 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhase-Informed Tool Segmentation for Manual Small-Incision Cataract Surgery
Nov 25, 2024



Cataract surgery is the most common surgical procedure globally, with a disproportionately higher burden in developing countries. While automated surgical video analysis has been explored in general surgery, its application to ophthalmic procedures remains limited. Existing works primarily focus on Phaco cataract surgery, an expensive technique not accessible in regions where cataract treatment is most needed. In contrast, Manual Small-Incision Cataract Surgery (MSICS) is the preferred low-cost, faster alternative in high-volume settings and for challenging cases. However, no dataset exists for MSICS. To address this gap, we introduce Cataract-MSICS, the first comprehensive dataset containing 53 surgical videos annotated for 18 surgical phases and 3,527 frames with 13 surgical tools at the pixel level. We benchmark this dataset on state-of-the-art models and present ToolSeg, a novel framework that enhances tool segmentation by introducing a phase-conditional decoder and a simple yet effective semi-supervised setup leveraging pseudo-labels from foundation models. Our approach significantly improves segmentation performance, achieving a $23.77\%$ to $38.10\%$ increase in mean Dice scores, with a notable boost for tools that are less prevalent and small. Furthermore, we demonstrate that ToolSeg generalizes to other surgical settings, showcasing its effectiveness on the CaDIS dataset.
HEALTH-PARIKSHA: Assessing RAG Models for Health Chatbots in Real-World Multilingual Settings
Oct 17, 2024



Assessing the capabilities and limitations of large language models (LLMs) has garnered significant interest, yet the evaluation of multiple models in real-world scenarios remains rare. Multilingual evaluation often relies on translated benchmarks, which typically do not capture linguistic and cultural nuances present in the source language. This study provides an extensive assessment of 24 LLMs on real world data collected from Indian patients interacting with a medical chatbot in Indian English and 4 other Indic languages. We employ a uniform Retrieval Augmented Generation framework to generate responses, which are evaluated using both automated techniques and human evaluators on four specific metrics relevant to our application. We find that models vary significantly in their performance and that instruction tuned Indic models do not always perform well on Indic language queries. Further, we empirically show that factual correctness is generally lower for responses to Indic queries compared to English queries. Finally, our qualitative work shows that code-mixed and culturally relevant queries in our dataset pose challenges to evaluated models.
CataractBot: An LLM-Powered Expert-in-the-Loop Chatbot for Cataract Patients
Feb 07, 2024



The healthcare landscape is evolving, with patients seeking more reliable information about their health conditions, treatment options, and potential risks. Despite the abundance of information sources, the digital age overwhelms individuals with excess, often inaccurate information. Patients primarily trust doctors and hospital staff, highlighting the need for expert-endorsed health information. However, the pressure on experts has led to reduced communication time, impacting information sharing. To address this gap, we propose CataractBot, an experts-in-the-loop chatbot powered by large language models (LLMs). Developed in collaboration with a tertiary eye hospital in India, CataractBot answers cataract surgery related questions instantly by querying a curated knowledge base, and provides expert-verified responses asynchronously. CataractBot features multimodal support and multilingual capabilities. In an in-the-wild deployment study with 49 participants, CataractBot proved valuable, providing anytime accessibility, saving time, and accommodating diverse literacy levels. Trust was established through expert verification. Broadly, our results could inform future work on designing expert-mediated LLM bots.
The Art of Embedding Fusion: Optimizing Hate Speech Detection
Jun 26, 2023Hate speech detection is a challenging natural language processing task that requires capturing linguistic and contextual nuances. Pre-trained language models (PLMs) offer rich semantic representations of text that can improve this task. However there is still limited knowledge about ways to effectively combine representations across PLMs and leverage their complementary strengths. In this work, we shed light on various combination techniques for several PLMs and comprehensively analyze their effectiveness. Our findings show that combining embeddings leads to slight improvements but at a high computational cost and the choice of combination has marginal effect on the final outcome. We also make our codebase public at https://github.com/aflah02/The-Art-of-Embedding-Fusion-Optimizing-Hate-Speech-Detection .
"Can't Take the Pressure?": Examining the Challenges of Blood Pressure Estimation via Pulse Wave Analysis
Apr 23, 2023



