 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinearly Constrained Deep Beamformer for Multi-Speaker Scenarios
May 20, 2026We propose a deep beamforming framework for enhancing target speaker(s) in multi-speaker environments. A deep neural network (DNN) is trained to estimate beamforming weights directly from noisy multichannel inputs while satisfying linear spatial constraints through an adaptive multi-term loss inspired by the augmented Lagrangian framework. The loss combines signal reconstruction with penalties that enforce a distortionless response toward the target and suppress the interference subspace. The model is further guided by the target relative transfer function (RTF) and the estimated interference subspace. The proposed model can direct a beam toward the target speaker while directing nulls toward the interfering sources, achieving superior overall enhancement performance compared with the classical LCMV beamformer constructed by the same estimated spatial signatures. Furthermore, compared with the LCMV beamformer, the proposed model produces more controlled sidelobes and improved background-noise attenuation.
Speakers Localization Using Batch EM In Unfolding Neural Network
Mar 17, 2026We propose an interpretable Batch-EM Unfolded Network for robust speaker localization. By embedding the iterative EM procedure within an encoder-EM-decoder architecture, the method mitigates initialization sensitivity and improves convergence. Experiments show superior accuracy and robustness over the classical Batch-EM in reverberant conditions.
HRTF-guided Binaural Target Speaker Extraction with Real-World Validation
Mar 17, 2026This paper presents a Head-Related Transfer Function (HRTF)-guided framework for binaural Target Speaker Extraction (TSE) from mixtures of concurrent sources. Unlike conventional TSE methods based on Direction of Arrival (DOA) estimation or enrollment signals, which often distort perceived spatial location, the proposed approach leverages the listener's HRTF as an explicit spatial prior. The proposed framework is built upon a multi-channel deep blind source separation backbone, adapted to the binaural TSE setting. It is trained on measured HRTFs from a diverse population, enabling cross-listener generalization rather than subject-specific tuning. By conditioning the extraction on HRTF-derived spatial information, the method preserves binaural cues while enhancing speech quality and intelligibility. The performance of the proposed framework is validated through simulations and real recordings obtained from a head and torso simulator (HATS).
SSNAPS: Audio-Visual Separation of Speech and Background Noise with Diffusion Inverse Sampling
Feb 01, 2026This paper addresses the challenge of audio-visual single-microphone speech separation and enhancement in the presence of real-world environmental noise. Our approach is based on generative inverse sampling, where we model clean speech and ambient noise with dedicated diffusion priors and jointly leverage them to recover all underlying sources. To achieve this, we reformulate a recent inverse sampler to match our setting. We evaluate on mixtures of 1, 2, and 3 speakers with noise and show that, despite being entirely unsupervised, our method consistently outperforms leading supervised baselines in \ac{WER} across all conditions. We further extend our framework to handle off-screen speaker separation. Moreover, the high fidelity of the separated noise component makes it suitable for downstream acoustic scene detection. Demo page: https://ssnapsicml.github.io/ssnapsicml2026/
AMDM-SE: Attention-based Multichannel Diffusion Model for Speech Enhancement
Jan 19, 2026Diffusion models have recently achieved impressive results in reconstructing images from noisy inputs, and similar ideas have been applied to speech enhancement by treating time-frequency representations as images. With the ubiquity of multi-microphone devices, we extend state-of-the-art diffusion-based methods to exploit multichannel inputs for improved performance. Multichannel diffusion-based enhancement remains in its infancy, with prior work making limited use of advanced mechanisms such as attention for spatial modeling - a gap addressed in this paper. We propose AMDM-SE, an Attention-based Multichannel Diffusion Model for Speech Enhancement, designed specifically for noise reduction. AMDM-SE leverages spatial inter-channel information through a novel cross-channel time-frequency attention block, enabling faithful reconstruction of fine-grained signal details within a generative diffusion framework. On the CHiME-3 benchmark, AMDM-SE outperforms both a single-channel diffusion baseline and a multichannel model without attention, as well as a strong DNN-based predictive method. Simulated-data experiments further underscore the importance of the proposed multichannel attention mechanism. Overall, our results show that incorporating targeted multichannel attention into diffusion models substantially improves noise reduction. While multichannel diffusion-based speech enhancement is still an emerging field, our work contributes a new and complementary approach to the growing body of research in this direction.
