 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
PromptVC: Flexible Stylistic Voice Conversion in Latent Space Driven by Natural Language Prompts
Sep 17, 2023
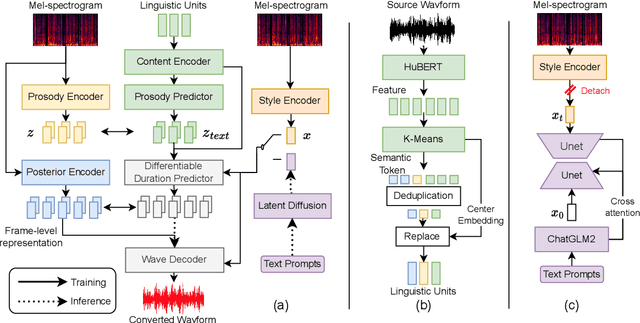

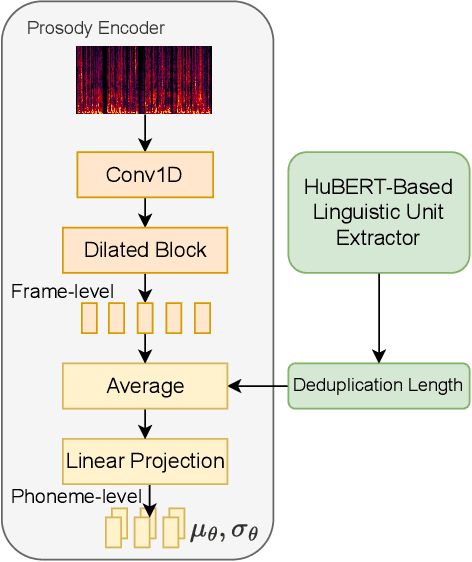
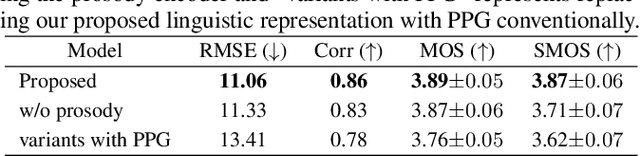
Style voice conversion aims to transform the style of source speech to a desired style according to real-world application demands. However, the current style voice conversion approach relies on pre-defined labels or reference speech to control the conversion process, which leads to limitations in style diversity or falls short in terms of the intuitive and interpretability of style representation. In this study, we propose PromptVC, a novel style voice conversion approach that employs a latent diffusion model to generate a style vector driven by natural language prompts. Specifically, the style vector is extracted by a style encoder during training, and then the latent diffusion model is trained independently to sample the style vector from noise, with this process being conditioned on natural language prompts. To improve style expressiveness, we leverage HuBERT to extract discrete tokens and replace them with the K-Means center embedding to serve as the linguistic content, which minimizes residual style information. Additionally, we deduplicate the same discrete token and employ a differentiable duration predictor to re-predict the duration of each token, which can adapt the duration of the same linguistic content to different styles. The subjective and objective evaluation results demonstrate the effectiveness of our proposed system.
PP-MeT: a Real-world Personalized Prompt based Meeting Transcription System
Sep 28, 2023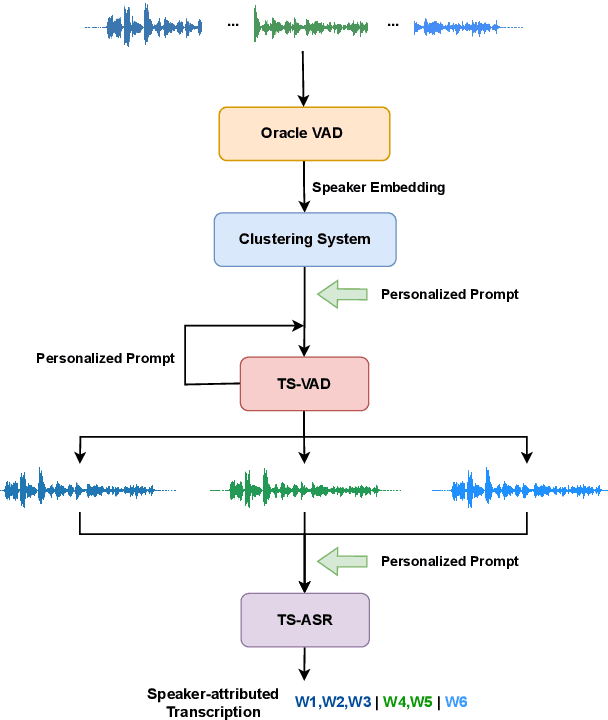
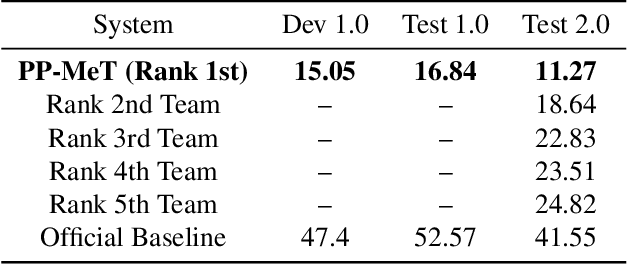
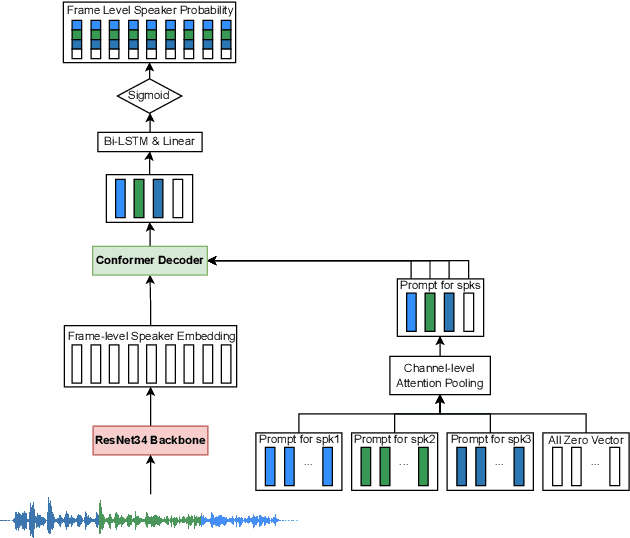

