 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Finer Better? The Limits of Microscaling Formats in Large Language Models
Jan 26, 2026Microscaling data formats leverage per-block tensor quantization to enable aggressive model compression with limited loss in accuracy. Unlocking their potential for efficient training and inference necessitates hardware-friendly implementations that handle matrix multiplications in a native format and adopt efficient error-mitigation strategies. Herein, we report the emergence of a surprising behavior associated with microscaling quantization, whereas the output of a quantized model degrades as block size is decreased below a given threshold. This behavior clashes with the expectation that a smaller block size should allow for a better representation of the tensor elements. We investigate this phenomenon both experimentally and theoretically, decoupling the sources of quantization error behind it. Experimentally, we analyze the distributions of several Large Language Models and identify the conditions driving the anomalous behavior. Theoretically, we lay down a framework showing remarkable agreement with experimental data from pretrained model distributions and ideal ones. Overall, we show that the anomaly is driven by the interplay between narrow tensor distributions and the limited dynamic range of the quantized scales. Based on these insights, we propose the use of FP8 unsigned E5M3 (UE5M3) as a novel hardware-friendly format for the scales in FP4 microscaling data types. We demonstrate that UE5M3 achieves comparable performance to the conventional FP8 unsigned E4M3 scales while obviating the need of global scaling operations on weights and activations.
Enhance DNN Adversarial Robustness and Efficiency via Injecting Noise to Non-Essential Neurons
Feb 06, 2024Deep Neural Networks (DNNs) have revolutionized a wide range of industries, from healthcare and finance to automotive, by offering unparalleled capabilities in data analysis and decision-making. Despite their transforming impact, DNNs face two critical challenges: the vulnerability to adversarial attacks and the increasing computational costs associated with more complex and larger models. In this paper, we introduce an effective method designed to simultaneously enhance adversarial robustness and execution efficiency. Unlike prior studies that enhance robustness via uniformly injecting noise, we introduce a non-uniform noise injection algorithm, strategically applied at each DNN layer to disrupt adversarial perturbations introduced in attacks. By employing approximation techniques, our approach identifies and protects essential neurons while strategically introducing noise into non-essential neurons. Our experimental results demonstrate that our method successfully enhances both robustness and efficiency across several attack scenarios, model architectures, and datasets.
Approximate Computing and the Efficient Machine Learning Expedition
Oct 02, 2022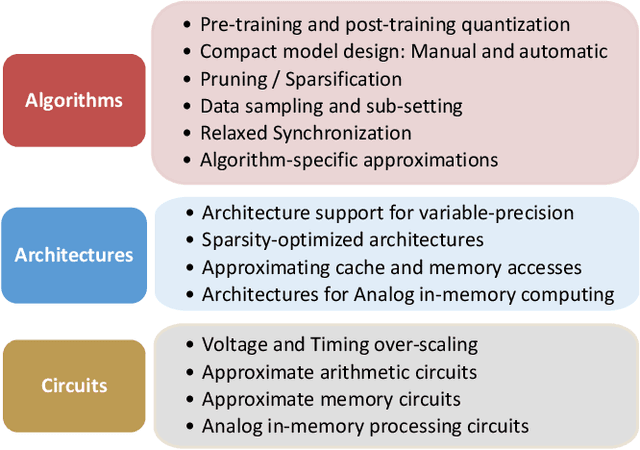
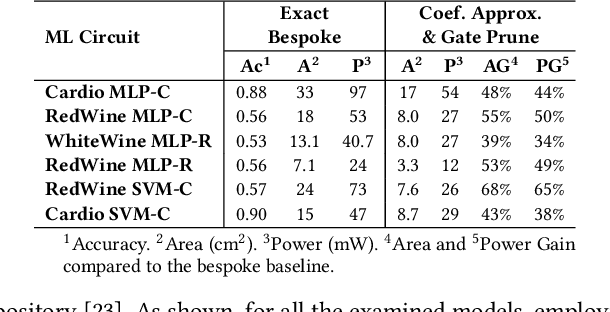
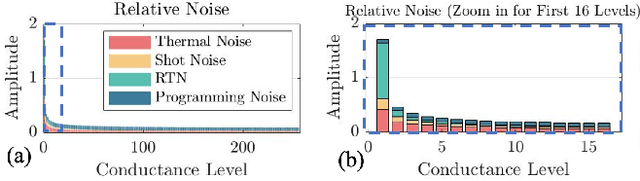
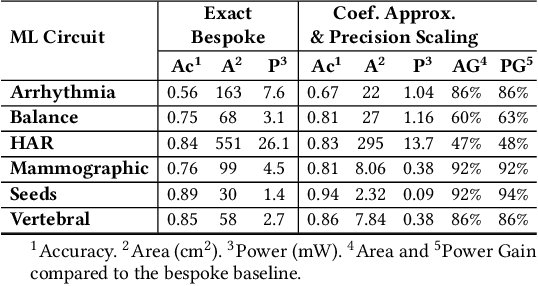
Approximate computing (AxC) has been long accepted as a design alternative for efficient system implementation at the cost of relaxed accuracy requirements. Despite the AxC research activities in various application domains, AxC thrived the past decade when it was applied in Machine Learning (ML). The by definition approximate notion of ML models but also the increased computational overheads associated with ML applications-that were effectively mitigated by corresponding approximations-led to a perfect matching and a fruitful synergy. AxC for AI/ML has transcended beyond academic prototypes. In this work, we enlighten the synergistic nature of AxC and ML and elucidate the impact of AxC in designing efficient ML systems. To that end, we present an overview and taxonomy of AxC for ML and use two descriptive application scenarios to demonstrate how AxC boosts the efficiency of ML systems.
