 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescription and Discussion on DCASE 2026 Challenge Task 4: Spatial Semantic Segmentation of Sound Scenes
Apr 01, 2026This paper presents an overview of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2026 Challenge Task 4, Spatial Semantic Segmentation of Sound Scenes (S5). The S5 task focuses on the joint detection and separation of sound events in complex spatial audio mixtures, contributing to the foundation of immersive communication. First introduced in DCASE 2025, the S5 task continues in DCASE 2026 Task 4 with key changes to better reflect real-world conditions, including allowing mixtures to contain multiple sources of the same class and to contain no target sources. In this paper, we describe task setting, along with the corresponding updates to the evaluation metrics and dataset. The experimental results of the submitted systems are also reported and analyzed. The official access point for data and code is https://github.com/nttcslab/dcase2026_task4_baseline.
Rethinking Masking Strategies for Masked Prediction-based Audio Self-supervised Learning
Mar 25, 2026Since the introduction of Masked Autoencoders, various improvements to masking techniques have been explored. In this paper, we rethink masking strategies for audio representation learning using masked prediction-based self-supervised learning (SSL) on general audio spectrograms. While recent informed masking techniques have attracted attention, we observe that they incur substantial computational overhead. Motivated by this observation, we propose dispersion-weighted masking (DWM), a lightweight masking strategy that leverages the spectral sparsity inherent in the frequency structure of audio content. Our experiments show that inverse block masking, commonly used in recent SSL frameworks, improves audio event understanding performance while introducing a trade-off in generalization. The proposed DWM alleviates these limitations and computational complexity, leading to consistent performance improvements. This work provides practical guidance on masking strategy design for masked prediction-based audio representation learning.
Entropy-Guided GRVQ for Ultra-Low Bitrate Neural Speech Codec
Mar 02, 2026Neural audio codec (NAC) is essential for reconstructing high-quality speech signals and generating discrete representations for downstream speech language models. However, ensuring accurate semantic modeling while maintaining high-fidelity reconstruction under ultra-low bitrate constraints remains challenging. We propose an entropy-guided group residual vector quantization (EG-GRVQ) for an ultra-low bitrate neural speech codec, which retains a semantic branch for linguistic information and incorporates an entropy-guided grouping strategy in the acoustic branch. Assuming that channel activations follow approximately Gaussian statistics, the variance of each channel can serve as a principled proxy for its information content. Based on this assumption, we partition the encoder output such that each group carries an equal share of the total information. This balanced allocation improves codebook efficiency and reduces redundancy. Trained on LibriTTS and VCTK, our model shows improvements in perceptual quality and intelligibility metrics under ultra-low bitrate conditions, with a focus on codec-level fidelity for communication-oriented scenarios.
Class-Aware Permutation-Invariant Signal-to-Distortion Ratio for Semantic Segmentation of Sound Scene with Same-Class Sources
Jan 30, 2026To advance immersive communication, the Detection and Classification of Acoustic Scenes and Events (DCASE) 2025 Challenge recently introduced Task 4 on Spatial Semantic Segmentation of Sound Scenes (S5). An S5 system takes a multi-channel audio mixture as input and outputs single-channel dry sources along with their corresponding class labels. Although the DCASE 2025 Challenge simplifies the task by constraining class labels in each mixture to be mutually exclusive, real-world mixtures frequently contain multiple sources from the same class. The presence of duplicated labels can significantly degrade the performance of the label-queried source separation (LQSS) model, which is the key component of many existing S5 systems, and can also limit the validity of the official evaluation metric of DCASE 2025 Task 4. To address these issues, we propose a class-aware permutation-invariant loss function that enables the LQSS model to handle queries involving duplicated labels. In addition, we redesign the S5 evaluation metric to eliminate ambiguities caused by these same-class sources. To evaluate the proposed method within the S5 system, we extend the label prediction model to support same-class labels. Experimental results demonstrate the effectiveness of the proposed methods and the robustness of the new metric on mixtures both with and without same-class sources.
Description and Discussion on DCASE 2025 Challenge Task 4: Spatial Semantic Segmentation of Sound Scenes
Jun 12, 2025

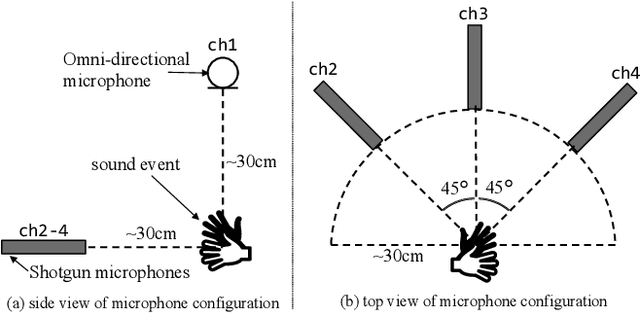
Spatial Semantic Segmentation of Sound Scenes (S5) aims to enhance technologies for sound event detection and separation from multi-channel input signals that mix multiple sound events with spatial information. This is a fundamental basis of immersive communication. The ultimate goal is to separate sound event signals with 6 Degrees of Freedom (6DoF) information into dry sound object signals and metadata about the object type (sound event class) and representing spatial information, including direction. However, because several existing challenge tasks already provide some of the subset functions, this task for this year focuses on detecting and separating sound events from multi-channel spatial input signals. This paper outlines the S5 task setting of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2025 Challenge Task 4 and the DCASE2025 Task 4 Dataset, newly recorded and curated for this task. We also report experimental results for an S5 system trained and evaluated on this dataset. The full version of this paper will be published after the challenge results are made public.
Towards Pre-training an Effective Respiratory Audio Foundation Model
May 21, 2025Recent advancements in foundation models have sparked interest in respiratory audio foundation models. However, the effectiveness of applying conventional pre-training schemes to datasets that are small-sized and lack diversity has not been sufficiently verified. This study aims to explore better pre-training practices for respiratory sounds by comparing numerous pre-trained audio models. Our investigation reveals that models pre-trained on AudioSet, a general audio dataset, are more effective than the models specifically pre-trained on respiratory sounds. Moreover, combining AudioSet and respiratory sound datasets for further pre-training enhances performance, and preserving the frequency-wise information when aggregating features is vital. Along with more insights found in the experiments, we establish a new state-of-the-art for the OPERA benchmark, contributing to advancing respiratory audio foundation models. Our code is available online at https://github.com/nttcslab/eval-audio-repr/tree/main/plugin/OPERA.
Assessing the Utility of Audio Foundation Models for Heart and Respiratory Sound Analysis
Apr 25, 2025