Speaker-attributed automatic speech recognition (SA-ASR) improves the accuracy and applicability of multi-speaker ASR systems in real-world scenarios by assigning speaker labels to transcribed texts. However, SA-ASR poses unique challenges due to factors such as speaker overlap, speaker variability, background noise, and reverberation. In this study, we propose PP-MeT system, a real-world personalized prompt based meeting transcription system, which consists of a clustering system, target-speaker voice activity detection (TS-VAD), and TS-ASR. Specifically, we utilize target-speaker embedding as a prompt in TS-VAD and TS-ASR modules in our proposed system. In constrast with previous system, we fully leverage pre-trained models for system initialization, thereby bestowing our approach with heightened generalizability and precision. Experiments on M2MeT2.0 Challenge dataset show that our system achieves a cp-CER of 11.27% on the test set, ranking first in both fixed and open training conditions.
Fake the Real: Backdoor Attack on Deep Speech Classification via Voice Conversion
Jun 28, 2023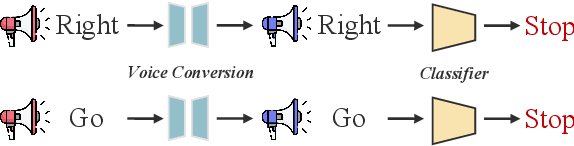
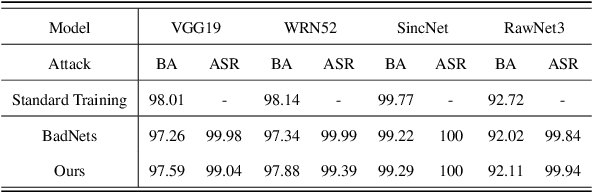
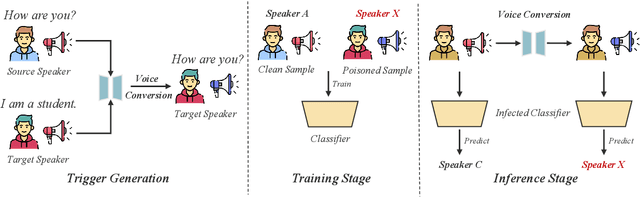

Deep speech classification has achieved tremendous success and greatly promoted the emergence of many real-world applications. However, backdoor attacks present a new security threat to it, particularly with untrustworthy third-party platforms, as pre-defined triggers set by the attacker can activate the backdoor. Most of the triggers in existing speech backdoor attacks are sample-agnostic, and even if the triggers are designed to be unnoticeable, they can still be audible. This work explores a backdoor attack that utilizes sample-specific triggers based on voice conversion. Specifically, we adopt a pre-trained voice conversion model to generate the trigger, ensuring that the poisoned samples does not introduce any additional audible noise. Extensive experiments on two speech classification tasks demonstrate the effectiveness of our attack. Furthermore, we analyzed the specific scenarios that activated the proposed backdoor and verified its resistance against fine-tuning.
