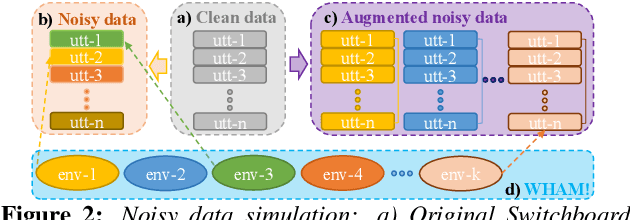
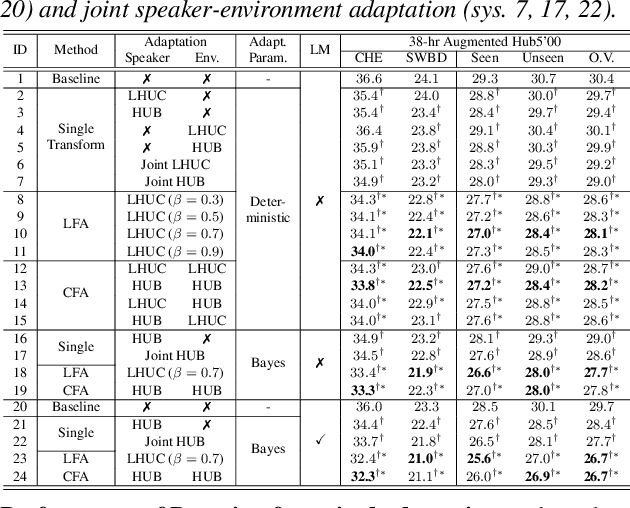
Rich sources of variability in natural speech present significant challenges to current data intensive speech recognition technologies. To model both speaker and environment level diversity, this paper proposes a novel Bayesian factorised speaker-environment adaptive training and test time adaptation approach for Conformer ASR models. Speaker and environment level characteristics are separately modeled using compact hidden output transforms, which are then linearly or hierarchically combined to represent any speaker-environment combination. Bayesian learning is further utilized to model the adaptation parameter uncertainty. Experiments on the 300-hr WHAM noise corrupted Switchboard data suggest that factorised adaptation consistently outperforms the baseline and speaker label only adapted Conformers by up to 3.1% absolute (10.4% relative) word error rate reductions. Further analysis shows the proposed method offers potential for rapid adaption to unseen speaker-environment conditions.
Recent Advances in Direct Speech-to-text Translation
Jun 20, 2023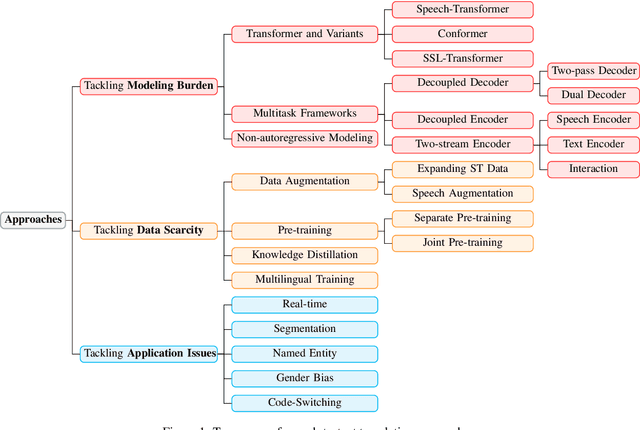
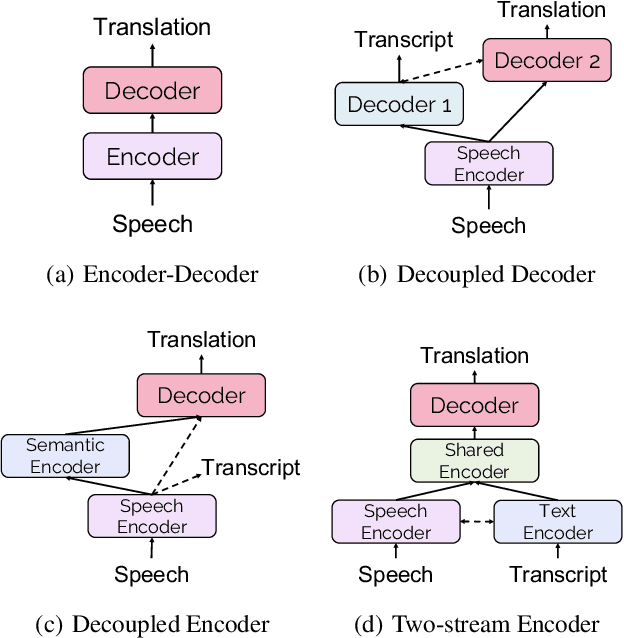
Recently, speech-to-text translation has attracted more and more attention and many studies have emerged rapidly. In this paper, we present a comprehensive survey on direct speech translation aiming to summarize the current state-of-the-art techniques. First, we categorize the existing research work into three directions based on the main challenges -- modeling burden, data scarcity, and application issues. To tackle the problem of modeling burden, two main structures have been proposed, encoder-decoder framework (Transformer and the variants) and multitask frameworks. For the challenge of data scarcity, recent work resorts to many sophisticated techniques, such as data augmentation, pre-training, knowledge distillation, and multilingual modeling. We analyze and summarize the application issues, which include real-time, segmentation, named entity, gender bias, and code-switching. Finally, we discuss some promising directions for future work.
