 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Improving Contextual Spelling Correction by External Acoustics Attention and Semantic Aware Data Augmentation
Feb 22, 2023
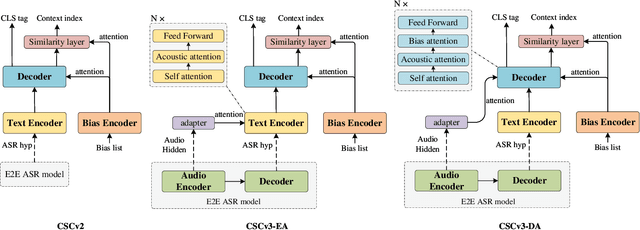
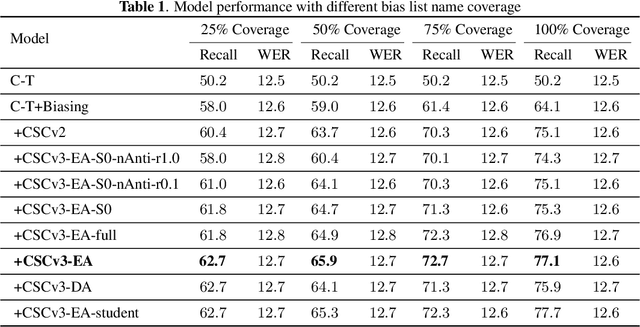

We previously proposed contextual spelling correction (CSC) to correct the output of end-to-end (E2E) automatic speech recognition (ASR) models with contextual information such as name, place, etc. Although CSC has achieved reasonable improvement in the biasing problem, there are still two drawbacks for further accuracy improvement. First, due to information limitation in text only hypothesis or weak performance of ASR model on rare domains, the CSC model may fail to correct phrases with similar pronunciation or anti-context cases where all biasing phrases are not present in the utterance. Second, there is a discrepancy between the training and inference of CSC. The bias list in training is randomly selected but in inference there may be more similarity between ground truth phrase and other phrases. To solve above limitations, in this paper we propose an improved non-autoregressive (NAR) spelling correction model for contextual biasing in E2E neural transducer-based ASR systems to improve the previous CSC model from two perspectives: Firstly, we incorporate acoustics information with an external attention as well as text hypotheses into CSC to better distinguish target phrase from dissimilar or irrelevant phrases. Secondly, we design a semantic aware data augmentation schema in training phrase to reduce the mismatch between training and inference to further boost the biasing accuracy. Experiments show that the improved method outperforms the baseline ASR+Biasing system by as much as 20.3% relative name recall gain and achieves stable improvement compared to the previous CSC method over different bias list name coverage ratio.
4-bit Quantization of LSTM-based Speech Recognition Models
Aug 27, 2021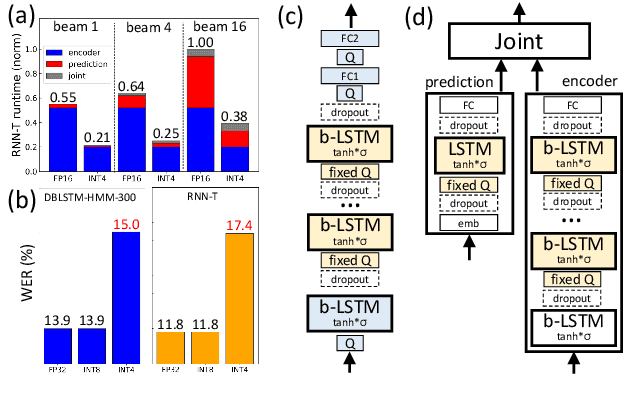
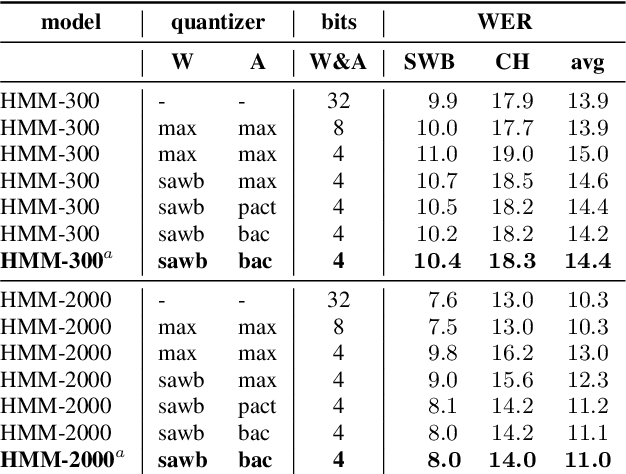
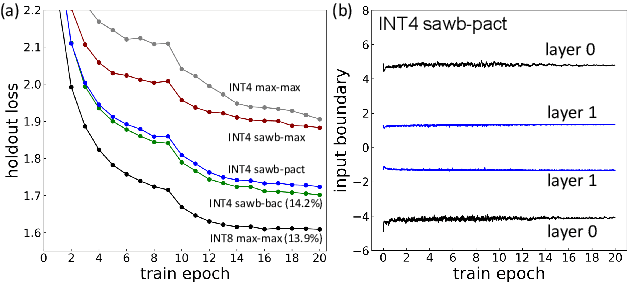
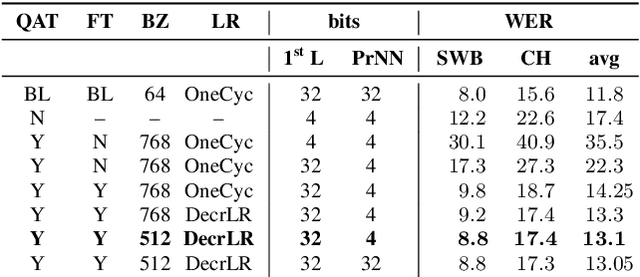
