 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating High-Fidelity Waveform Generation via Adversarial Flow Matching Optimization
Aug 15, 2024



This paper introduces PeriodWave-Turbo, a high-fidelity and high-efficient waveform generation model via adversarial flow matching optimization. Recently, conditional flow matching (CFM) generative models have been successfully adopted for waveform generation tasks, leveraging a single vector field estimation objective for training. Although these models can generate high-fidelity waveform signals, they require significantly more ODE steps compared to GAN-based models, which only need a single generation step. Additionally, the generated samples often lack high-frequency information due to noisy vector field estimation, which fails to ensure high-frequency reproduction. To address this limitation, we enhance pre-trained CFM-based generative models by incorporating a fixed-step generator modification. We utilized reconstruction losses and adversarial feedback to accelerate high-fidelity waveform generation. Through adversarial flow matching optimization, it only requires 1,000 steps of fine-tuning to achieve state-of-the-art performance across various objective metrics. Moreover, we significantly reduce inference speed from 16 steps to 2 or 4 steps. Additionally, by scaling up the backbone of PeriodWave from 29M to 70M parameters for improved generalization, PeriodWave-Turbo achieves unprecedented performance, with a perceptual evaluation of speech quality (PESQ) score of 4.454 on the LibriTTS dataset. Audio samples, source code and checkpoints will be available at https://github.com/sh-lee-prml/PeriodWave.
PeriodWave: Multi-Period Flow Matching for High-Fidelity Waveform Generation
Aug 14, 2024



Recently, universal waveform generation tasks have been investigated conditioned on various out-of-distribution scenarios. Although GAN-based methods have shown their strength in fast waveform generation, they are vulnerable to train-inference mismatch scenarios such as two-stage text-to-speech. Meanwhile, diffusion-based models have shown their powerful generative performance in other domains; however, they stay out of the limelight due to slow inference speed in waveform generation tasks. Above all, there is no generator architecture that can explicitly disentangle the natural periodic features of high-resolution waveform signals. In this paper, we propose PeriodWave, a novel universal waveform generation model. First, we introduce a period-aware flow matching estimator that can capture the periodic features of the waveform signal when estimating the vector fields. Additionally, we utilize a multi-period estimator that avoids overlaps to capture different periodic features of waveform signals. Although increasing the number of periods can improve the performance significantly, this requires more computational costs. To reduce this issue, we also propose a single period-conditional universal estimator that can feed-forward parallel by period-wise batch inference. Additionally, we utilize discrete wavelet transform to losslessly disentangle the frequency information of waveform signals for high-frequency modeling, and introduce FreeU to reduce the high-frequency noise for waveform generation. The experimental results demonstrated that our model outperforms the previous models both in Mel-spectrogram reconstruction and text-to-speech tasks. All source code will be available at \url{https://github.com/sh-lee-prml/PeriodWave}.
EmoSphere-TTS: Emotional Style and Intensity Modeling via Spherical Emotion Vector for Controllable Emotional Text-to-Speech
Jun 12, 2024Despite rapid advances in the field of emotional text-to-speech (TTS), recent studies primarily focus on mimicking the average style of a particular emotion. As a result, the ability to manipulate speech emotion remains constrained to several predefined labels, compromising the ability to reflect the nuanced variations of emotion. In this paper, we propose EmoSphere-TTS, which synthesizes expressive emotional speech by using a spherical emotion vector to control the emotional style and intensity of the synthetic speech. Without any human annotation, we use the arousal, valence, and dominance pseudo-labels to model the complex nature of emotion via a Cartesian-spherical transformation. Furthermore, we propose a dual conditional adversarial network to improve the quality of generated speech by reflecting the multi-aspect characteristics. The experimental results demonstrate the model ability to control emotional style and intensity with high-quality expressive speech.
TranSentence: Speech-to-speech Translation via Language-agnostic Sentence-level Speech Encoding without Language-parallel Data
Jan 17, 2024Although there has been significant advancement in the field of speech-to-speech translation, conventional models still require language-parallel speech data between the source and target languages for training. In this paper, we introduce TranSentence, a novel speech-to-speech translation without language-parallel speech data. To achieve this, we first adopt a language-agnostic sentence-level speech encoding that captures the semantic information of speech, irrespective of language. We then train our model to generate speech based on the encoded embedding obtained from a language-agnostic sentence-level speech encoder that is pre-trained with various languages. With this method, despite training exclusively on the target language's monolingual data, we can generate target language speech in the inference stage using language-agnostic speech embedding from the source language speech. Furthermore, we extend TranSentence to multilingual speech-to-speech translation. The experimental results demonstrate that TranSentence is superior to other models.