Shiftable Context: Addressing Training-Inference Context Mismatch in Simultaneous Speech Translation
Jul 03, 2023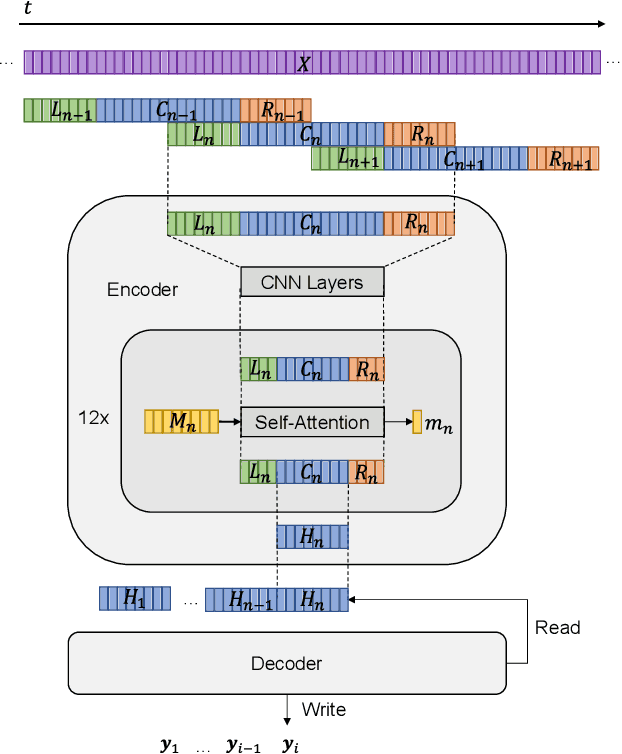
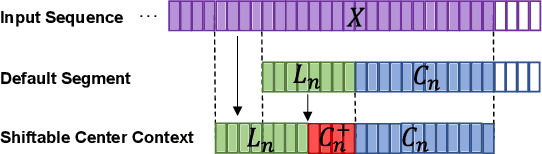
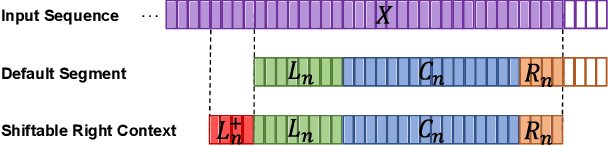
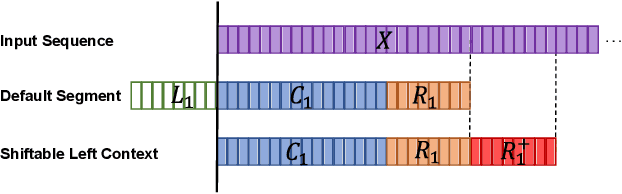
Transformer models using segment-based processing have been an effective architecture for simultaneous speech translation. However, such models create a context mismatch between training and inference environments, hindering potential translation accuracy. We solve this issue by proposing Shiftable Context, a simple yet effective scheme to ensure that consistent segment and context sizes are maintained throughout training and inference, even with the presence of partially filled segments due to the streaming nature of simultaneous translation. Shiftable Context is also broadly applicable to segment-based transformers for streaming tasks. Our experiments on the English-German, English-French, and English-Spanish language pairs from the MUST-C dataset demonstrate that when applied to the Augmented Memory Transformer, a state-of-the-art model for simultaneous speech translation, the proposed scheme achieves an average increase of 2.09, 1.83, and 1.95 BLEU scores across each wait-k value for the three language pairs, respectively, with a minimal impact on computation-aware Average Lagging.