We investigate the impact of aggressive low-precision representations of weights and activations in two families of large LSTM-based architectures for Automatic Speech Recognition (ASR): hybrid Deep Bidirectional LSTM - Hidden Markov Models (DBLSTM-HMMs) and Recurrent Neural Network - Transducers (RNN-Ts). Using a 4-bit integer representation, a na\"ive quantization approach applied to the LSTM portion of these models results in significant Word Error Rate (WER) degradation. On the other hand, we show that minimal accuracy loss is achievable with an appropriate choice of quantizers and initializations. In particular, we customize quantization schemes depending on the local properties of the network, improving recognition performance while limiting computational time. We demonstrate our solution on the Switchboard (SWB) and CallHome (CH) test sets of the NIST Hub5-2000 evaluation. DBLSTM-HMMs trained with 300 or 2000 hours of SWB data achieves $<$0.5% and $<$1% average WER degradation, respectively. On the more challenging RNN-T models, our quantization strategy limits degradation in 4-bit inference to 1.3%.
SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network
Apr 27, 2021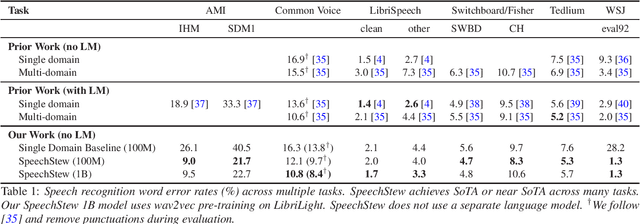
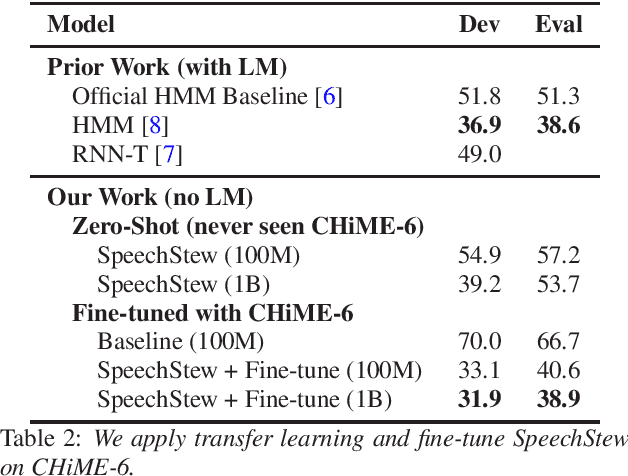
We present SpeechStew, a speech recognition model that is trained on a combination of various publicly available speech recognition datasets: AMI, Broadcast News, Common Voice, LibriSpeech, Switchboard/Fisher, Tedlium, and Wall Street Journal. SpeechStew simply mixes all of these datasets together, without any special re-weighting or re-balancing of the datasets. SpeechStew achieves SoTA or near SoTA results across a variety of tasks, without the use of an external language model. Our results include 9.0\% WER on AMI-IHM, 4.7\% WER on Switchboard, 8.3\% WER on CallHome, and 1.3\% on WSJ, which significantly outperforms prior work with strong external language models. We also demonstrate that SpeechStew learns powerful transfer learning representations. We fine-tune SpeechStew on a noisy low resource speech dataset, CHiME-6. We achieve 38.9\% WER without a language model, which compares to 38.6\% WER to a strong HMM baseline with a language model.
