 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverbMiipher: Generative Speech Restoration meets Reverberation Characteristics Controllability
May 08, 2025



Reverberation encodes spatial information regarding the acoustic source environment, yet traditional Speech Restoration (SR) usually completely removes reverberation. We propose ReverbMiipher, an SR model extending parametric resynthesis framework, designed to denoise speech while preserving and enabling control over reverberation. ReverbMiipher incorporates a dedicated ReverbEncoder to extract a reverb feature vector from noisy input. This feature conditions a vocoder to reconstruct the speech signal, removing noise while retaining the original reverberation characteristics. A stochastic zero-vector replacement strategy during training ensures the feature specifically encodes reverberation, disentangling it from other speech attributes. This learned representation facilitates reverberation control via techniques such as interpolation between features, replacement with features from other utterances, or sampling from a latent space. Objective and subjective evaluations confirm ReverbMiipher effectively preserves reverberation, removes other artifacts, and outperforms the conventional two-stage SR and convolving simulated room impulse response approach. We further demonstrate its ability to generate novel reverberation effects through feature manipulation.
Miipher-2: A Universal Speech Restoration Model for Million-Hour Scale Data Restoration
May 07, 2025



Training data cleaning is a new application for generative model-based speech restoration (SR). This paper introduces Miipher-2, an SR model designed for million-hour scale data, for training data cleaning for large-scale generative models like large language models. Key challenges addressed include generalization to unseen languages, operation without explicit conditioning (e.g., text, speaker ID), and computational efficiency. Miipher-2 utilizes a frozen, pre-trained Universal Speech Model (USM), supporting over 300 languages, as a robust, conditioning-free feature extractor. To optimize efficiency and minimize memory, Miipher-2 incorporates parallel adapters for predicting clean USM features from noisy inputs and employs the WaneFit neural vocoder for waveform synthesis. These components were trained on 3,000 hours of multi-lingual, studio-quality recordings with augmented degradations, while USM parameters remained fixed. Experimental results demonstrate Miipher-2's superior or comparable performance to conventional SR models in word-error-rate, speaker similarity, and both objective and subjective sound quality scores across all tested languages. Miipher-2 operates efficiently on consumer-grade accelerators, achieving a real-time factor of 0.0078, enabling the processing of a million-hour speech dataset in approximately three days using only 100 such accelerators.
Adaptive Dropout for Pruning Conformers
Dec 06, 2024


This paper proposes a method to effectively perform joint training-and-pruning based on adaptive dropout layers with unit-wise retention probabilities. The proposed method is based on the estimation of a unit-wise retention probability in a dropout layer. A unit that is estimated to have a small retention probability can be considered to be prunable. The retention probability of the unit is estimated using back-propagation and the Gumbel-Softmax technique. This pruning method is applied at several application points in Conformers such that the effective number of parameters can be significantly reduced. Specifically, adaptive dropout layers are introduced in three locations in each Conformer block: (a) the hidden layer of the feed-forward-net component, (b) the query vectors and the value vectors of the self-attention component, and (c) the input vectors of the LConv component. The proposed method is evaluated by conducting a speech recognition experiment on the LibriSpeech task. It was shown that this approach could simultaneously achieve a parameter reduction and accuracy improvement. The word error rates improved by approx 1% while reducing the number of parameters by 54%.
FLEURS-R: A Restored Multilingual Speech Corpus for Generation Tasks
Aug 12, 2024



This paper introduces FLEURS-R, a speech restoration applied version of the Few-shot Learning Evaluation of Universal Representations of Speech (FLEURS) corpus. FLEURS-R maintains an N-way parallel speech corpus in 102 languages as FLEURS, with improved audio quality and fidelity by applying the speech restoration model Miipher. The aim of FLEURS-R is to advance speech technology in more languages and catalyze research including text-to-speech (TTS) and other speech generation tasks in low-resource languages. Comprehensive evaluations with the restored speech and TTS baseline models trained from the new corpus show that the new corpus obtained significantly improved speech quality while maintaining the semantic contents of the speech. The corpus is publicly released via Hugging Face.
LibriTTS-R: A Restored Multi-Speaker Text-to-Speech Corpus
May 30, 2023



This paper introduces a new speech dataset called ``LibriTTS-R'' designed for text-to-speech (TTS) use. It is derived by applying speech restoration to the LibriTTS corpus, which consists of 585 hours of speech data at 24 kHz sampling rate from 2,456 speakers and the corresponding texts. The constituent samples of LibriTTS-R are identical to those of LibriTTS, with only the sound quality improved. Experimental results show that the LibriTTS-R ground-truth samples showed significantly improved sound quality compared to those in LibriTTS. In addition, neural end-to-end TTS trained with LibriTTS-R achieved speech naturalness on par with that of the ground-truth samples. The corpus is freely available for download from \url{http://www.openslr.org/141/}.
Miipher: A Robust Speech Restoration Model Integrating Self-Supervised Speech and Text Representations
Mar 03, 2023