PauseSpeech: Natural Speech Synthesis via Pre-trained Language Model and Pause-based Prosody Modeling
Jun 13, 2023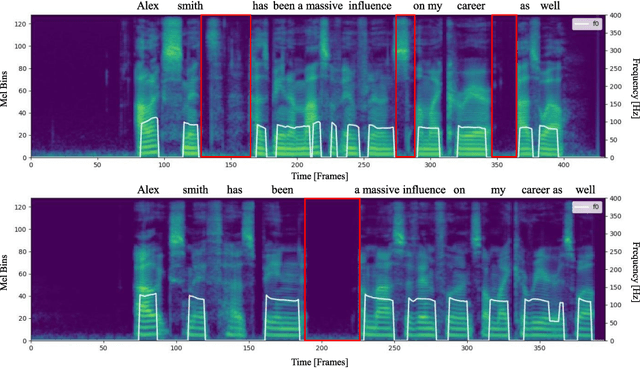
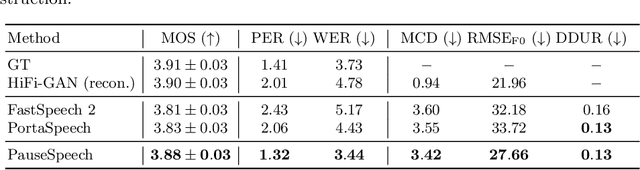
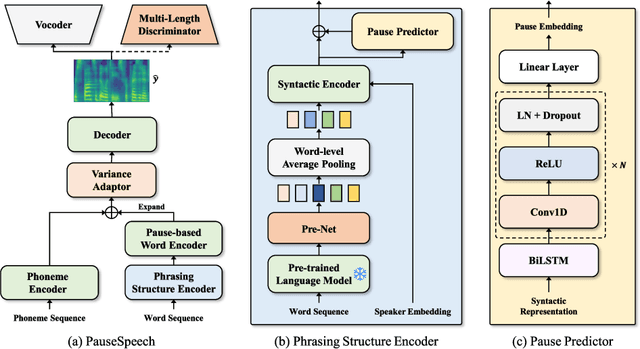

Although text-to-speech (TTS) systems have significantly improved, most TTS systems still have limitations in synthesizing speech with appropriate phrasing. For natural speech synthesis, it is important to synthesize the speech with a phrasing structure that groups words into phrases based on semantic information. In this paper, we propose PuaseSpeech, a speech synthesis system with a pre-trained language model and pause-based prosody modeling. First, we introduce a phrasing structure encoder that utilizes a context representation from the pre-trained language model. In the phrasing structure encoder, we extract a speaker-dependent syntactic representation from the context representation and then predict a pause sequence that separates the input text into phrases. Furthermore, we introduce a pause-based word encoder to model word-level prosody based on pause sequence. Experimental results show PauseSpeech outperforms previous models in terms of naturalness. Furthermore, in terms of objective evaluations, we can observe that our proposed methods help the model decrease the distance between ground-truth and synthesized speech. Audio samples are available at https://jisang93.github.io/pausespeech-demo/.
