 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Pre-trained General-purpose Audio Representations for Heart Murmur Detection
Apr 26, 2024



To reduce the need for skilled clinicians in heart sound interpretation, recent studies on automating cardiac auscultation have explored deep learning approaches. However, despite the demands for large data for deep learning, the size of the heart sound datasets is limited, and no pre-trained model is available. On the contrary, many pre-trained models for general audio tasks are available as general-purpose audio representations. This study explores the potential of general-purpose audio representations pre-trained on large-scale datasets for transfer learning in heart murmur detection. Experiments on the CirCor DigiScope heart sound dataset show that the recent self-supervised learning Masked Modeling Duo (M2D) outperforms previous methods with the results of a weighted accuracy of 0.832 and an unweighted average recall of 0.713. Experiments further confirm improved performance by ensembling M2D with other models. These results demonstrate the effectiveness of general-purpose audio representation in processing heart sounds and open the way for further applications. Our code is available online which runs on a 24 GB consumer GPU at https://github.com/nttcslab/m2d/tree/master/app/circor
Masked Modeling Duo: Towards a Universal Audio Pre-training Framework
Apr 09, 2024



Self-supervised learning (SSL) using masked prediction has made great strides in general-purpose audio representation. This study proposes Masked Modeling Duo (M2D), an improved masked prediction SSL, which learns by predicting representations of masked input signals that serve as training signals. Unlike conventional methods, M2D obtains a training signal by encoding only the masked part, encouraging the two networks in M2D to model the input. While M2D improves general-purpose audio representations, a specialized representation is essential for real-world applications, such as in industrial and medical domains. The often confidential and proprietary data in such domains is typically limited in size and has a different distribution from that in pre-training datasets. Therefore, we propose M2D for X (M2D-X), which extends M2D to enable the pre-training of specialized representations for an application X. M2D-X learns from M2D and an additional task and inputs background noise. We make the additional task configurable to serve diverse applications, while the background noise helps learn on small data and forms a denoising task that makes representation robust. With these design choices, M2D-X should learn a representation specialized to serve various application needs. Our experiments confirmed that the representations for general-purpose audio, specialized for the highly competitive AudioSet and speech domain, and a small-data medical task achieve top-level performance, demonstrating the potential of using our models as a universal audio pre-training framework. Our code is available online for future studies at https://github.com/nttcslab/m2d
Deep Attentive Time Warping
Sep 13, 2023



Similarity measures for time series are important problems for time series classification. To handle the nonlinear time distortions, Dynamic Time Warping (DTW) has been widely used. However, DTW is not learnable and suffers from a trade-off between robustness against time distortion and discriminative power. In this paper, we propose a neural network model for task-adaptive time warping. Specifically, we use the attention model, called the bipartite attention model, to develop an explicit time warping mechanism with greater distortion invariance. Unlike other learnable models using DTW for warping, our model predicts all local correspondences between two time series and is trained based on metric learning, which enables it to learn the optimal data-dependent warping for the target task. We also propose to induce pre-training of our model by DTW to improve the discriminative power. Extensive experiments demonstrate the superior effectiveness of our model over DTW and its state-of-the-art performance in online signature verification.
Audio Difference Captioning Utilizing Similarity-Discrepancy Disentanglement
Aug 23, 2023