DurFlex-EVC: Duration-Flexible Emotional Voice Conversion with Parallel Generation
Jan 16, 2024Emotional voice conversion (EVC) seeks to modify the emotional tone of a speaker's voice while preserving the original linguistic content and the speaker's unique vocal characteristics. Recent advancements in EVC have involved the simultaneous modeling of pitch and duration, utilizing the potential of sequence-to-sequence (seq2seq) models. To enhance reliability and efficiency in conversion, this study shifts focus towards parallel speech generation. We introduce Duration-Flexible EVC (DurFlex-EVC), which integrates a style autoencoder and unit aligner. Traditional models, while incorporating self-supervised learning (SSL) representations that contain both linguistic and paralinguistic information, have neglected this dual nature, leading to reduced controllability. Addressing this issue, we implement cross-attention to synchronize these representations with various emotions. Additionally, a style autoencoder is developed for the disentanglement and manipulation of style elements. The efficacy of our approach is validated through both subjective and objective evaluations, establishing its superiority over existing models in the field.
HierSpeech++: Bridging the Gap between Semantic and Acoustic Representation of Speech by Hierarchical Variational Inference for Zero-shot Speech Synthesis
Nov 27, 2023Large language models (LLM)-based speech synthesis has been widely adopted in zero-shot speech synthesis. However, they require a large-scale data and possess the same limitations as previous autoregressive speech models, including slow inference speed and lack of robustness. This paper proposes HierSpeech++, a fast and strong zero-shot speech synthesizer for text-to-speech (TTS) and voice conversion (VC). We verified that hierarchical speech synthesis frameworks could significantly improve the robustness and expressiveness of the synthetic speech. Furthermore, we significantly improve the naturalness and speaker similarity of synthetic speech even in zero-shot speech synthesis scenarios. For text-to-speech, we adopt the text-to-vec framework, which generates a self-supervised speech representation and an F0 representation based on text representations and prosody prompts. Then, HierSpeech++ generates speech from the generated vector, F0, and voice prompt. We further introduce a high-efficient speech super-resolution framework from 16 kHz to 48 kHz. The experimental results demonstrated that the hierarchical variational autoencoder could be a strong zero-shot speech synthesizer given that it outperforms LLM-based and diffusion-based models. Moreover, we achieved the first human-level quality zero-shot speech synthesis. Audio samples and source code are available at https://github.com/sh-lee-prml/HierSpeechpp.
Diff-HierVC: Diffusion-based Hierarchical Voice Conversion with Robust Pitch Generation and Masked Prior for Zero-shot Speaker Adaptation
Nov 08, 2023Although voice conversion (VC) systems have shown a remarkable ability to transfer voice style, existing methods still have an inaccurate pitch and low speaker adaptation quality. To address these challenges, we introduce Diff-HierVC, a hierarchical VC system based on two diffusion models. We first introduce DiffPitch, which can effectively generate F0 with the target voice style. Subsequently, the generated F0 is fed to DiffVoice to convert the speech with a target voice style. Furthermore, using the source-filter encoder, we disentangle the speech and use the converted Mel-spectrogram as a data-driven prior in DiffVoice to improve the voice style transfer capacity. Finally, by using the masked prior in diffusion models, our model can improve the speaker adaptation quality. Experimental results verify the superiority of our model in pitch generation and voice style transfer performance, and our model also achieves a CER of 0.83% and EER of 3.29% in zero-shot VC scenarios.
DiffProsody: Diffusion-based Latent Prosody Generation for Expressive Speech Synthesis with Prosody Conditional Adversarial Training
Jul 31, 2023



Expressive text-to-speech systems have undergone significant advancements owing to prosody modeling, but conventional methods can still be improved. Traditional approaches have relied on the autoregressive method to predict the quantized prosody vector; however, it suffers from the issues of long-term dependency and slow inference. This study proposes a novel approach called DiffProsody in which expressive speech is synthesized using a diffusion-based latent prosody generator and prosody conditional adversarial training. Our findings confirm the effectiveness of our prosody generator in generating a prosody vector. Furthermore, our prosody conditional discriminator significantly improves the quality of the generated speech by accurately emulating prosody. We use denoising diffusion generative adversarial networks to improve the prosody generation speed. Consequently, DiffProsody is capable of generating prosody 16 times faster than the conventional diffusion model. The superior performance of our proposed method has been demonstrated via experiments.