The use of observed wearable sensor data (e.g., photoplethysmograms [PPG]) to infer health measures (e.g., glucose level or blood pressure) is a very active area of research. Such technology can have a significant impact on health screening, chronic disease management and remote monitoring. A common approach is to collect sensor data and corresponding labels from a clinical grade device (e.g., blood pressure cuff), and train deep learning models to map one to the other. Although well intentioned, this approach often ignores a principled analysis of whether the input sensor data has enough information to predict the desired metric. We analyze the task of predicting blood pressure from PPG pulse wave analysis. Our review of the prior work reveals that many papers fall prey data leakage, and unrealistic constraints on the task and the preprocessing steps. We propose a set of tools to help determine if the input signal in question (e.g., PPG) is indeed a good predictor of the desired label (e.g., blood pressure). Using our proposed tools, we have found that blood pressure prediction using PPG has a high multi-valued mapping factor of 33.2% and low mutual information of 9.8%. In comparison, heart rate prediction using PPG, a well-established task, has a very low multi-valued mapping factor of 0.75% and high mutual information of 87.7%. We argue that these results provide a more realistic representation of the current progress towards to goal of wearable blood pressure measurement via PPG pulse wave analysis.
Visual Reinforcement Learning with Self-Supervised 3D Representations
Oct 13, 2022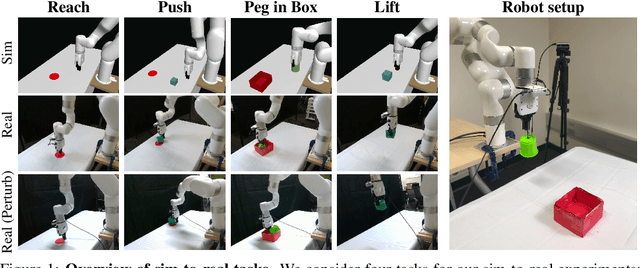

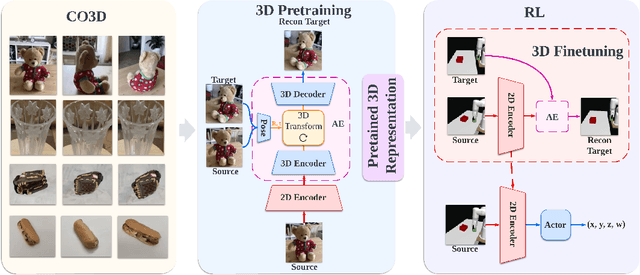

A prominent approach to visual Reinforcement Learning (RL) is to learn an internal state representation using self-supervised methods, which has the potential benefit of improved sample-efficiency and generalization through additional learning signal and inductive biases. However, while the real world is inherently 3D, prior efforts have largely been focused on leveraging 2D computer vision techniques as auxiliary self-supervision. In this work, we present a unified framework for self-supervised learning of 3D representations for motor control. Our proposed framework consists of two phases: a pretraining phase where a deep voxel-based 3D autoencoder is pretrained on a large object-centric dataset, and a finetuning phase where the representation is jointly finetuned together with RL on in-domain data. We empirically show that our method enjoys improved sample efficiency in simulated manipulation tasks compared to 2D representation learning methods. Additionally, our learned policies transfer zero-shot to a real robot setup with only approximate geometric correspondence, and successfully solve motor control tasks that involve grasping and lifting from a single, uncalibrated RGB camera. Code and videos are available at https://yanjieze.com/3d4rl/ .
Towards Automating Retinoscopy for Refractive Error Diagnosis
Aug 10, 2022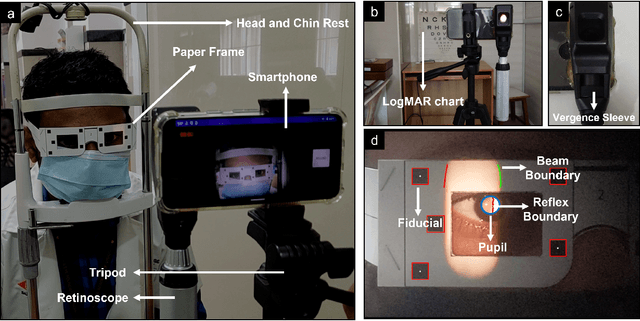
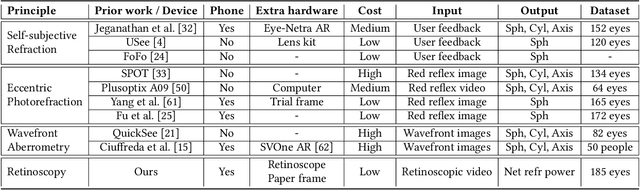