Accelerating Inference and Language Model Fusion of Recurrent Neural Network Transducers via End-to-End 4-bit Quantization
Jun 16, 2022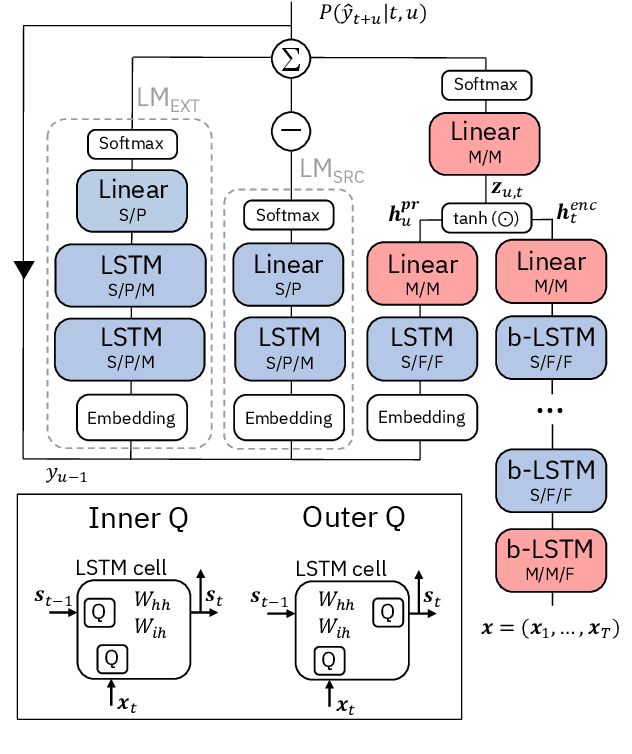
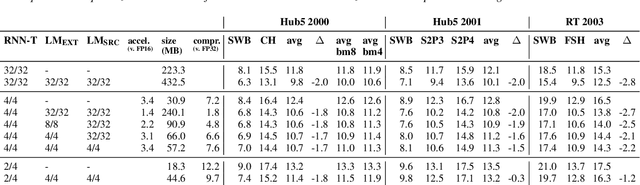
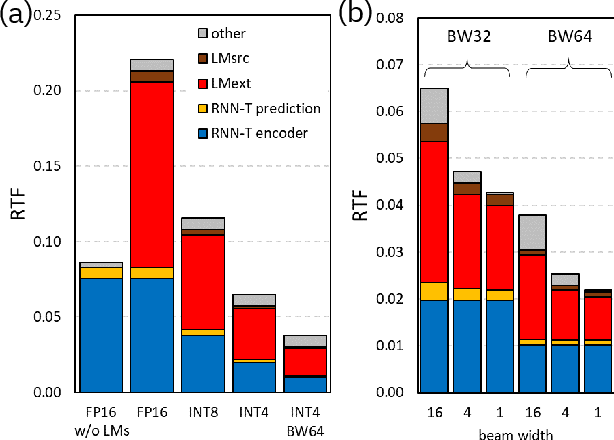
We report on aggressive quantization strategies that greatly accelerate inference of Recurrent Neural Network Transducers (RNN-T). We use a 4 bit integer representation for both weights and activations and apply Quantization Aware Training (QAT) to retrain the full model (acoustic encoder and language model) and achieve near-iso-accuracy. We show that customized quantization schemes that are tailored to the local properties of the network are essential to achieve good performance while limiting the computational overhead of QAT. Density ratio Language Model fusion has shown remarkable accuracy gains on RNN-T workloads but it severely increases the computational cost of inference. We show that our quantization strategies enable using large beam widths for hypothesis search while achieving streaming-compatible runtimes and a full model compression ratio of 7.6$\times$ compared to the full precision model. Via hardware simulations, we estimate a 3.4$\times$ acceleration from FP16 to INT4 for the end-to-end quantized RNN-T inclusive of LM fusion, resulting in a Real Time Factor (RTF) of 0.06. On the NIST Hub5 2000, Hub5 2001, and RT-03 test sets, we retain most of the gains associated with LM fusion, improving the average WER by $>$1.5%.