Accented Speech Recognition Inspired by Human Perception
Apr 09, 2021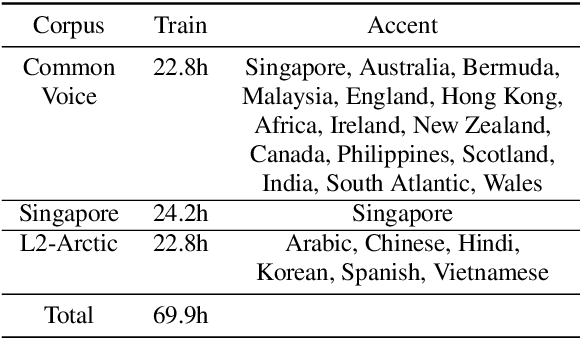
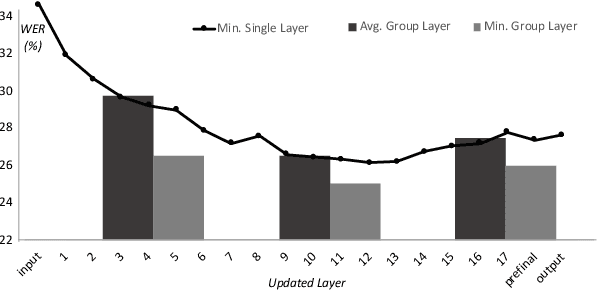
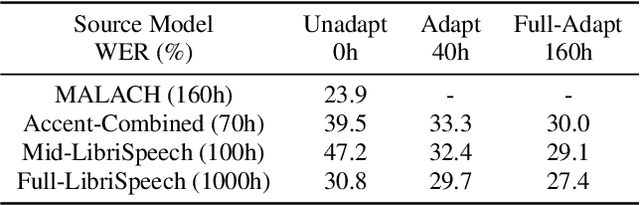
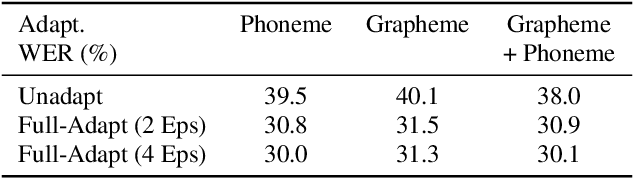
While improvements have been made in automatic speech recognition performance over the last several years, machines continue to have significantly lower performance on accented speech than humans. In addition, the most significant improvements on accented speech primarily arise by overwhelming the problem with hundreds or even thousands of hours of data. Humans typically require much less data to adapt to a new accent. This paper explores methods that are inspired by human perception to evaluate possible performance improvements for recognition of accented speech, with a specific focus on recognizing speech with a novel accent relative to that of the training data. Our experiments are run on small, accessible datasets that are available to the research community. We explore four methodologies: pre-exposure to multiple accents, grapheme and phoneme-based pronunciations, dropout (to improve generalization to a novel accent), and the identification of the layers in the neural network that can specifically be associated with accent modeling. Our results indicate that methods based on human perception are promising in reducing WER and understanding how accented speech is modeled in neural networks for novel accents.