Spectral or spatial? Leveraging both for speaker extraction in challenging data conditions
Dec 23, 2025This paper presents a robust multi-channel speaker extraction algorithm designed to handle inaccuracies in reference information. While existing approaches often rely solely on either spatial or spectral cues to identify the target speaker, our method integrates both sources of information to enhance robustness. A key aspect of our approach is its emphasis on stability, ensuring reliable performance even when one of the features is degraded or misleading. Given a noisy mixture and two potentially unreliable cues, a dedicated network is trained to dynamically balance their contributions-or disregard the less informative one when necessary. We evaluate the system under challenging conditions by simulating inference-time errors using a simple direction of arrival (DOA) estimator and a noisy spectral enrollment process. Experimental results demonstrate that the proposed model successfully extracts the desired speaker even in the presence of substantial reference inaccuracies.
A Study of Binaural Deep Beamforming With Interpretable Beampatterns Guided by Time-Varying RTF
Nov 13, 2025



In this work, a deep beamforming framework for speech enhancement in dynamic acoustic environments is studied. The time-varying beamformer weights are estimated from the noisy multichannel signals by minimizing an SI-SDR loss. The estimation is guided by the continuously tracked relative transfer functions (RTFs) of the moving target speaker. The spatial behavior of the network is evaluated through both narrowband and wideband beampatterns under three settings: (i) oracle guidance using true RTFs, (ii) estimated RTFs obtained by a subspace tracking method, and (iii) without the RTF guidance. Results show that RTF-guided models produce smoother, spatially consistent beampatterns that accurately track the target's direction of arrival. In contrast, the model fails to maintain a clear spatial focus when guidance is absent. Using the estimated RTFs as guidance closely matches the oracle RTF behavior, confirming the effectiveness of the tracking scheme. The model also outputs a binaural signal to preserve the speaker's spatial cues, which promotes hearing aid and hearables applications.
(SP)$^2$-Net: A Neural Spatial Spectrum Method for DOA Estimation
Sep 18, 2025

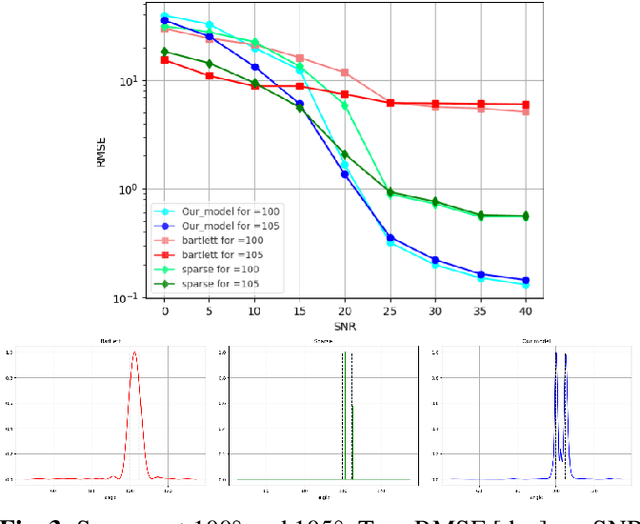
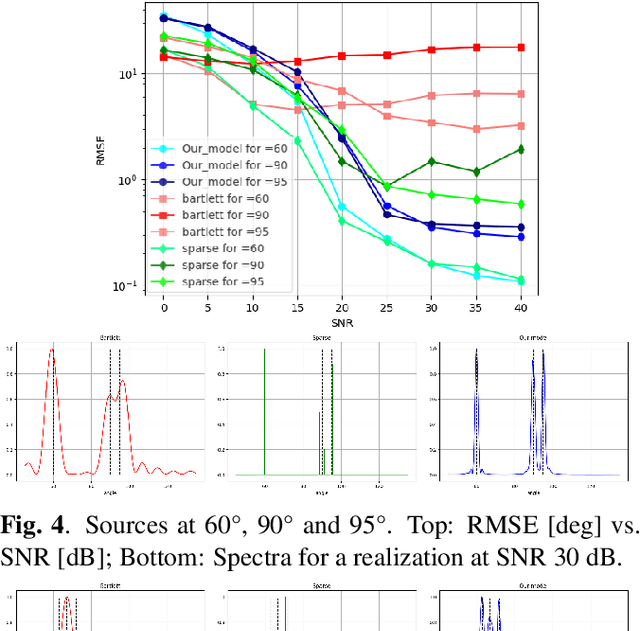
We consider the problem of estimating the directions of arrival (DOAs) of multiple sources from a single snapshot of an antenna array, a task with many practical applications. In such settings, the classical Bartlett beamformer is commonly used, as maximum likelihood estimation becomes impractical when the number of sources is unknown or large, and spectral methods based on the sample covariance are not applicable due to the lack of multiple snapshots. However, the accuracy and resolution of the Bartlett beamformer are fundamentally limited by the array aperture. In this paper, we propose a deep learning technique, comprising a novel architecture