DSE-TTS: Dual Speaker Embedding for Cross-Lingual Text-to-Speech
Jun 25, 2023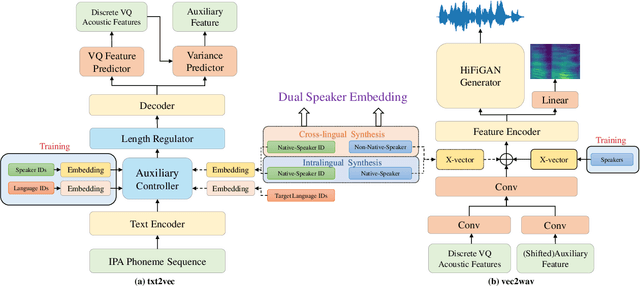
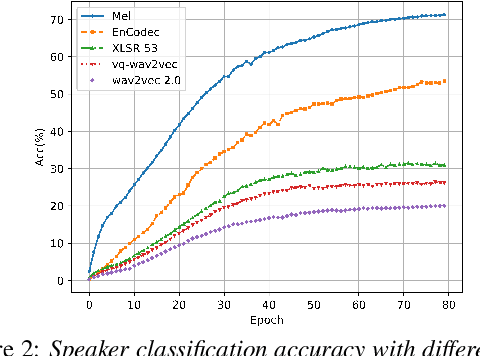
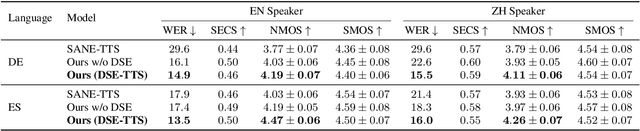
Although high-fidelity speech can be obtained for intralingual speech synthesis, cross-lingual text-to-speech (CTTS) is still far from satisfactory as it is difficult to accurately retain the speaker timbres(i.e. speaker similarity) and eliminate the accents from their first language(i.e. nativeness). In this paper, we demonstrated that vector-quantized(VQ) acoustic feature contains less speaker information than mel-spectrogram. Based on this finding, we propose a novel dual speaker embedding TTS (DSE-TTS) framework for CTTS with authentic speaking style. Here, one embedding is fed to the acoustic model to learn the linguistic speaking style, while the other one is integrated into the vocoder to mimic the target speaker's timbre. Experiments show that by combining both embeddings, DSE-TTS significantly outperforms the state-of-the-art SANE-TTS in cross-lingual synthesis, especially in terms of nativeness.
Masked Modeling Duo for Speech: Specializing General-Purpose Audio Representation to Speech using Denoising Distillation
May 23, 2023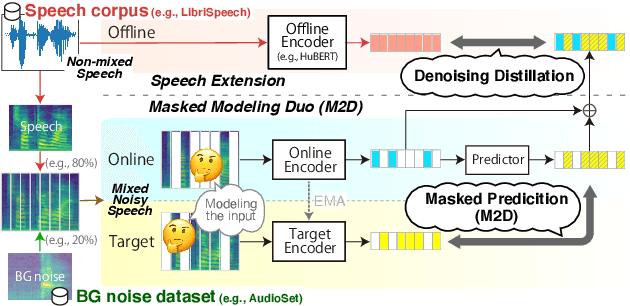

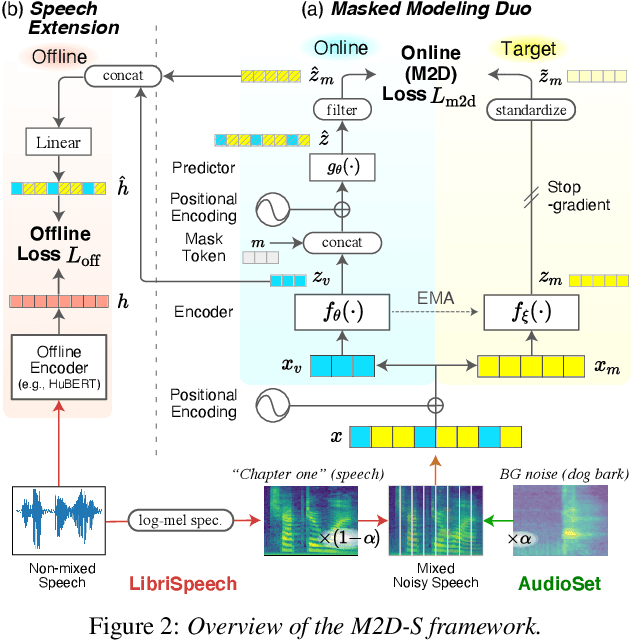
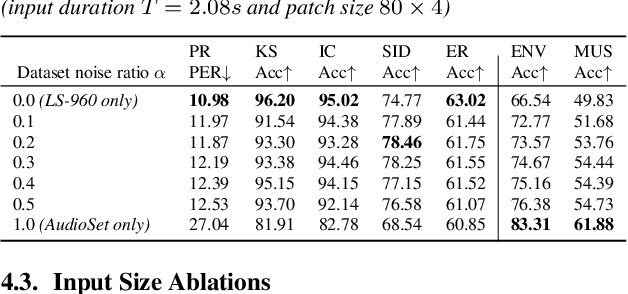
Self-supervised learning general-purpose audio representations have demonstrated high performance in a variety of tasks. Although they can be optimized for application by fine-tuning, even higher performance can be expected if they can be specialized to pre-train for an application. This paper explores the challenges and solutions in specializing general-purpose audio representations for a specific application using speech, a highly demanding field, as an example. We enhance Masked Modeling Duo (M2D), a general-purpose model, to close the performance gap with state-of-the-art (SOTA) speech models. To do so, we propose a new task, denoising distillation, to learn from fine-grained clustered features, and M2D for Speech (M2D-S), which jointly learns the denoising distillation task and M2D masked prediction task. Experimental results show that M2D-S performs comparably to or outperforms SOTA speech models on the SUPERB benchmark, demonstrating that M2D can specialize in a demanding field. Our code is available at: https://github.com/nttcslab/m2d/tree/master/speech
The Art of Embedding Fusion: Optimizing Hate Speech Detection
Jun 26, 2023
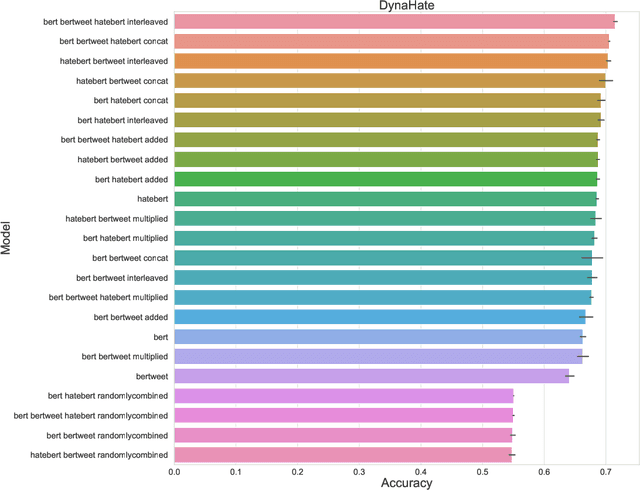