Improving End-to-End Contextual Speech Recognition with Fine-grained Contextual Knowledge Selection
Jan 30, 2022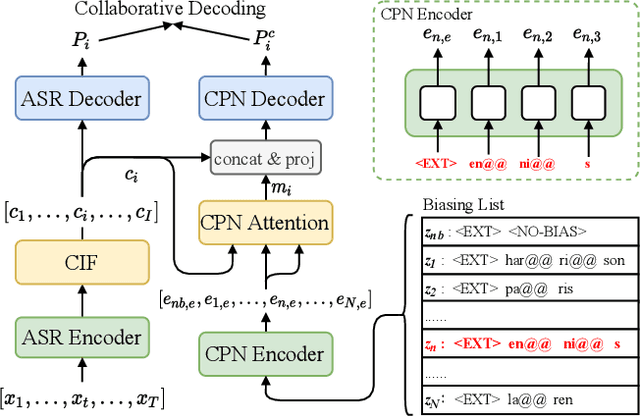
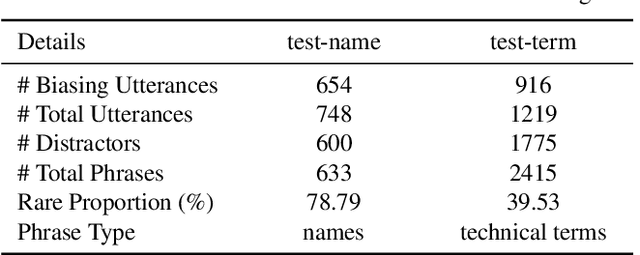
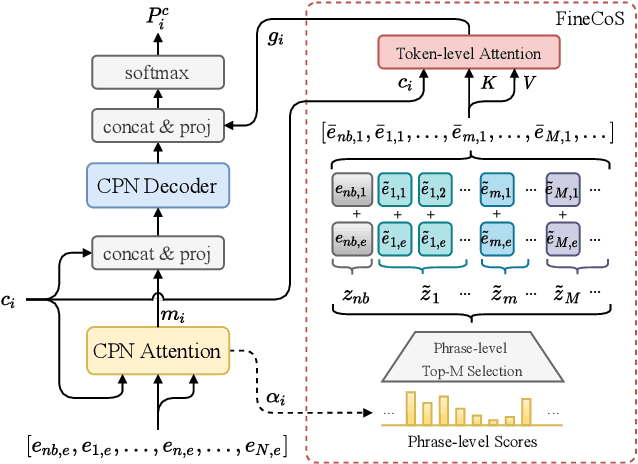
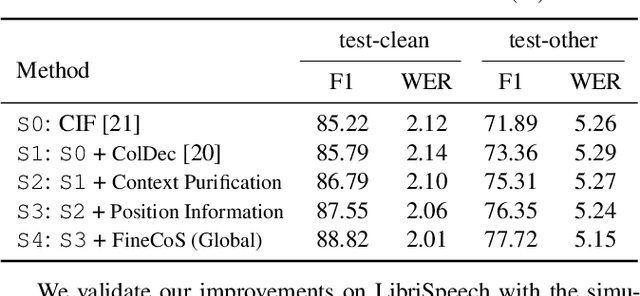
Nowadays, most methods in end-to-end contextual speech recognition bias the recognition process towards contextual knowledge. Since all-neural contextual biasing methods rely on phrase-level contextual modeling and attention-based relevance modeling, they may encounter confusion between similar context-specific phrases, which hurts predictions at the token level. In this work, we focus on mitigating confusion problems with fine-grained contextual knowledge selection (FineCoS). In FineCoS, we introduce fine-grained knowledge to reduce the uncertainty of token predictions. Specifically, we first apply phrase selection to narrow the range of phrase candidates, and then conduct token attention on the tokens in the selected phrase candidates. Moreover, we re-normalize the attention weights of most relevant phrases in inference to obtain more focused phrase-level contextual representations, and inject position information to better discriminate phrases or tokens. On LibriSpeech and an in-house 160,000-hour dataset, we explore the proposed methods based on a controllable all-neural biasing method, collaborative decoding (ColDec). The proposed methods provide at most 6.1% relative word error rate reduction on LibriSpeech and 16.4% relative character error rate reduction on the in-house dataset over ColDec.