We proposed Audio Difference Captioning (ADC) as a new extension task of audio captioning for describing the semantic differences between input pairs of similar but slightly different audio clips. The ADC solves the problem that conventional audio captioning sometimes generates similar captions for similar audio clips, failing to describe the difference in content. We also propose a cross-attention-concentrated transformer encoder to extract differences by comparing a pair of audio clips and a similarity-discrepancy disentanglement to emphasize the difference in the latent space. To evaluate the proposed methods, we built an AudioDiffCaps dataset consisting of pairs of similar but slightly different audio clips with human-annotated descriptions of their differences. The experiment with the AudioDiffCaps dataset showed that the proposed methods solve the ADC task effectively and improve the attention weights to extract the difference by visualizing them in the transformer encoder.
Masked Modeling Duo for Speech: Specializing General-Purpose Audio Representation to Speech using Denoising Distillation
May 23, 2023Self-supervised learning general-purpose audio representations have demonstrated high performance in a variety of tasks. Although they can be optimized for application by fine-tuning, even higher performance can be expected if they can be specialized to pre-train for an application. This paper explores the challenges and solutions in specializing general-purpose audio representations for a specific application using speech, a highly demanding field, as an example. We enhance Masked Modeling Duo (M2D), a general-purpose model, to close the performance gap with state-of-the-art (SOTA) speech models. To do so, we propose a new task, denoising distillation, to learn from fine-grained clustered features, and M2D for Speech (M2D-S), which jointly learns the denoising distillation task and M2D masked prediction task. Experimental results show that M2D-S performs comparably to or outperforms SOTA speech models on the SUPERB benchmark, demonstrating that M2D can specialize in a demanding field. Our code is available at: https://github.com/nttcslab/m2d/tree/master/speech
Masked Modeling Duo: Learning Representations by Encouraging Both Networks to Model the Input
