 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Natural and Expressive Robot Gestures through Iterative Reinforcement Learning with Human Feedback using LLMs
Jun 17, 2026Expressive gestures are essential for natural and effective communication, complementing speech when verbal cues alone are insufficient (e.g., pointing). For social robots such as the humanoid Pepper, producing natural and expressive movements is critical for improving human-robot interaction (HRI) and long-term acceptance. However, generating gestures remains challenging due to reliance on expert-authored animations, resulting in rigid behaviors that are impractical for dynamic and diverse environments. Alternatively, machine learning approaches often struggle to capture perceived naturalness, becoming increasingly challenging with more degrees of freedom. Consequently, producing expressive robot gestures requires a system that can adapt to the environment while adhering to social norms and physical constraints. Recent advances in large language models (LLMs) enable dynamic code generation, offering new opportunities for runtime gesture synthesis from natural language. In this paper, we integrate ChatGPT into the humanoid robot Pepper to generate co-speech gestures aligned with conversational output. While this baseline enables flexible gesture generation, the resulting motions are often perceived as stiff and unnatural. To address this limitation, we introduce an iterative reinforcement learning with human feedback (RLHF) system that finetunes gesture generation based on user evaluations, leveraging an iterative user study to compare Pepper's generated gestures. Our results show that RLHF improved the LLM's co-speech generative capabilities, producing more expressive, relevant and fluid movements.
Sequential Hiring of Contingent Workers Through Learning-Based Optimization
Jun 16, 2026In this paper, we study a sequential workforce management problem in a contingent labor setting with uncertainty in both worker production and labor supply. A firm seeks to maximize cumulative profit by maintaining an active team of fixed size while learning worker productivity over time. We emphasize two critical operational frictions in this problem: replacing workers is costly, and workers may not be available immediately for hiring because of, for example, prior job commitments, scheduling constraints, or onboarding procedures. Thus, hiring decisions take effect only after a random delay. We formulate this problem as a stochastic multi-play bandit with costly switching and delayed actions, and develop a learning-based hiring policy, DR-UCB (DelayedReplacement-UCB), that makes replacement and hiring decisions sequentially through learning cycles. In each cycle, the policy uses real-time production data to determine when to initiate workforce changes and which workers to replace and hire. We show that the leading-order regret of the proposed policy matches its lower bound in its dependence on the time horizon. Our numerical experiments show that DR-UCB outperforms benchmark policies.
Spurious Rewards Paradox: Mechanistically Understanding How RLVR Activates Memorization Shortcuts in LLMs
Jan 16, 2026Reinforcement Learning with Verifiable Rewards (RLVR) is highly effective for enhancing LLM reasoning, yet recent evidence shows models like Qwen 2.5 achieve significant gains even with spurious or incorrect rewards. We investigate this phenomenon and identify a "Perplexity Paradox": spurious RLVR triggers a divergence where answer-token perplexity drops while prompt-side coherence degrades, suggesting the model is bypassing reasoning in favor of memorization. Using Path Patching, Logit Lens, JSD analysis, and Neural Differential Equations, we uncover a hidden Anchor-Adapter circuit that facilitates this shortcut. We localize a Functional Anchor in the middle layers (L18-20) that triggers the retrieval of memorized solutions, followed by Structural Adapters in later layers (L21+) that transform representations to accommodate the shortcut signal. Finally, we demonstrate that scaling specific MLP keys within this circuit allows for bidirectional causal steering-artificially amplifying or suppressing contamination-driven performance. Our results provide a mechanistic roadmap for identifying and mitigating data contamination in RLVR-tuned models. Code is available at https://github.com/idwts/How-RLVR-Activates-Memorization-Shortcuts.