HierVST: Hierarchical Adaptive Zero-shot Voice Style Transfer
Jul 30, 2023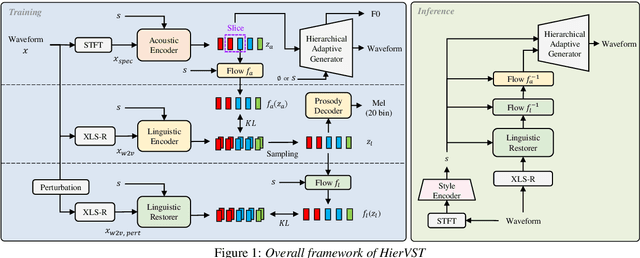
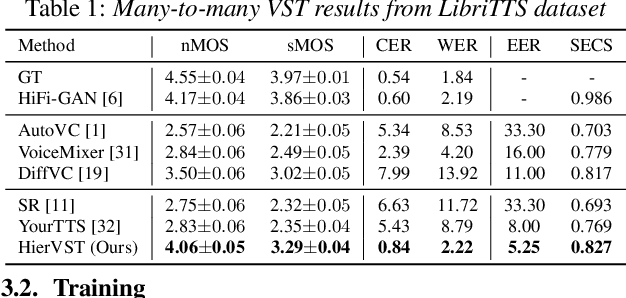
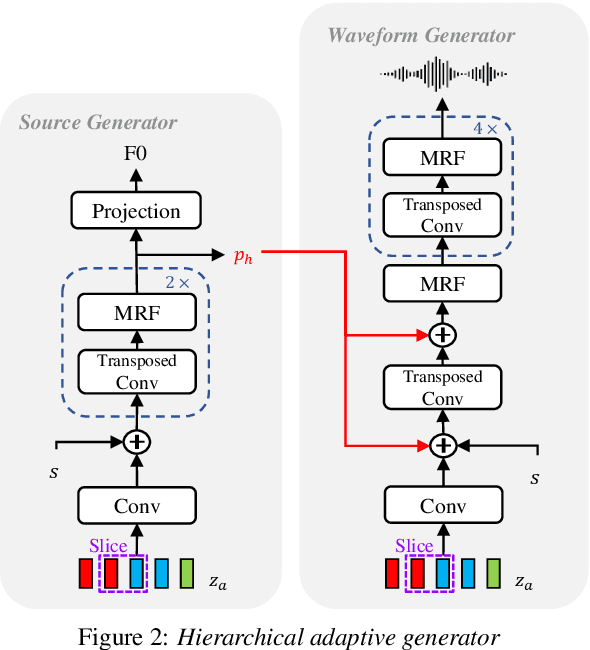
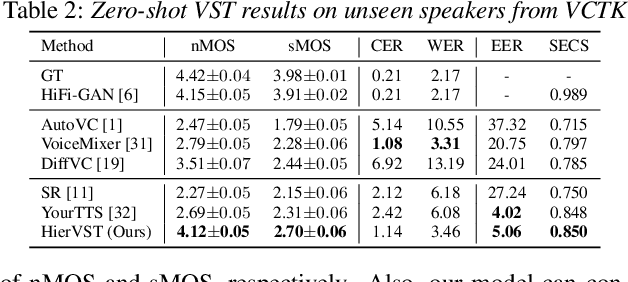
Despite rapid progress in the voice style transfer (VST) field, recent zero-shot VST systems still lack the ability to transfer the voice style of a novel speaker. In this paper, we present HierVST, a hierarchical adaptive end-to-end zero-shot VST model. Without any text transcripts, we only use the speech dataset to train the model by utilizing hierarchical variational inference and self-supervised representation. In addition, we adopt a hierarchical adaptive generator that generates the pitch representation and waveform audio sequentially. Moreover, we utilize unconditional generation to improve the speaker-relative acoustic capacity in the acoustic representation. With a hierarchical adaptive structure, the model can adapt to a novel voice style and convert speech progressively. The experimental results demonstrate that our method outperforms other VST models in zero-shot VST scenarios. Audio samples are available at \url{https://hiervst.github.io/}.
PauseSpeech: Natural Speech Synthesis via Pre-trained Language Model and Pause-based Prosody Modeling
Jun 13, 2023



Although text-to-speech (TTS) systems have significantly improved, most TTS systems still have limitations in synthesizing speech with appropriate phrasing. For natural speech synthesis, it is important to synthesize the speech with a phrasing structure that groups words into phrases based on semantic information. In this paper, we propose PuaseSpeech, a speech synthesis system with a pre-trained language model and pause-based prosody modeling. First, we introduce a phrasing structure encoder that utilizes a context representation from the pre-trained language model. In the phrasing structure encoder, we extract a speaker-dependent syntactic representation from the context representation and then predict a pause sequence that separates the input text into phrases. Furthermore, we introduce a pause-based word encoder to model word-level prosody based on pause sequence. Experimental results show PauseSpeech outperforms previous models in terms of naturalness. Furthermore, in terms of objective evaluations, we can observe that our proposed methods help the model decrease the distance between ground-truth and synthesized speech. Audio samples are available at https://jisang93.github.io/pausespeech-demo/.