Hate speech detection is a challenging natural language processing task that requires capturing linguistic and contextual nuances. Pre-trained language models (PLMs) offer rich semantic representations of text that can improve this task. However there is still limited knowledge about ways to effectively combine representations across PLMs and leverage their complementary strengths. In this work, we shed light on various combination techniques for several PLMs and comprehensively analyze their effectiveness. Our findings show that combining embeddings leads to slight improvements but at a high computational cost and the choice of combination has marginal effect on the final outcome. We also make our codebase public at https://github.com/aflah02/The-Art-of-Embedding-Fusion-Optimizing-Hate-Speech-Detection .
Prompt-to-OS (P2OS): Revolutionizing Operating Systems and Human-Computer Interaction with Integrated AI Generative Models
Oct 07, 2023In this paper, we present a groundbreaking paradigm for human-computer interaction that revolutionizes the traditional notion of an operating system. Within this innovative framework, user requests issued to the machine are handled by an interconnected ecosystem of generative AI models that seamlessly integrate with or even replace traditional software applications. At the core of this paradigm shift are large generative models, such as language and diffusion models, which serve as the central interface between users and computers. This pioneering approach leverages the abilities of advanced language models, empowering users to engage in natural language conversations with their computing devices. Users can articulate their intentions, tasks, and inquiries directly to the system, eliminating the need for explicit commands or complex navigation. The language model comprehends and interprets the user's prompts, generating and displaying contextual and meaningful responses that facilitate seamless and intuitive interactions. This paradigm shift not only streamlines user interactions but also opens up new possibilities for personalized experiences. Generative models can adapt to individual preferences, learning from user input and continuously improving their understanding and response generation. Furthermore, it enables enhanced accessibility, as users can interact with the system using speech or text, accommodating diverse communication preferences. However, this visionary concept raises significant challenges, including privacy, security, trustability, and the ethical use of generative models. Robust safeguards must be in place to protect user data and prevent potential misuse or manipulation of the language model. While the full realization of this paradigm is still far from being achieved, this paper serves as a starting point for envisioning this transformative potential.