Refractive error is the most common eye disorder and is the key cause behind correctable visual impairment, responsible for nearly 80% of the visual impairment in the US. Refractive error can be diagnosed using multiple methods, including subjective refraction, retinoscopy, and autorefractors. Although subjective refraction is the gold standard, it requires cooperation from the patient and hence is not suitable for infants, young children, and developmentally delayed adults. Retinoscopy is an objective refraction method that does not require any input from the patient. However, retinoscopy requires a lens kit and a trained examiner, which limits its use for mass screening. In this work, we automate retinoscopy by attaching a smartphone to a retinoscope and recording retinoscopic videos with the patient wearing a custom pair of paper frames. We develop a video processing pipeline that takes retinoscopic videos as input and estimates the net refractive error based on our proposed extension of the retinoscopy mathematical model. Our system alleviates the need for a lens kit and can be performed by an untrained examiner. In a clinical trial with 185 eyes, we achieved a sensitivity of 91.0% and specificity of 74.0% on refractive error diagnosis. Moreover, the mean absolute error of our approach was 0.75$\pm$0.67D on net refractive error estimation compared to subjective refraction measurements. Our results indicate that our approach has the potential to be used as a retinoscopy-based refractive error screening tool in real-world medical settings.
Keratoconus Classifier for Smartphone-based Corneal Topographer
May 07, 2022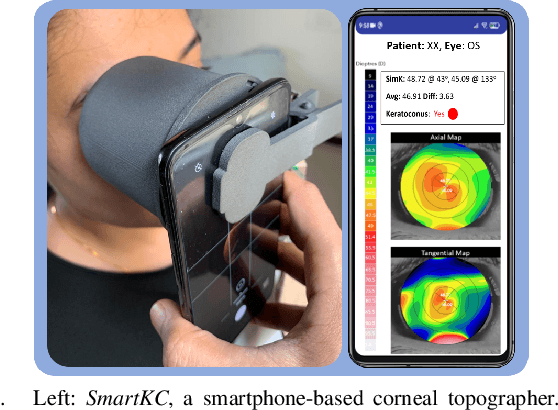
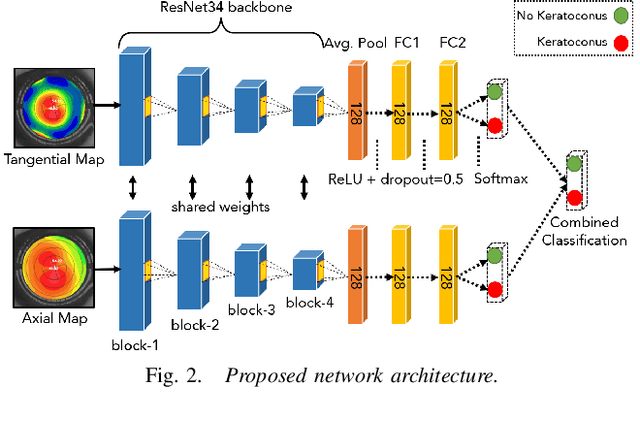