Speech restoration (SR) is a task of converting degraded speech signals into high-quality ones. In this study, we propose a robust SR model called Miipher, and apply Miipher to a new SR application: increasing the amount of high-quality training data for speech generation by converting speech samples collected from the Web to studio-quality. To make our SR model robust against various degradation, we use (i) a speech representation extracted from w2v-BERT for the input feature, and (ii) a text representation extracted from transcripts via PnG-BERT as a linguistic conditioning feature. Experiments show that Miipher (i) is robust against various audio degradation and (ii) enable us to train a high-quality text-to-speech (TTS) model from restored speech samples collected from the Web. Audio samples are available at our demo page: google.github.io/df-conformer/miipher/
WaveFit: An Iterative and Non-autoregressive Neural Vocoder based on Fixed-Point Iteration
Oct 03, 2022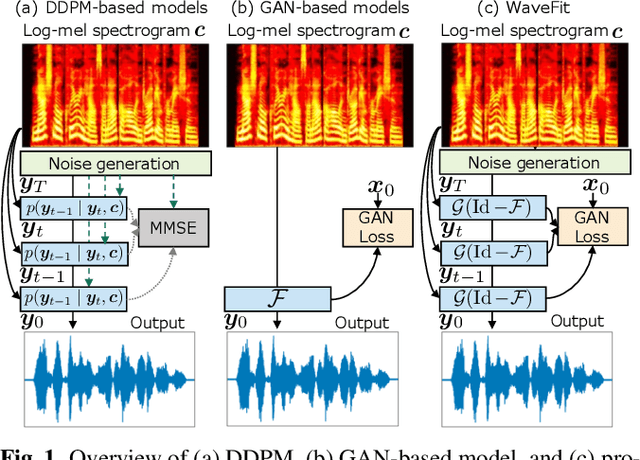
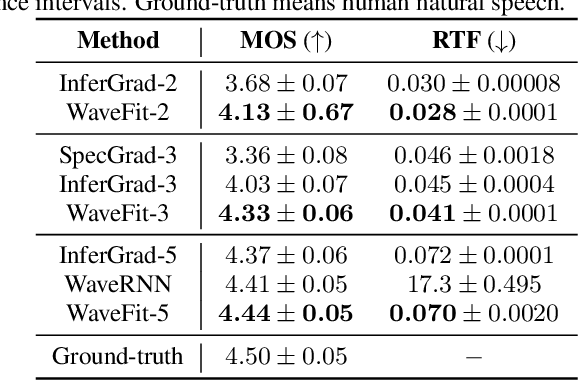
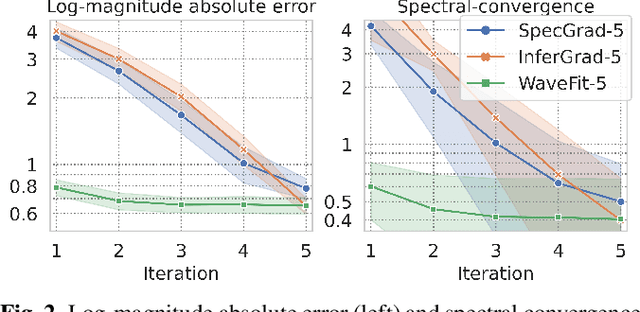
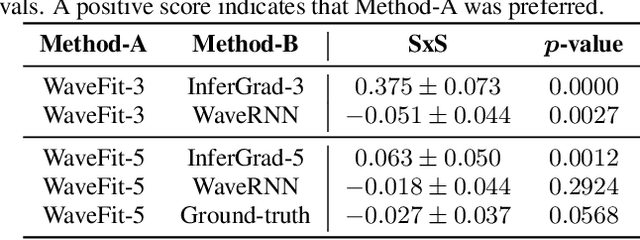
Denoising diffusion probabilistic models (DDPMs) and generative adversarial networks (GANs) are popular generative models for neural vocoders. The DDPMs and GANs can be characterized by the iterative denoising framework and adversarial training, respectively. This study proposes a fast and high-quality neural vocoder called \textit{WaveFit}, which integrates the essence of GANs into a DDPM-like iterative framework based on fixed-point iteration. WaveFit iteratively denoises an input signal, and trains a deep neural network (DNN) for minimizing an adversarial loss calculated from intermediate outputs at all iterations. Subjective (side-by-side) listening tests showed no statistically significant differences in naturalness between human natural speech and those synthesized by WaveFit with five iterations. Furthermore, the inference speed of WaveFit was more than 240 times faster than WaveRNN. Audio demos are available at \url{google.github.io/df-conformer/wavefit/}.
SpecGrad: Diffusion Probabilistic Model based Neural Vocoder with Adaptive Noise Spectral Shaping
Mar 31, 2022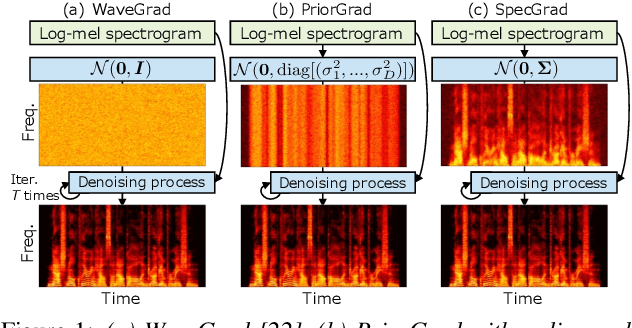
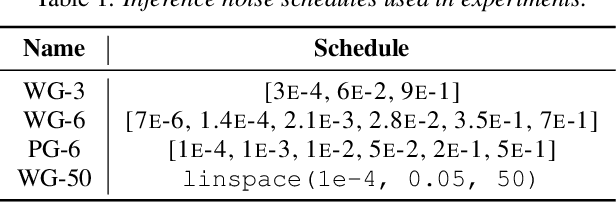
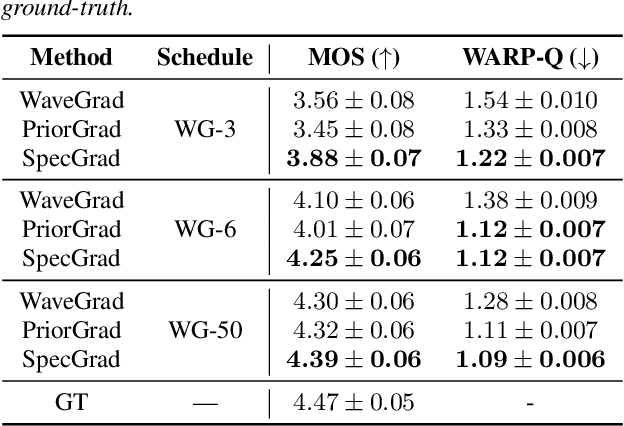
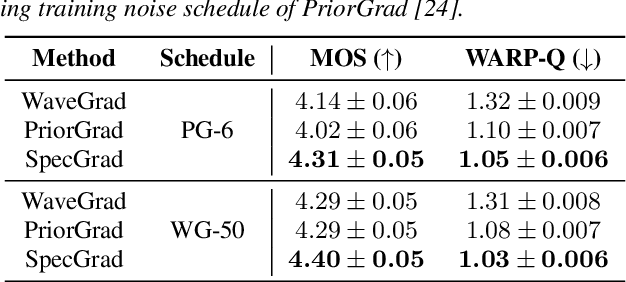