Consistent Training and Decoding For End-to-end Speech Recognition Using Lattice-free MMI
Dec 30, 2021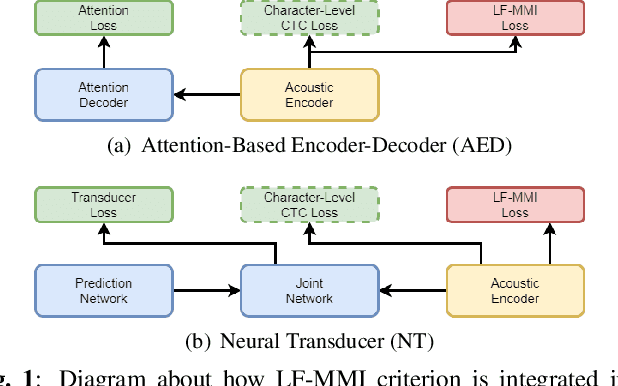
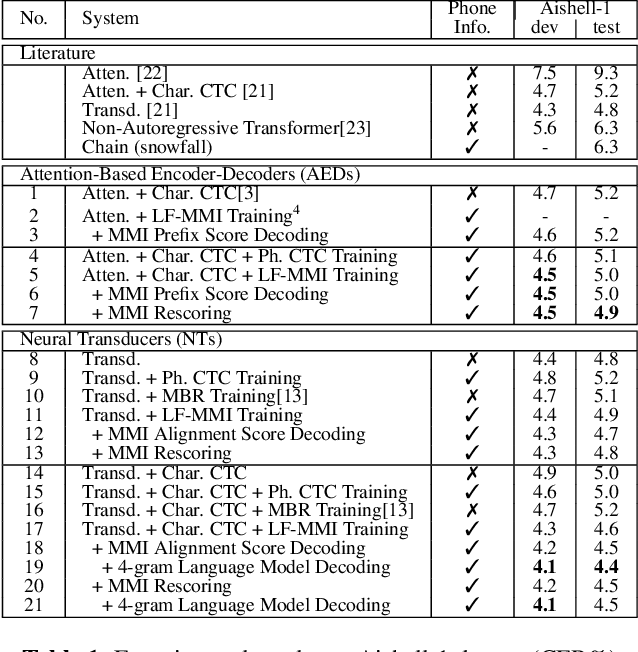
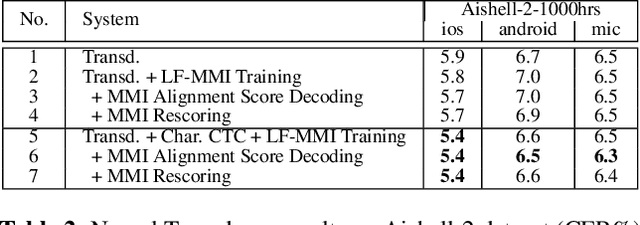
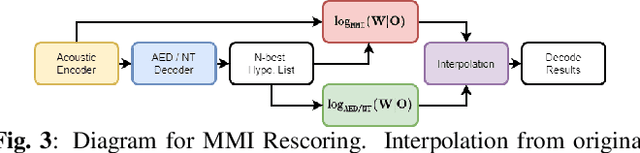
Recently, End-to-End (E2E) frameworks have achieved remarkable results on various Automatic Speech Recognition (ASR) tasks. However, Lattice-Free Maximum Mutual Information (LF-MMI), as one of the discriminative training criteria that show superior performance in hybrid ASR systems, is rarely adopted in E2E ASR frameworks. In this work, we propose a novel approach to integrate LF-MMI criterion into E2E ASR frameworks in both training and decoding stages. The proposed approach shows its effectiveness on two of the most widely used E2E frameworks including Attention-Based Encoder-Decoders (AEDs) and Neural Transducers (NTs). Experiments suggest that the introduction of the LF-MMI criterion consistently leads to significant performance improvements on various datasets and different E2E ASR frameworks. The best of our models achieves competitive CER of 4.1\% / 4.4\% on Aishell-1 dev/test set; we also achieve significant error reduction on Aishell-2 and Librispeech datasets over strong baselines.