Oct 26, 2022Masked Autoencoders is a simple yet powerful self-supervised learning method. However, it learns representations indirectly by reconstructing masked input patches. Several methods learn representations directly by predicting representations of masked patches; however, we think using all patches to encode training signal representations is suboptimal. We propose a new method, Masked Modeling Duo (M2D), that learns representations directly while obtaining training signals using only masked patches. In the M2D, the online network encodes visible patches and predicts masked patch representations, and the target network, a momentum encoder, encodes masked patches. To better predict target representations, the online network should model the input well, while the target network should also model it well to agree with online predictions. Then the learned representations should better model the input. We validated the M2D by learning general-purpose audio representations, and M2D set new state-of-the-art performance on tasks such as UrbanSound8K, VoxCeleb1, AudioSet20K, GTZAN, and SpeechCommandsV2.
Reflectance-Oriented Probabilistic Equalization for Image Enhancement
Sep 14, 2022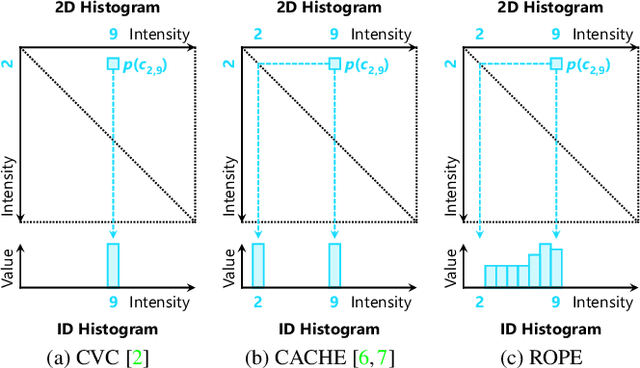
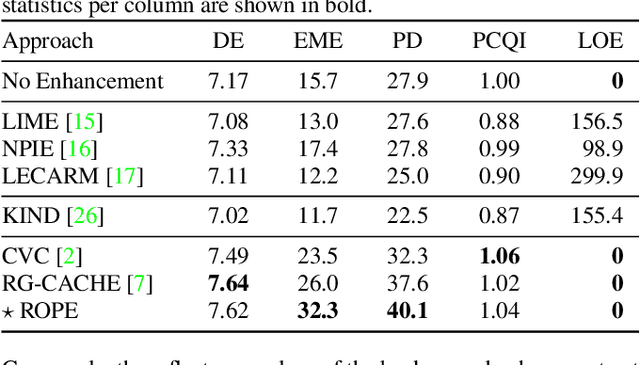
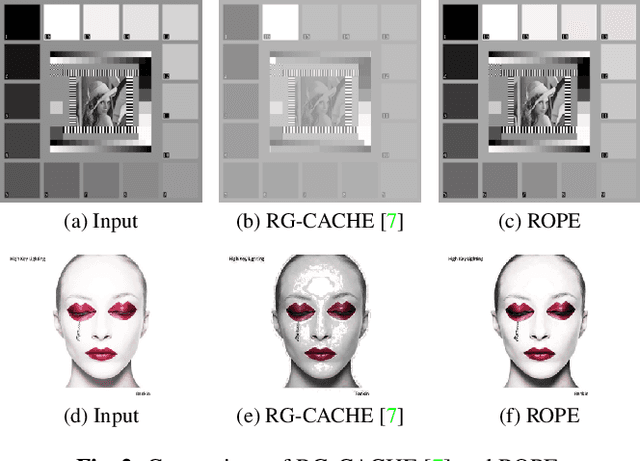
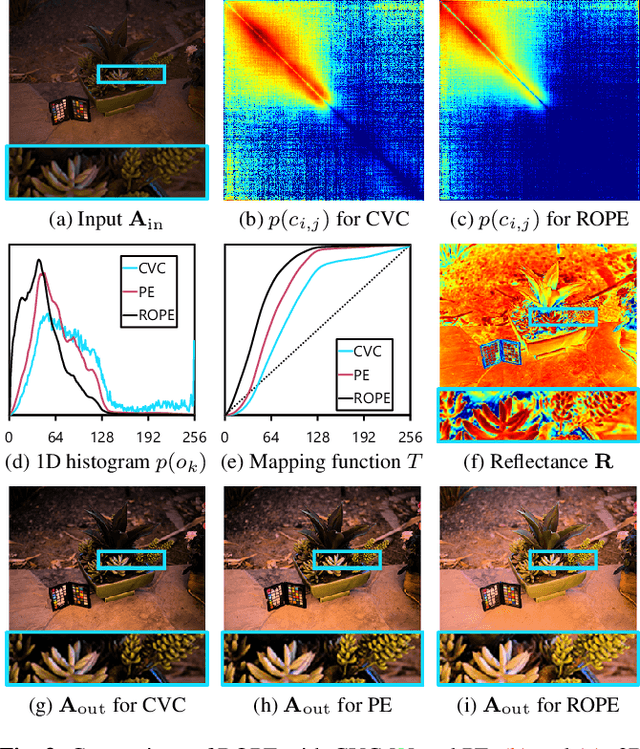
Despite recent advances in image enhancement, it remains difficult for existing approaches to adaptively improve the brightness and contrast for both low-light and normal-light images. To solve this problem, we propose a novel 2D histogram equalization approach. It assumes intensity occurrence and co-occurrence to be dependent on each other and derives the distribution of intensity occurrence (1D histogram) by marginalizing over the distribution of intensity co-occurrence (2D histogram). This scheme improves global contrast more effectively and reduces noise amplification. The 2D histogram is defined by incorporating the local pixel value differences in image reflectance into the density estimation to alleviate the adverse effects of dark lighting conditions. Over 500 images were used for evaluation, demonstrating the superiority of our approach over existing studies. It can sufficiently improve the brightness of low-light images while avoiding over-enhancement in normal-light images.
Reflectance-Guided, Contrast-Accumulated Histogram Equalization
Sep 14, 2022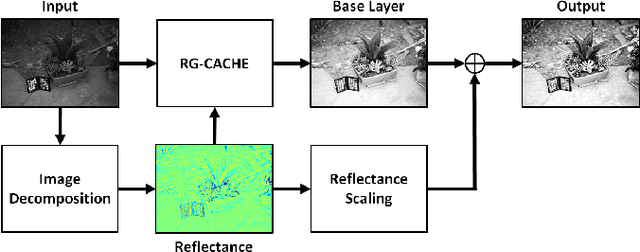
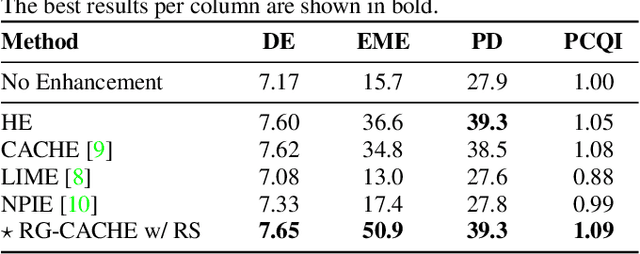