Pre-trained deep learning models, known as foundation models, have become essential building blocks in machine learning domains such as natural language processing and image domains. This trend has extended to respiratory and heart sound models, which have demonstrated effectiveness as off-the-shelf feature extractors. However, their evaluation benchmarking has been limited, resulting in incompatibility with state-of-the-art (SOTA) performance, thus hindering proof of their effectiveness. This study investigates the practical effectiveness of off-the-shelf audio foundation models by comparing their performance across four respiratory and heart sound tasks with SOTA fine-tuning results. Experiments show that models struggled on two tasks with noisy data but achieved SOTA performance on the other tasks with clean data. Moreover, general-purpose audio models outperformed a respiratory sound model, highlighting their broader applicability. With gained insights and the released code, we contribute to future research on developing and leveraging foundation models for respiratory and heart sounds.
Baseline Systems and Evaluation Metrics for Spatial Semantic Segmentation of Sound Scenes
Mar 28, 2025Immersive communication has made significant advancements, especially with the release of the codec for Immersive Voice and Audio Services. Aiming at its further realization, the DCASE 2025 Challenge has recently introduced a task for spatial semantic segmentation of sound scenes (S5), which focuses on detecting and separating sound events in spatial sound scenes. In this paper, we explore methods for addressing the S5 task. Specifically, we present baseline S5 systems that combine audio tagging (AT) and label-queried source separation (LSS) models. We investigate two LSS approaches based on the ResUNet architecture: a) extracting a single source for each detected event and b) querying multiple sources concurrently. Since each separated source in S5 is identified by its sound event class label, we propose new class-aware metrics to evaluate both the sound sources and labels simultaneously. Experimental results on first-order ambisonics spatial audio demonstrate the effectiveness of the proposed systems and confirm the efficacy of the metrics.
M2D2: Exploring General-purpose Audio-Language Representations Beyond CLAP
Mar 28, 2025Contrastive language-audio pre-training (CLAP) has addressed audio-language tasks such as audio-text retrieval by aligning audio and text in a common feature space. While CLAP addresses general audio-language tasks, its audio features do not generalize well in audio tasks. In contrast, self-supervised learning (SSL) models learn general-purpose audio features that perform well in diverse audio tasks. We pursue representation learning that can be widely used in audio applications and hypothesize that a method that learns both general audio features and CLAP features should achieve our goal, which we call a general-purpose audio-language representation. To implement our hypothesis, we propose M2D2, a second-generation masked modeling duo (M2D) that combines an SSL M2D and CLAP. M2D2 learns two types of features using two modalities (audio and text) in a two-stage training process. It also utilizes advanced LLM-based sentence embeddings in CLAP training for powerful semantic supervision. In the first stage, M2D2 learns generalizable audio features from M2D and CLAP, where CLAP aligns the features with the fine LLM-based semantic embeddings. In the second stage, it learns CLAP features using the audio features learned from the LLM-based embeddings. Through these pre-training stages, M2D2 should enhance generalizability and performance in its audio and CLAP features. Experiments validated that M2D2 achieves effective general-purpose audio-language representation, highlighted with SOTA fine-tuning mAP of 49.0 for AudioSet, SOTA performance in music tasks, and top-level performance in audio-language tasks.
M2D-CLAP: Masked Modeling Duo Meets CLAP for Learning General-purpose Audio-Language Representation
Jun 04, 2024



Contrastive language-audio pre-training (CLAP) enables zero-shot (ZS) inference of audio and exhibits promising performance in several classification tasks. However, conventional audio representations are still crucial for many tasks where ZS is not applicable (e.g., regression problems). Here, we explore a new representation, a general-purpose audio-language representation, that performs well in both ZS and transfer learning. To do so, we propose a new method, M2D-CLAP, which combines self-supervised learning Masked Modeling Duo (M2D) and CLAP. M2D learns an effective representation to model audio signals, and CLAP aligns the representation with text embedding. As a result, M2D-CLAP learns a versatile representation that allows for both ZS and transfer learning. Experiments show that M2D-CLAP performs well on linear evaluation, fine-tuning, and ZS classification with a GTZAN state-of-the-art of 75.17%, thus achieving a general-purpose audio-language representation.