PEFT-SER: On the Use of Parameter Efficient Transfer Learning Approaches For Speech Emotion Recognition Using Pre-trained Speech Models
Jun 08, 2023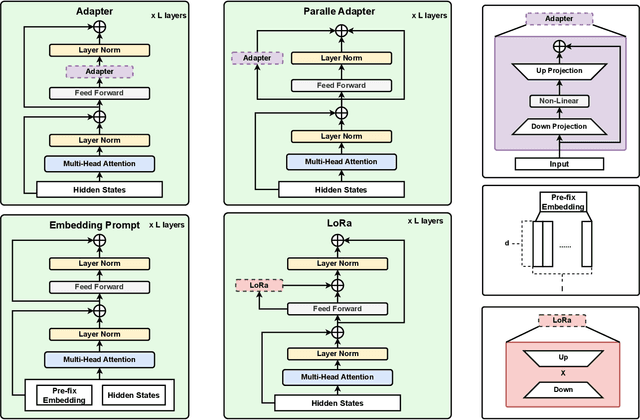
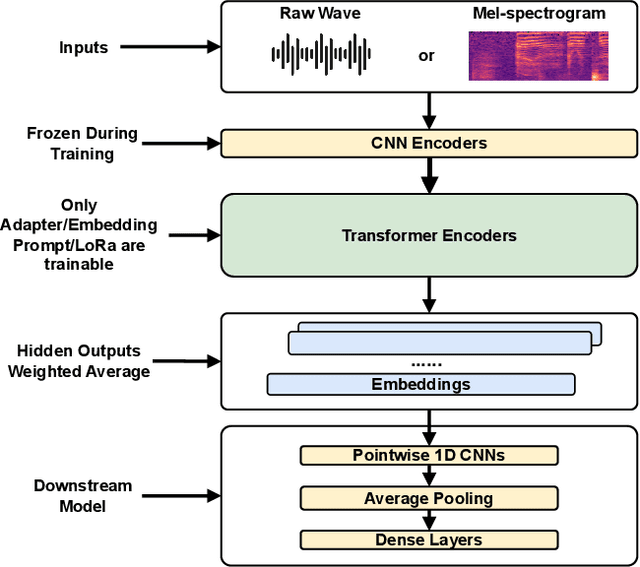

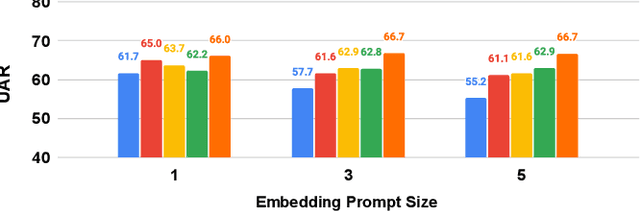
Many recent studies have focused on fine-tuning pre-trained models for speech emotion recognition (SER), resulting in promising performance compared to traditional methods that rely largely on low-level, knowledge-inspired acoustic features. These pre-trained speech models learn general-purpose speech representations using self-supervised or weakly-supervised learning objectives from large-scale datasets. Despite the significant advances made in SER through the use of pre-trained architecture, fine-tuning these large pre-trained models for different datasets requires saving copies of entire weight parameters, rendering them impractical to deploy in real-world settings. As an alternative, this work explores parameter-efficient fine-tuning (PEFT) approaches for adapting pre-trained speech models for emotion recognition. Specifically, we evaluate the efficacy of adapter tuning, embedding prompt tuning, and LoRa (Low-rank approximation) on four popular SER testbeds. Our results reveal that LoRa achieves the best fine-tuning performance in emotion recognition while enhancing fairness and requiring only a minimal extra amount of weight parameters. Furthermore, our findings offer novel insights into future research directions in SER, distinct from existing approaches focusing on directly fine-tuning the model architecture. Our code is publicly available under: https://github.com/usc-sail/peft-ser.
LibriTTS-R: A Restored Multi-Speaker Text-to-Speech Corpus
May 30, 2023
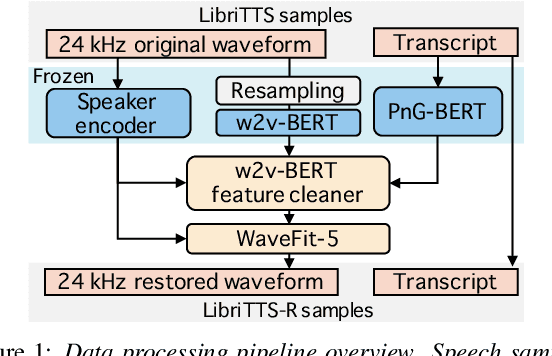
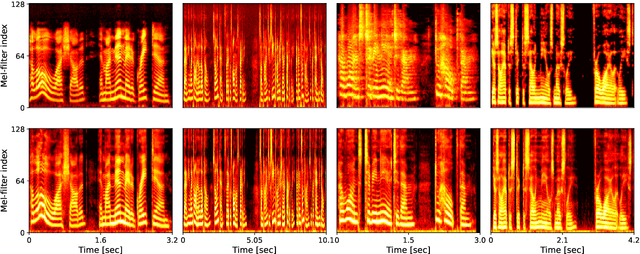

This paper introduces a new speech dataset called ``LibriTTS-R'' designed for text-to-speech (TTS) use. It is derived by applying speech restoration to the LibriTTS corpus, which consists of 585 hours of speech data at 24 kHz sampling rate from 2,456 speakers and the corresponding texts. The constituent samples of LibriTTS-R are identical to those of LibriTTS, with only the sound quality improved. Experimental results show that the LibriTTS-R ground-truth samples showed significantly improved sound quality compared to those in LibriTTS. In addition, neural end-to-end TTS trained with LibriTTS-R achieved speech naturalness on par with that of the ground-truth samples. The corpus is freely available for download from \url{http://www.openslr.org/141/}.