AudioSR: Versatile Audio Super-resolution at Scale
Sep 13, 2023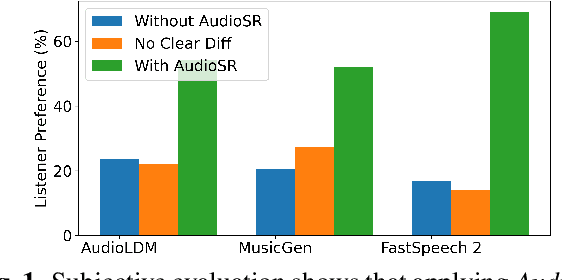

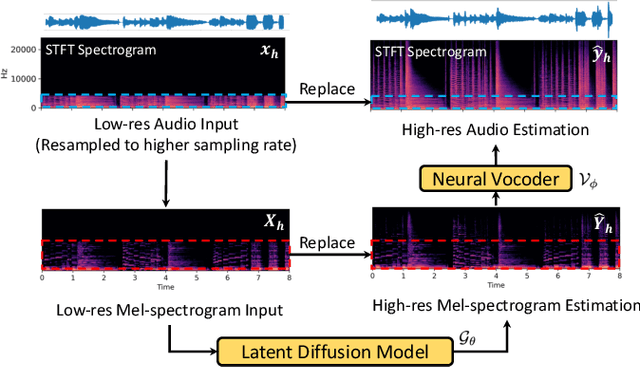

Audio super-resolution is a fundamental task that predicts high-frequency components for low-resolution audio, enhancing audio quality in digital applications. Previous methods have limitations such as the limited scope of audio types (e.g., music, speech) and specific bandwidth settings they can handle (e.g., 4kHz to 8kHz). In this paper, we introduce a diffusion-based generative model, AudioSR, that is capable of performing robust audio super-resolution on versatile audio types, including sound effects, music, and speech. Specifically, AudioSR can upsample any input audio signal within the bandwidth range of 2kHz to 16kHz to a high-resolution audio signal at 24kHz bandwidth with a sampling rate of 48kHz. Extensive objective evaluation on various audio super-resolution benchmarks demonstrates the strong result achieved by the proposed model. In addition, our subjective evaluation shows that AudioSR can acts as a plug-and-play module to enhance the generation quality of a wide range of audio generative models, including AudioLDM, Fastspeech2, and MusicGen. Our code and demo are available at https://audioldm.github.io/audiosr.
A Flexible Online Framework for Projection-Based STFT Phase Retrieval
Sep 13, 2023Several recent contributions in the field of iterative STFT phase retrieval have demonstrated that the performance of the classical Griffin-Lim method can be considerably improved upon. By using the same projection operators as Griffin-Lim, but combining them in innovative ways, these approaches achieve better results in terms of both reconstruction quality and required number of iterations, while retaining a similar computational complexity per iteration. However, like Griffin-Lim, these algorithms operate in an offline manner and thus require an entire spectrogram as input, which is an unrealistic requirement for many real-world speech communication applications. We propose to extend RTISI -- an existing online (frame-by-frame) variant of the Griffin-Lim algorithm -- into a flexible framework that enables straightforward online implementation of any algorithm based on iterative projections. We further employ this framework to implement online variants of the fast Griffin-Lim algorithm, the accelerated Griffin-Lim algorithm, and two algorithms from the optics domain. Evaluation results on speech signals show that, similarly to the offline case, these algorithms can achieve a considerable performance gain compared to RTISI.