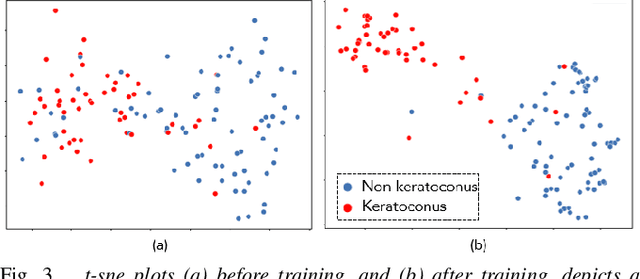
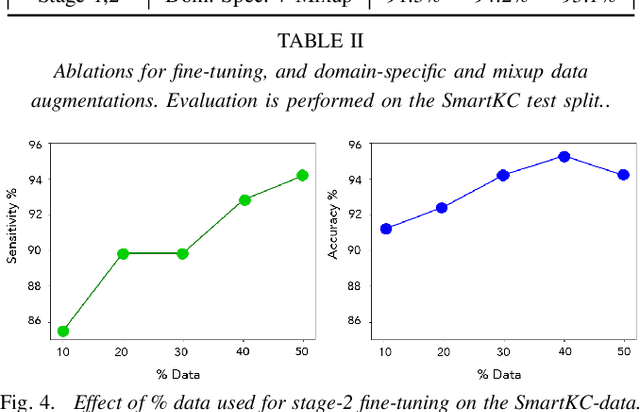
Keratoconus is a severe eye disease that leads to deformation of the cornea. It impacts people aged 10-25 years and is the leading cause of blindness in that demography. Corneal topography is the gold standard for keratoconus diagnosis. It is a non-invasive process performed using expensive and bulky medical devices called corneal topographers. This makes it inaccessible to large populations, especially in the Global South. Low-cost smartphone-based corneal topographers, such as SmartKC, have been proposed to make keratoconus diagnosis accessible. Similar to medical-grade topographers, SmartKC outputs curvature heatmaps and quantitative metrics that need to be evaluated by doctors for keratoconus diagnosis. An automatic scheme for evaluation of these heatmaps and quantitative values can play a crucial role in screening keratoconus in areas where doctors are not available. In this work, we propose a dual-head convolutional neural network (CNN) for classifying keratoconus on the heatmaps generated by SmartKC. Since SmartKC is a new device and only had a small dataset (114 samples), we developed a 2-stage transfer learning strategy -- using historical data collected from a medical-grade topographer and a subset of SmartKC data -- to satisfactorily train our network. This, combined with our domain-specific data augmentations, achieved a sensitivity of 91.3% and a specificity of 94.2%.
Global Readiness of Language Technology for Healthcare: What would it Take to Combat the Next Pandemic?
Apr 06, 2022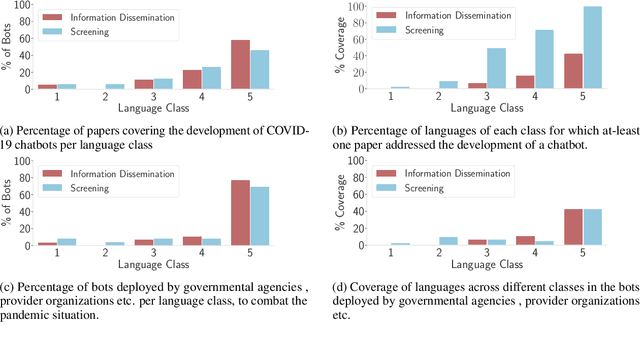
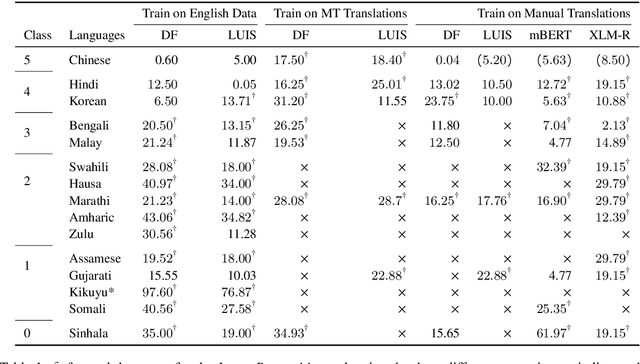
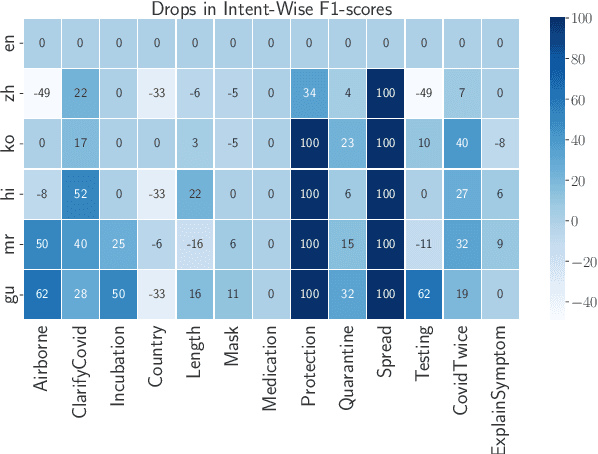