Neural vocoder using denoising diffusion probabilistic model (DDPM) has been improved by adaptation of the diffusion noise distribution to given acoustic features. In this study, we propose SpecGrad that adapts the diffusion noise so that its time-varying spectral envelope becomes close to the conditioning log-mel spectrogram. This adaptation by time-varying filtering improves the sound quality especially in the high-frequency bands. It is processed in the time-frequency domain to keep the computational cost almost the same as the conventional DDPM-based neural vocoders. Experimental results showed that SpecGrad generates higher-fidelity speech waveform than conventional DDPM-based neural vocoders in both analysis-synthesis and speech enhancement scenarios. Audio demos are available at wavegrad.github.io/specgrad/.
Knowledge Transfer from Large-scale Pretrained Language Models to End-to-end Speech Recognizers
Feb 16, 2022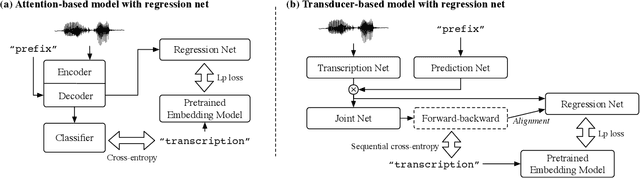
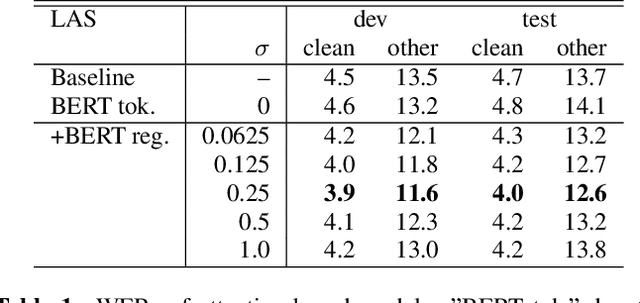
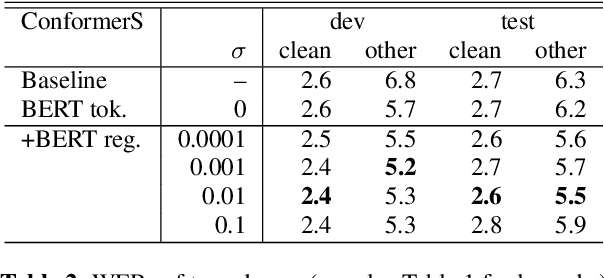
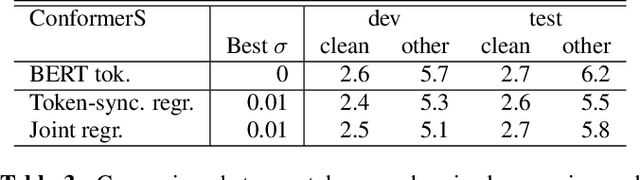
End-to-end speech recognition is a promising technology for enabling compact automatic speech recognition (ASR) systems since it can unify the acoustic and language model into a single neural network. However, as a drawback, training of end-to-end speech recognizers always requires transcribed utterances. Since end-to-end models are also known to be severely data hungry, this constraint is crucial especially because obtaining transcribed utterances is costly and can possibly be impractical or impossible. This paper proposes a method for alleviating this issue by transferring knowledge from a language model neural network that can be pretrained with text-only data. Specifically, this paper attempts to transfer semantic knowledge acquired in embedding vectors of large-scale language models. Since embedding vectors can be assumed as implicit representations of linguistic information such as part-of-speech, intent, and so on, those are also expected to be useful modeling cues for ASR decoders. This paper extends two types of ASR decoders, attention-based decoders and neural transducers, by modifying training loss functions to include embedding prediction terms. The proposed systems were shown to be effective for error rate reduction without incurring extra computational costs in the decoding phase.
SNRi Target Training for Joint Speech Enhancement and Recognition
Nov 01, 2021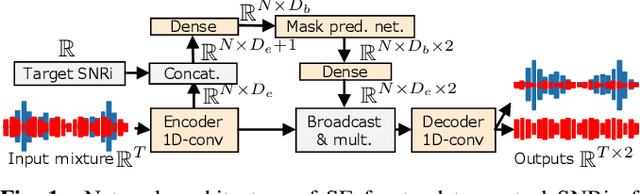