LipVoicer: Generating Speech from Silent Videos Guided by Lip Reading
Jun 05, 2023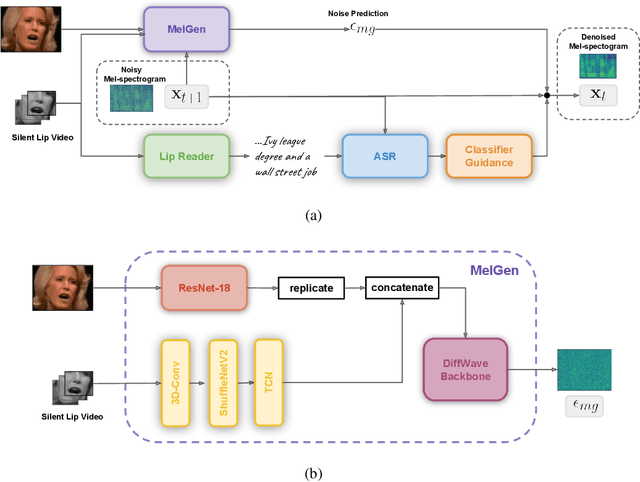
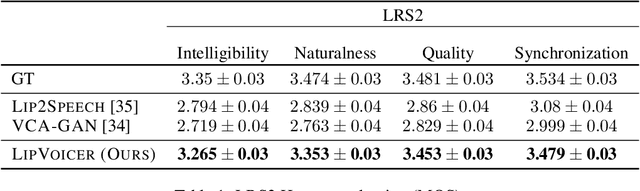
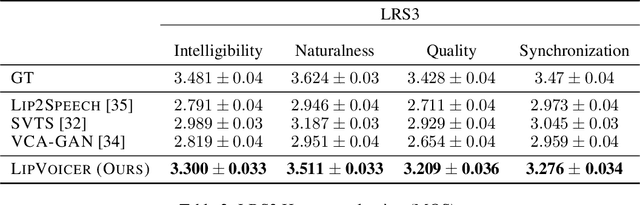
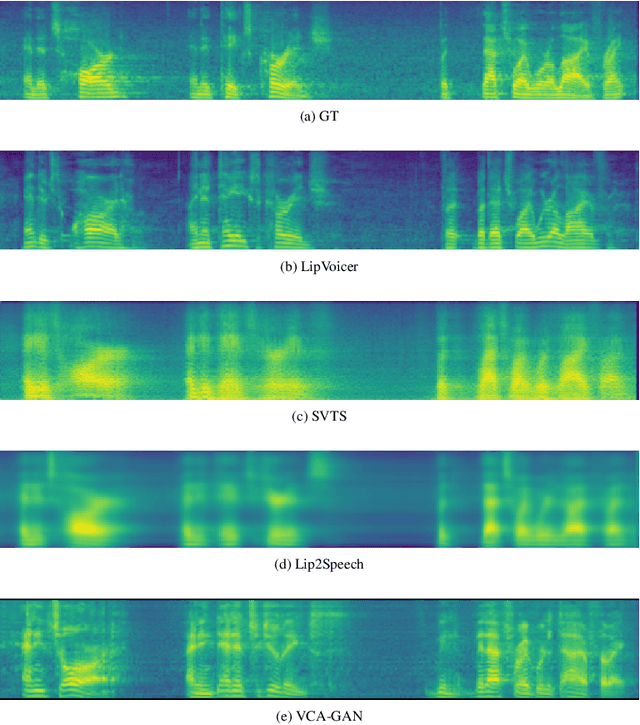
Lip-to-speech involves generating a natural-sounding speech synchronized with a soundless video of a person talking. Despite recent advances, current methods still cannot produce high-quality speech with high levels of intelligibility for challenging and realistic datasets such as LRS3. In this work, we present LipVoicer, a novel method that generates high-quality speech, even for in-the-wild and rich datasets, by incorporating the text modality. Given a silent video, we first predict the spoken text using a pre-trained lip-reading network. We then condition a diffusion model on the video and use the extracted text through a classifier-guidance mechanism where a pre-trained ASR serves as the classifier. LipVoicer outperforms multiple lip-to-speech baselines on LRS2 and LRS3, which are in-the-wild datasets with hundreds of unique speakers in their test set and an unrestricted vocabulary. Moreover, our experiments show that the inclusion of the text modality plays a major role in the intelligibility of the produced speech, readily perceptible while listening, and is empirically reflected in the substantial reduction of the WER metric. We demonstrate the effectiveness of LipVoicer through human evaluation, which shows that it produces more natural and synchronized speech signals compared to competing methods. Finally, we created a demo showcasing LipVoicer's superiority in producing natural, synchronized, and intelligible speech, providing additional evidence of its effectiveness. Project page: https://lipvoicer.github.io