Existing image enhancement methods fall short of expectations because with them it is difficult to improve global and local image contrast simultaneously. To address this problem, we propose a histogram equalization-based method that adapts to the data-dependent requirements of brightness enhancement and improves the visibility of details without losing the global contrast. This method incorporates the spatial information provided by image context in density estimation for discriminative histogram equalization. To minimize the adverse effect of non-uniform illumination, we propose defining spatial information on the basis of image reflectance estimated with edge preserving smoothing. Our method works particularly well for determining how the background brightness should be adaptively adjusted and for revealing useful image details hidden in the dark.
ConceptBeam: Concept Driven Target Speech Extraction
Jul 25, 2022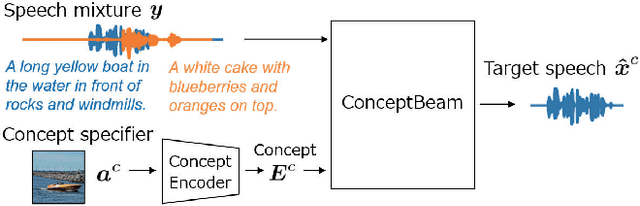

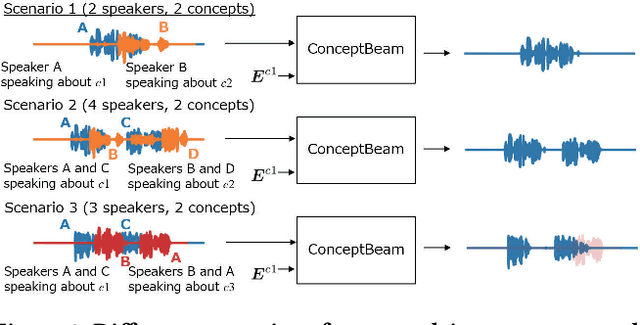

We propose a novel framework for target speech extraction based on semantic information, called ConceptBeam. Target speech extraction means extracting the speech of a target speaker in a mixture. Typical approaches have been exploiting properties of audio signals, such as harmonic structure and direction of arrival. In contrast, ConceptBeam tackles the problem with semantic clues. Specifically, we extract the speech of speakers speaking about a concept, i.e., a topic of interest, using a concept specifier such as an image or speech. Solving this novel problem would open the door to innovative applications such as listening systems that focus on a particular topic discussed in a conversation. Unlike keywords, concepts are abstract notions, making it challenging to directly represent a target concept. In our scheme, a concept is encoded as a semantic embedding by mapping the concept specifier to a shared embedding space. This modality-independent space can be built by means of deep metric learning using paired data consisting of images and their spoken captions. We use it to bridge modality-dependent information, i.e., the speech segments in the mixture, and the specified, modality-independent concept. As a proof of our scheme, we performed experiments using a set of images associated with spoken captions. That is, we generated speech mixtures from these spoken captions and used the images or speech signals as the concept specifiers. We then extracted the target speech using the acoustic characteristics of the identified segments. We compare ConceptBeam with two methods: one based on keywords obtained from recognition systems and another based on sound source separation. We show that ConceptBeam clearly outperforms the baseline methods and effectively extracts speech based on the semantic representation.
Introducing Auxiliary Text Query-modifier to Content-based Audio Retrieval
Jul 20, 2022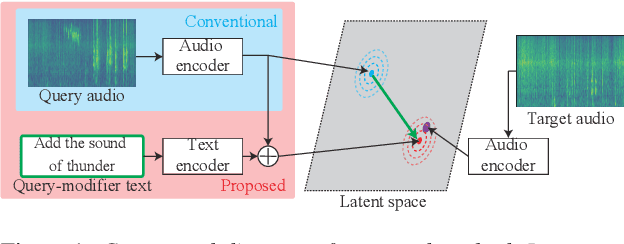

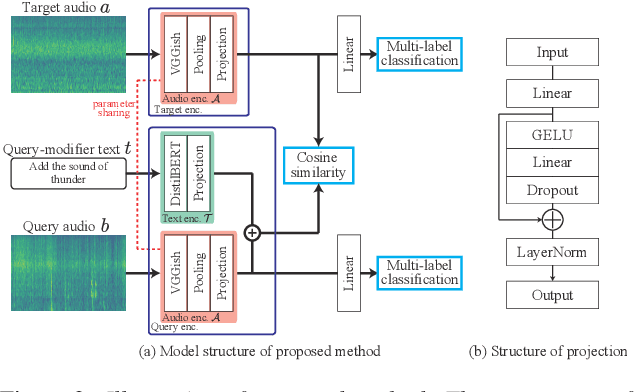

The amount of audio data available on public websites is growing rapidly, and an efficient mechanism for accessing the desired data is necessary. We propose a content-based audio retrieval method that can retrieve a target audio that is similar to but slightly different from the query audio by introducing auxiliary textual information which describes the difference between the query and target audio. While the range of conventional content-based audio retrieval is limited to audio that is similar to the query audio, the proposed method can adjust the retrieval range by adding an embedding of the auxiliary text query-modifier to the embedding of the query sample audio in a shared latent space. To evaluate our method, we built a dataset comprising two different audio clips and the text that describes the difference. The experimental results show that the proposed method retrieves the paired audio more accurately than the baseline. We also confirmed based on visualization that the proposed method obtains the shared latent space in which the audio difference and the corresponding text are represented as similar embedding vectors.