The COVID-19 pandemic has brought out both the best and worst of language technology (LT). On one hand, conversational agents for information dissemination and basic diagnosis have seen widespread use, and arguably, had an important role in combating the pandemic. On the other hand, it has also become clear that such technologies are readily available for a handful of languages, and the vast majority of the global south is completely bereft of these benefits. What is the state of LT, especially conversational agents, for healthcare across the world's languages? And, what would it take to ensure global readiness of LT before the next pandemic? In this paper, we try to answer these questions through survey of existing literature and resources, as well as through a rapid chatbot building exercise for 15 Asian and African languages with varying amount of resource-availability. The study confirms the pitiful state of LT even for languages with large speaker bases, such as Sinhala and Hausa, and identifies the gaps that could help us prioritize research and investment strategies in LT for healthcare.
Look Closer: Bridging Egocentric and Third-Person Views with Transformers for Robotic Manipulation
Jan 20, 2022
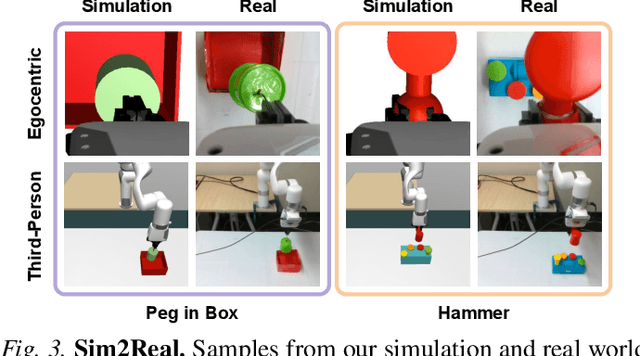
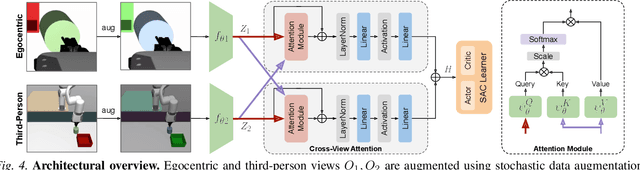

Learning to solve precision-based manipulation tasks from visual feedback using Reinforcement Learning (RL) could drastically reduce the engineering efforts required by traditional robot systems. However, performing fine-grained motor control from visual inputs alone is challenging, especially with a static third-person camera as often used in previous work. We propose a setting for robotic manipulation in which the agent receives visual feedback from both a third-person camera and an egocentric camera mounted on the robot's wrist. While the third-person camera is static, the egocentric camera enables the robot to actively control its vision to aid in precise manipulation. To fuse visual information from both cameras effectively, we additionally propose to use Transformers with a cross-view attention mechanism that models spatial attention from one view to another (and vice-versa), and use the learned features as input to an RL policy. Our method improves learning over strong single-view and multi-view baselines, and successfully transfers to a set of challenging manipulation tasks on a real robot with uncalibrated cameras, no access to state information, and a high degree of task variability. In a hammer manipulation task, our method succeeds in 75% of trials versus 38% and 13% for multi-view and single-view baselines, respectively.