Scaling Up Deliberation for Multilingual ASR
Oct 11, 2022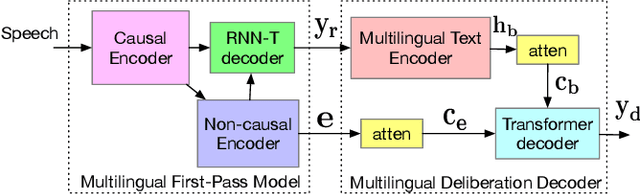
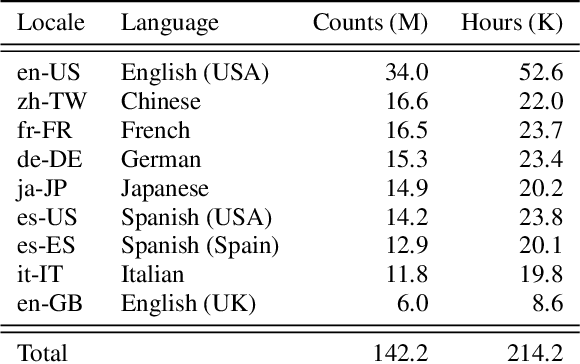
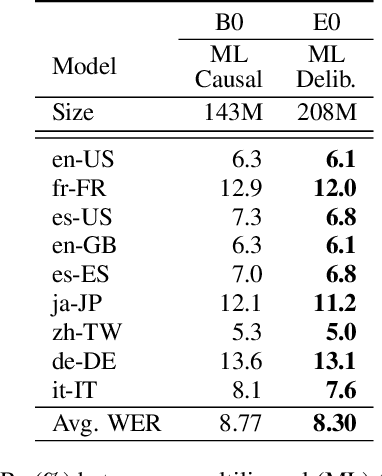
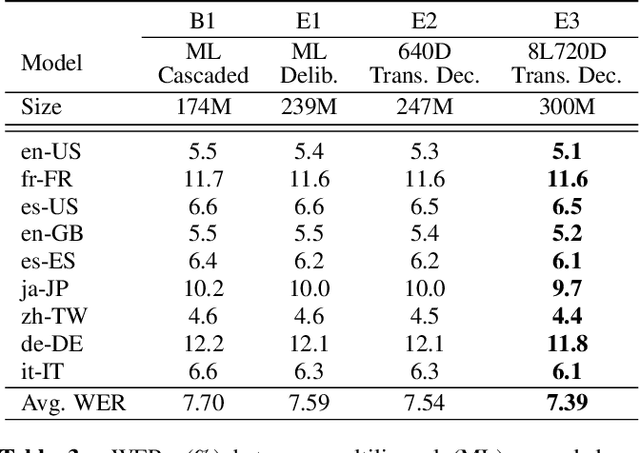
Multilingual end-to-end automatic speech recognition models are attractive due to its simplicity in training and deployment. Recent work on large-scale training of such models has shown promising results compared to monolingual models. However, the work often focuses on multilingual models themselves in a single-pass setup. In this work, we investigate second-pass deliberation for multilingual speech recognition. Our proposed deliberation is multilingual, i.e., the text encoder encodes hypothesis text from multiple languages, and the decoder attends to multilingual text and audio. We investigate scaling the deliberation text encoder and decoder, and compare scaling the deliberation decoder and the first-pass cascaded encoder. We show that deliberation improves the average WER on 9 languages by 4% relative compared to the single-pass model. By increasing the size of the deliberation up to 1B parameters, the average WER improvement increases to 9%, with up to 14% for certain languages. Our deliberation rescorer is based on transformer layers and can be parallelized during rescoring.