Does My Dog ''Speak'' Like Me? The Acoustic Correlation between Pet Dogs and Their Human Owners
Sep 21, 2023How hosts language influence their pets' vocalization is an interesting yet underexplored problem. This paper presents a preliminary investigation into the possible correlation between domestic dog vocal expressions and their human host's language environment. We first present a new dataset of Shiba Inu dog vocals from YouTube, which provides 7500 clean sound clips, including their contextual information of these vocals and their owner's speech clips with a carefully-designed data processing pipeline. The contextual information includes the scene category in which the vocal was recorded, the dog's location and activity. With a classification task and prominent factor analysis, we discover significant acoustic differences in the dog vocals from the two language environments. We further identify some acoustic features from dog vocalizations that are potentially correlated to their host language patterns.
Dynamic ASR Pathways: An Adaptive Masking Approach Towards Efficient Pruning of A Multilingual ASR Model
Sep 22, 2023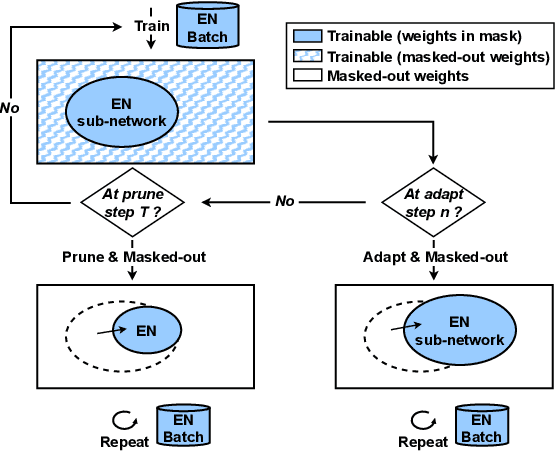
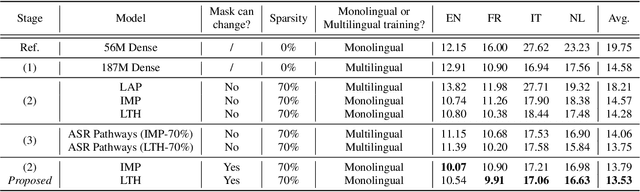
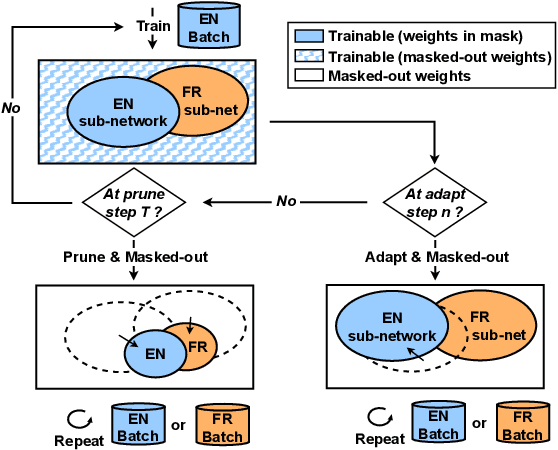
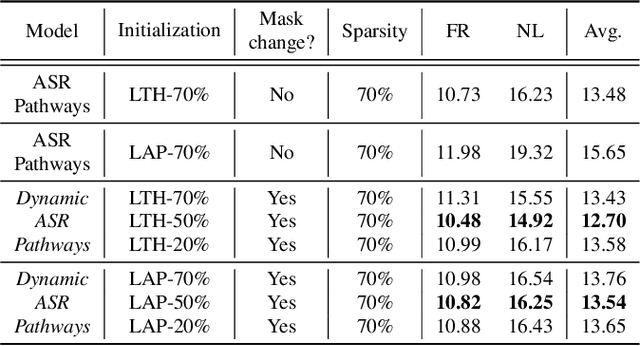
Neural network pruning offers an effective method for compressing a multilingual automatic speech recognition (ASR) model with minimal performance loss. However, it entails several rounds of pruning and re-training needed to be run for each language. In this work, we propose the use of an adaptive masking approach in two scenarios for pruning a multilingual ASR model efficiently, each resulting in sparse monolingual models or a sparse multilingual model (named as Dynamic ASR Pathways). Our approach dynamically adapts the sub-network, avoiding premature decisions about a fixed sub-network structure. We show that our approach outperforms existing pruning methods when targeting sparse monolingual models. Further, we illustrate that Dynamic ASR Pathways jointly discovers and trains better sub-networks (pathways) of a single multilingual model by adapting from different sub-network initializations, thereby reducing the need for language-specific pruning.