and training strategy, for generating a high-resolution spatial spectrum from a single snapshot. Specifically, we train a deep neural network that takes the measurements and a hypothesis angle as input and learns to output a score consistent with the capabilities of a much wider array. At inference time, a heatmap can be produced by scanning an arbitrary set of angles. We demonstrate the advantages of our trained model, named (SP)$^2$-Net, over the Bartlett beamformer and sparsity-based DOA estimation methods.
Transient Noise Removal via Diffusion-based Speech Inpainting
Aug 12, 2025In this paper, we present PGDI, a diffusion-based speech inpainting framework for restoring missing or severely corrupted speech segments. Unlike previous methods that struggle with speaker variability or long gap lengths, PGDI can accurately reconstruct gaps of up to one second in length while preserving speaker identity, prosody, and environmental factors such as reverberation. Central to this approach is classifier guidance, specifically phoneme-level guidance, which substantially improves reconstruction fidelity. PGDI operates in a speaker-independent manner and maintains robustness even when long segments are completely masked by strong transient noise, making it well-suited for real-world applications, such as fireworks, door slams, hammer strikes, and construction noise. Through extensive experiments across diverse speakers and gap lengths, we demonstrate PGDI's superior inpainting performance and its ability to handle challenging acoustic conditions. We consider both scenarios, with and without access to the transcript during inference, showing that while the availability of text further enhances performance, the model remains effective even in its absence. For audio samples, visit: https://mordehaym.github.io/PGDI/
Video Editing for Audio-Visual Dubbing
May 29, 2025Visual dubbing, the synchronization of facial movements with new speech, is crucial for making content accessible across different languages, enabling broader global reach. However, current methods face significant limitations. Existing approaches often generate talking faces, hindering seamless integration into original scenes, or employ inpainting techniques that discard vital visual information like partial occlusions and lighting variations. This work introduces EdiDub, a novel framework that reformulates visual dubbing as a content-aware editing task. EdiDub preserves the original video context by utilizing a specialized conditioning scheme to ensure faithful and accurate modifications rather than mere copying. On multiple benchmarks, including a challenging occluded-lip dataset, EdiDub significantly improves identity preservation and synchronization. Human evaluations further confirm its superiority, achieving higher synchronization and visual naturalness scores compared to the leading methods. These results demonstrate that our content-aware editing approach outperforms traditional generation or inpainting, particularly in maintaining complex visual elements while ensuring accurate lip synchronization.