AequeVox: Automated Fairness Testing of Speech Recognition Systems
Oct 19, 2021
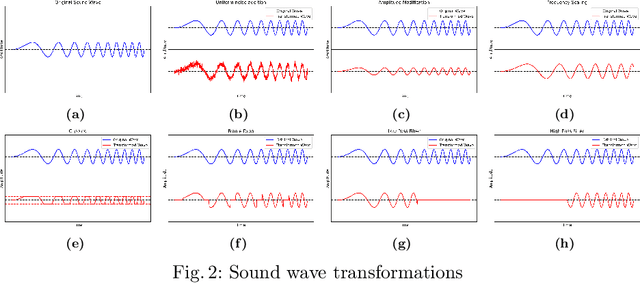
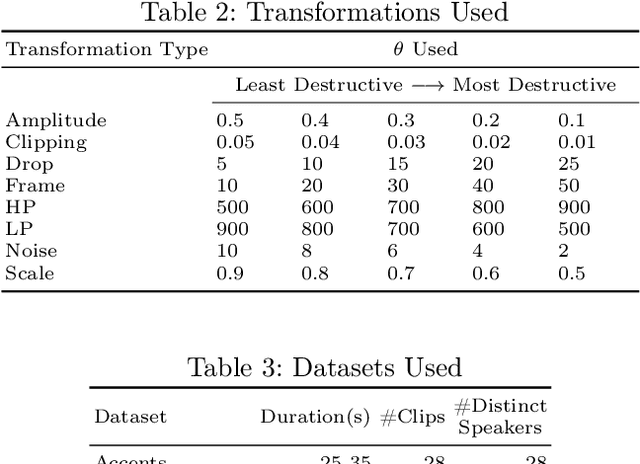
Automatic Speech Recognition (ASR) systems have become ubiquitous. They can be found in a variety of form factors and are increasingly important in our daily lives. As such, ensuring that these systems are equitable to different subgroups of the population is crucial. In this paper, we introduce, AequeVox, an automated testing framework for evaluating the fairness of ASR systems. AequeVox simulates different environments to assess the effectiveness of ASR systems for different populations. In addition, we investigate whether the chosen simulations are comprehensible to humans. We further propose a fault localization technique capable of identifying words that are not robust to these varying environments. Both components of AequeVox are able to operate in the absence of ground truth data. We evaluated AequeVox on speech from four different datasets using three different commercial ASRs. Our experiments reveal that non-native English, female and Nigerian English speakers generate 109%, 528.5% and 156.9% more errors, on average than native English, male and UK Midlands speakers, respectively. Our user study also reveals that 82.9% of the simulations (employed through speech transformations) had a comprehensibility rating above seven (out of ten), with the lowest rating being 6.78. This further validates the fairness violations discovered by AequeVox. Finally, we show that the non-robust words, as predicted by the fault localization technique embodied in AequeVox, show 223.8% more errors than the predicted robust words across all ASRs.
Continual learning using lattice-free MMI for speech recognition
Oct 13, 2021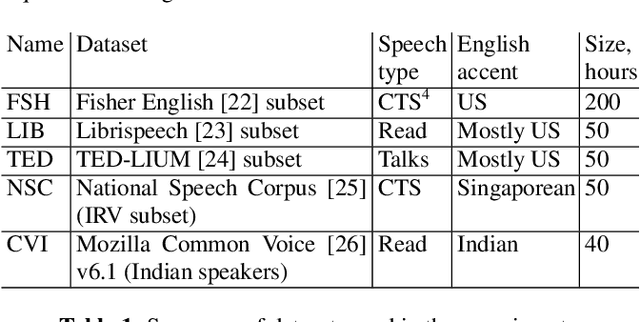
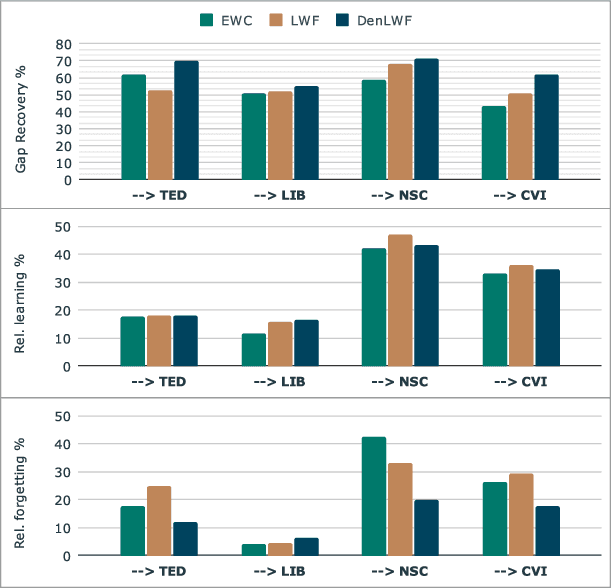

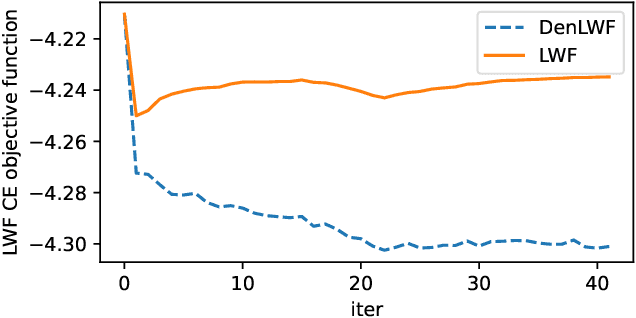
Continual learning (CL), or domain expansion, recently became a popular topic for automatic speech recognition (ASR) acoustic modeling because practical systems have to be updated frequently in order to work robustly on types of speech not observed during initial training. While sequential adaptation allows tuning a system to a new domain, it may result in performance degradation on the old domains due to catastrophic forgetting. In this work we explore regularization-based CL for neural network acoustic models trained with the lattice-free maximum mutual information (LF-MMI) criterion. We