STT4SG-350: A Speech Corpus for All Swiss German Dialect Regions
May 30, 2023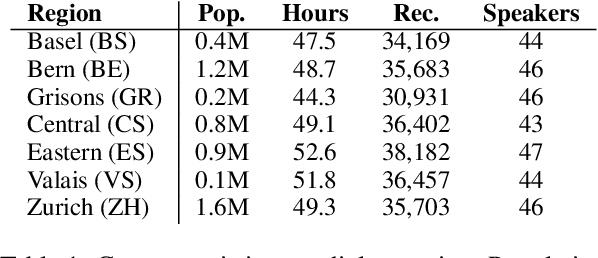
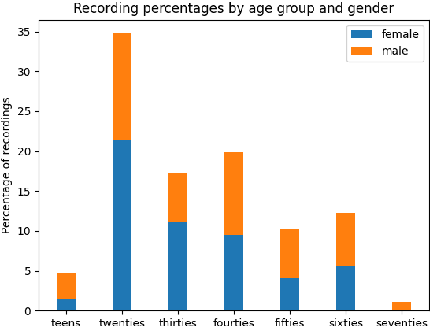
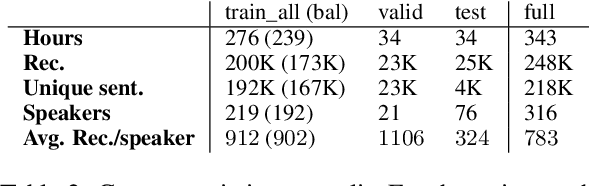
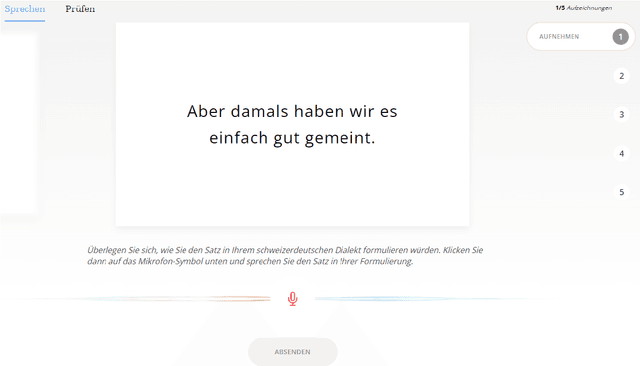
We present STT4SG-350 (Speech-to-Text for Swiss German), a corpus of Swiss German speech, annotated with Standard German text at the sentence level. The data is collected using a web app in which the speakers are shown Standard German sentences, which they translate to Swiss German and record. We make the corpus publicly available. It contains 343 hours of speech from all dialect regions and is the largest public speech corpus for Swiss German to date. Application areas include automatic speech recognition (ASR), text-to-speech, dialect identification, and speaker recognition. Dialect information, age group, and gender of the 316 speakers are provided. Genders are equally represented and the corpus includes speakers of all ages. Roughly the same amount of speech is provided per dialect region, which makes the corpus ideally suited for experiments with speech technology for different dialects. We provide training, validation, and test splits of the data. The test set consists of the same spoken sentences for each dialect region and allows a fair evaluation of the quality of speech technologies in different dialects. We train an ASR model on the training set and achieve an average BLEU score of 74.7 on the test set. The model beats the best published BLEU scores on 2 other Swiss German ASR test sets, demonstrating the quality of the corpus.