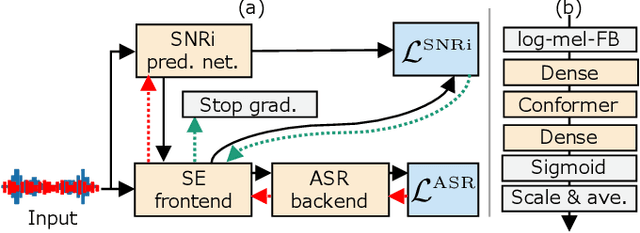
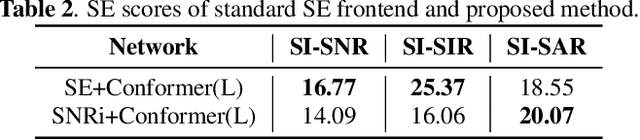
This study aims to improve the performance of automatic speech recognition (ASR) under noisy conditions. The use of a speech enhancement (SE) frontend has been widely studied for noise robust ASR. However, most single-channel SE models introduce processing artifacts in the enhanced speech resulting in degraded ASR performance. To overcome this problem, we propose Signal-to-Noise Ratio improvement (SNRi) target training; the SE frontend automatically controls its noise reduction level to avoid degrading the ASR performance due to artifacts. The SE frontend uses an auxiliary scalar input which represents the target SNRi of the output signal. The target SNRi value is estimated by the SNRi prediction network, which is trained to minimize the ASR loss. Experiments using 55,027 hours of noisy speech training data show that SNRi target training enables control of the SNRi of the output signal, and the joint training reduces word error rate by 12% compared to a state-of-the-art Conformer-based ASR model.