 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual learning using lattice-free MMI for speech recognition
Oct 13, 2021
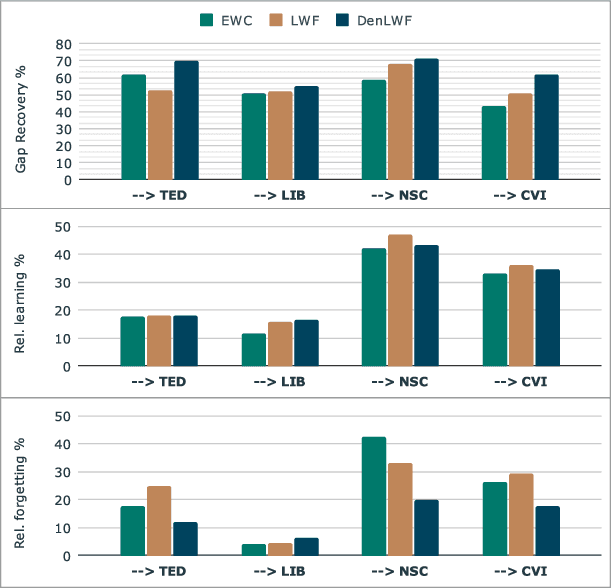

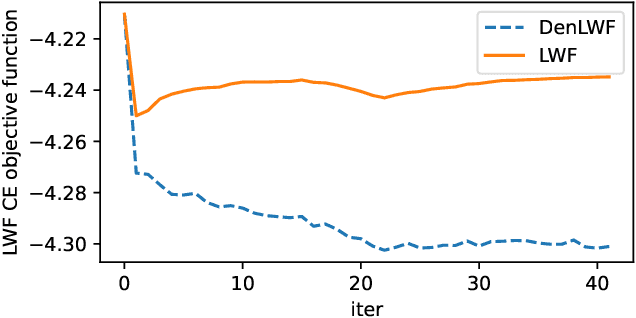
Continual learning (CL), or domain expansion, recently became a popular topic for automatic speech recognition (ASR) acoustic modeling because practical systems have to be updated frequently in order to work robustly on types of speech not observed during initial training. While sequential adaptation allows tuning a system to a new domain, it may result in performance degradation on the old domains due to catastrophic forgetting. In this work we explore regularization-based CL for neural network acoustic models trained with the lattice-free maximum mutual information (LF-MMI) criterion. We simulate domain expansion by incrementally adapting the acoustic model on different public datasets that include several accents and speaking styles. We investigate two well-known CL techniques, elastic weight consolidation (EWC) and learning without forgetting (LWF), which aim to reduce forgetting by preserving model weights or network outputs. We additionally introduce a sequence-level LWF regularization, which exploits posteriors from the denominator graph of LF-MMI to further reduce forgetting. Empirical results show that the proposed sequence-level LWF can improve the best average word error rate across all domains by up to 9.4% relative compared with using regular LWF.
"This is Houston. Say again, please". The Behavox system for the Apollo-11 Fearless Steps Challenge
Aug 04, 2020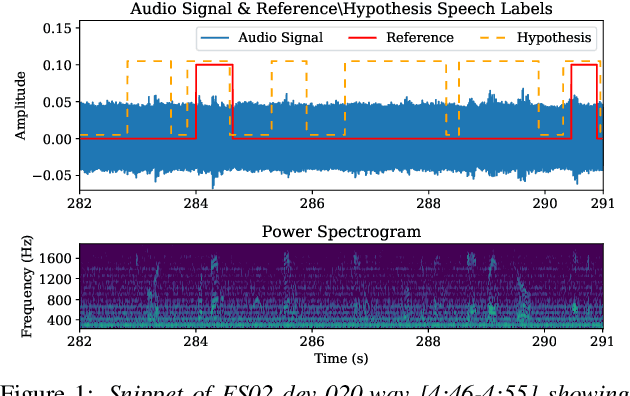
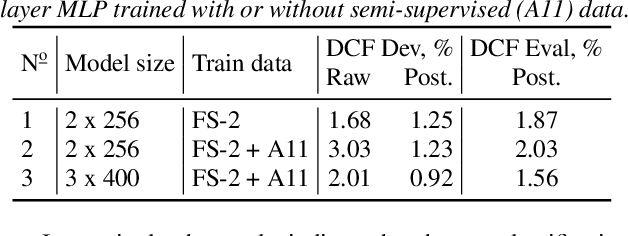
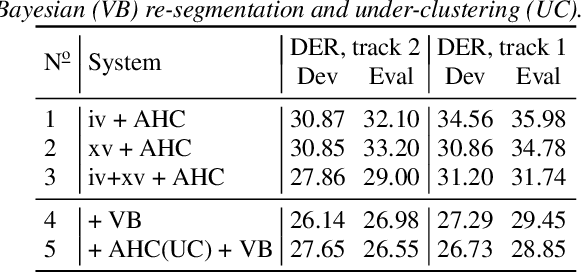
We describe the speech activity detection (SAD), speaker diarization (SD), and automatic speech recognition (ASR) experiments conducted by the Behavox team for the Interspeech 2020 Fearless Steps Challenge (FSC-2). A relatively small amount of labeled data, a large variety of speakers and channel distortions, specific lexicon and speaking style resulted in high error rates on the systems which involved this data. In addition to approximately 36 hours of annotated NASA mission recordings, the organizers provided a much larger but unlabeled 19k hour Apollo-11 corpus that we also explore for semi-supervised training of ASR acoustic and language models, observing more than 17% relative word error rate improvement compared to training on the FSC-2 data only. We also compare several SAD and SD systems to approach the most difficult tracks of the challenge (track 1 for diarization and ASR), where long 30-minute audio recordings are provided for evaluation without segmentation or speaker information. For all systems, we report substantial performance improvements compared to the FSC-2 baseline systems, and achieved a first-place ranking for SD and ASR and fourth-place for SAD in the challenge.