End-to-End Simultaneous Speech Translation with Differentiable Segmentation
May 25, 2023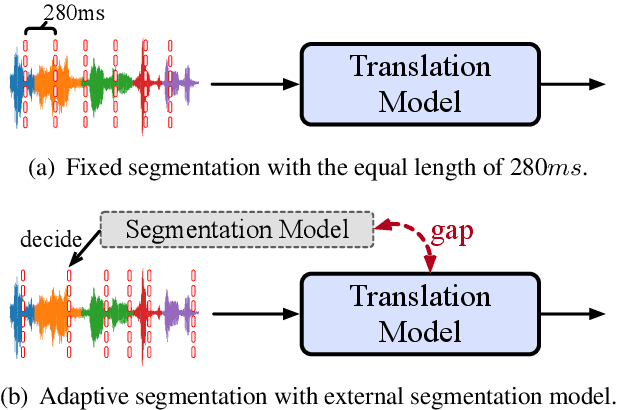
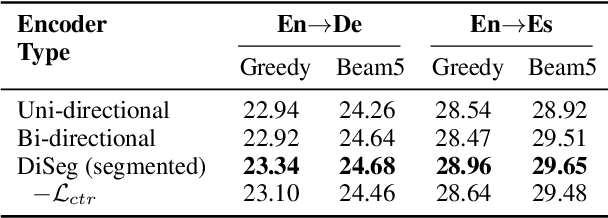
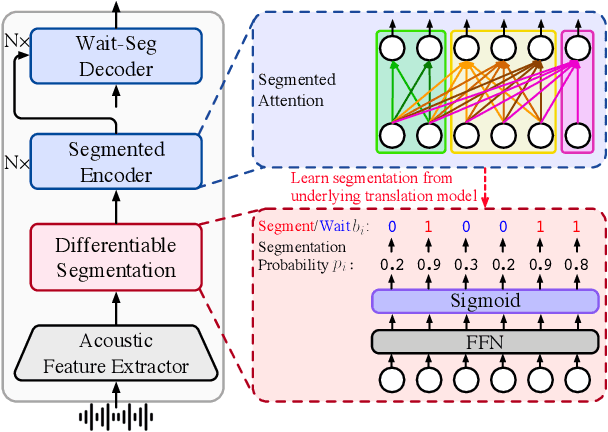
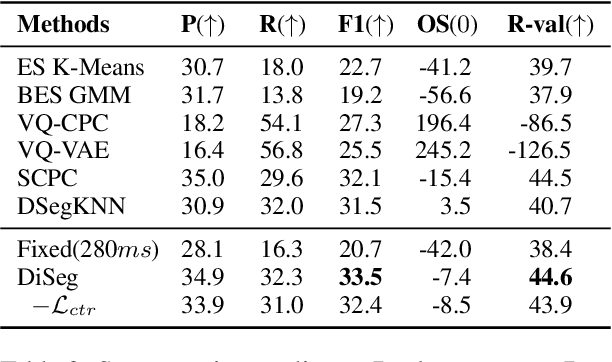
End-to-end simultaneous speech translation (SimulST) outputs translation while receiving the streaming speech inputs (a.k.a. streaming speech translation), and hence needs to segment the speech inputs and then translate based on the current received speech. However, segmenting the speech inputs at unfavorable moments can disrupt the acoustic integrity and adversely affect the performance of the translation model. Therefore, learning to segment the speech inputs at those moments that are beneficial for the translation model to produce high-quality translation is the key to SimulST. Existing SimulST methods, either using the fixed-length segmentation or external segmentation model, always separate segmentation from the underlying translation model, where the gap results in segmentation outcomes that are not necessarily beneficial for the translation process. In this paper, we propose Differentiable Segmentation (DiSeg) for SimulST to directly learn segmentation from the underlying translation model. DiSeg turns hard segmentation into differentiable through the proposed expectation training, enabling it to be jointly trained with the translation model and thereby learn translation-beneficial segmentation. Experimental results demonstrate that DiSeg achieves state-of-the-art performance and exhibits superior segmentation capability.