simulate domain expansion by incrementally adapting the acoustic model on different public datasets that include several accents and speaking styles. We investigate two well-known CL techniques, elastic weight consolidation (EWC) and learning without forgetting (LWF), which aim to reduce forgetting by preserving model weights or network outputs. We additionally introduce a sequence-level LWF regularization, which exploits posteriors from the denominator graph of LF-MMI to further reduce forgetting. Empirical results show that the proposed sequence-level LWF can improve the best average word error rate across all domains by up to 9.4% relative compared with using regular LWF.
Regeneration Learning: A Learning Paradigm for Data Generation
Jan 21, 2023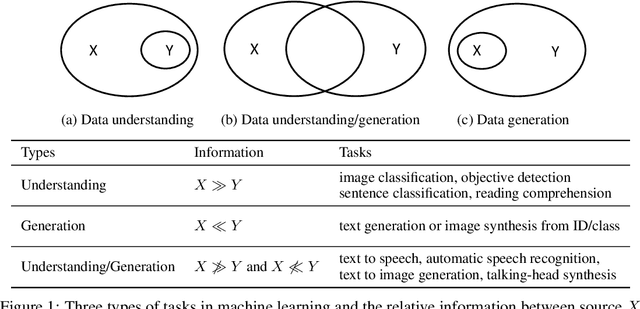
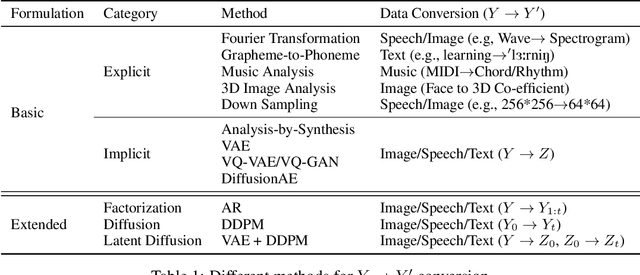


Machine learning methods for conditional data generation usually build a mapping from source conditional data X to target data Y. The target Y (e.g., text, speech, music, image, video) is usually high-dimensional and complex, and contains information that does not exist in source data, which hinders effective and efficient learning on the source-target mapping. In this paper, we present a learning paradigm called regeneration learning for data generation, which first generates Y' (an abstraction/representation of Y) from X and then generates Y from Y'. During training, Y' is obtained from Y through either handcrafted rules or self-supervised learning and is used to learn X-->Y' and Y'-->Y. Regeneration learning extends the concept of representation learning to data generation tasks, and can be regarded as a counterpart of traditional representation learning, since 1) regeneration learning handles the abstraction (Y') of the target data Y for data generation while traditional representation learning handles the abstraction (X') of source data X for data understanding; 2) both the processes of Y'-->Y in regeneration learning and X-->X' in representation learning can be learned in a self-supervised way (e.g., pre-training); 3) both the mappings from X to Y' in regeneration learning and from X' to Y in representation learning are simpler than the direct mapping from X to Y. We show that regeneration learning can be a widely-used paradigm for data generation (e.g., text generation, speech recognition, speech synthesis, music composition, image generation, and video generation) and can provide valuable insights into developing data generation methods.