Knowledge Distillation Neural Network for Predicting Car-following Behaviour of Human-driven and Autonomous Vehicles
Nov 08, 2024



As we move towards a mixed-traffic scenario of Autonomous vehicles (AVs) and Human-driven vehicles (HDVs), understanding the car-following behaviour is important to improve traffic efficiency and road safety. Using a real-world trajectory dataset, this study uses descriptive and statistical analysis to investigate the car-following behaviours of three vehicle pairs: HDV-AV, AV-HDV and HDV-HDV in mixed traffic. The ANOVA test showed that car-following behaviours across different vehicle pairs are statistically significant (p-value < 0.05). We also introduce a data-driven Knowledge Distillation Neural Network (KDNN) model for predicting car-following behaviour in terms of speed. The KDNN model demonstrates comparable predictive accuracy to its teacher network, a Long Short-Term Memory (LSTM) network, and outperforms both the standalone student network, a Multilayer Perceptron (MLP), and traditional physics-based models like the Gipps model. Notably, the KDNN model better prevents collisions, measured by minimum Time-to-Collision (TTC), and operates with lower computational power, making it ideal for AVs or driving simulators requiring efficient computing.
Fashion-VDM: Video Diffusion Model for Virtual Try-On
Nov 04, 2024



We present Fashion-VDM, a video diffusion model (VDM) for generating virtual try-on videos. Given an input garment image and person video, our method aims to generate a high-quality try-on video of the person wearing the given garment, while preserving the person's identity and motion. Image-based virtual try-on has shown impressive results; however, existing video virtual try-on (VVT) methods are still lacking garment details and temporal consistency. To address these issues, we propose a diffusion-based architecture for video virtual try-on, split classifier-free guidance for increased control over the conditioning inputs, and a progressive temporal training strategy for single-pass 64-frame, 512px video generation. We also demonstrate the effectiveness of joint image-video training for video try-on, especially when video data is limited. Our qualitative and quantitative experiments show that our approach sets the new state-of-the-art for video virtual try-on. For additional results, visit our project page: https://johannakarras.github.io/Fashion-VDM.
SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network
Apr 27, 2021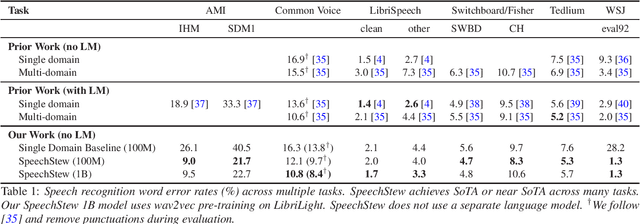
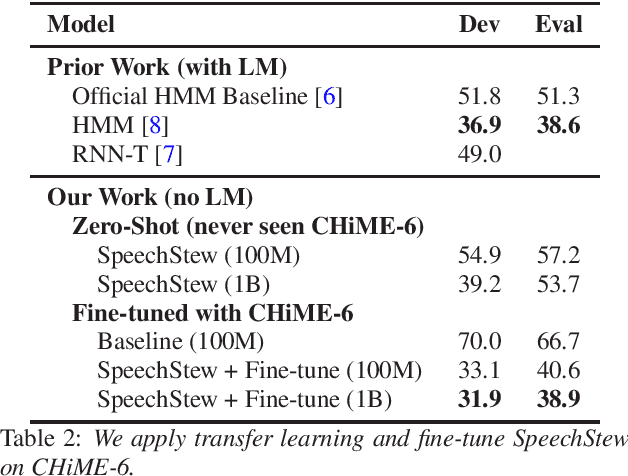
We present SpeechStew, a speech recognition model that is trained on a combination of various publicly available speech recognition datasets: AMI, Broadcast News, Common Voice, LibriSpeech, Switchboard/Fisher, Tedlium, and Wall Street Journal. SpeechStew simply mixes all of these datasets together, without any special re-weighting or re-balancing of the datasets. SpeechStew achieves SoTA or near SoTA results across a variety of tasks, without the use of an external language model. Our results include 9.0\% WER on AMI-IHM, 4.7\% WER on Switchboard, 8.3\% WER on CallHome, and 1.3\% on WSJ, which significantly outperforms prior work with strong external language models. We also demonstrate that SpeechStew learns powerful transfer learning representations. We fine-tune SpeechStew on a noisy low resource speech dataset, CHiME-6. We achieve 38.9\% WER without a language model, which compares to 38.6\% WER to a strong HMM baseline with a language model.