4-bit Quantization of LSTM-based Speech Recognition Models
Aug 27, 2021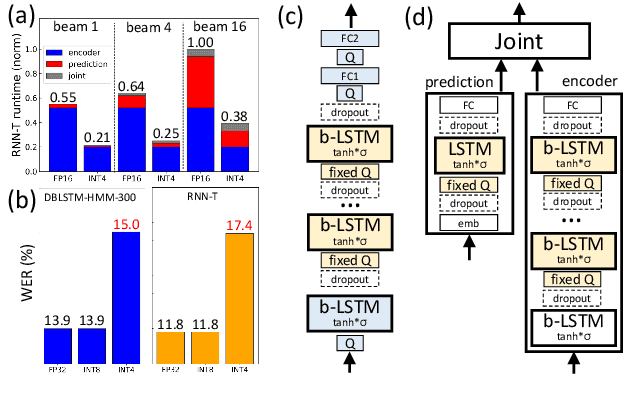
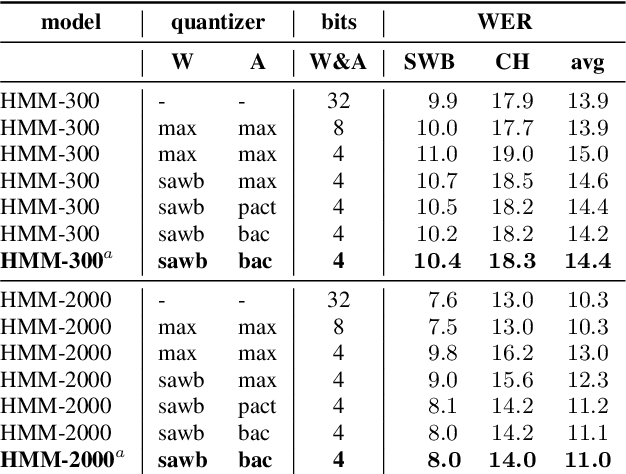
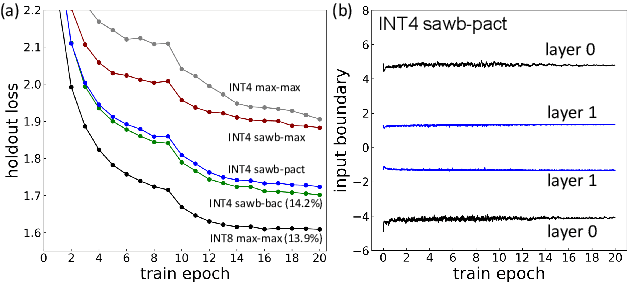
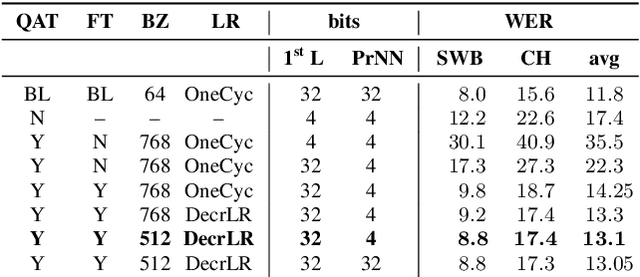
We investigate the impact of aggressive low-precision representations of weights and activations in two families of large LSTM-based architectures for Automatic Speech Recognition (ASR): hybrid Deep Bidirectional LSTM - Hidden Markov Models (DBLSTM-HMMs) and Recurrent Neural Network - Transducers (RNN-Ts). Using a 4-bit integer representation, a na\"ive quantization approach applied to the LSTM portion of these models results in significant Word Error Rate (WER) degradation. On the other hand, we show that minimal accuracy loss is achievable with an appropriate choice of quantizers and initializations. In particular, we customize quantization schemes depending on the local properties of the network, improving recognition performance while limiting computational time. We demonstrate our solution on the Switchboard (SWB) and CallHome (CH) test sets of the NIST Hub5-2000 evaluation. DBLSTM-HMMs trained with 300 or 2000 hours of SWB data achieves $<$0.5% and $<$1% average WER degradation, respectively. On the more challenging RNN-T models, our quantization strategy limits degradation in 4-bit inference to 1.3%.
ScaleCom: Scalable Sparsified Gradient Compression for Communication-Efficient Distributed Training
Apr 21, 2021
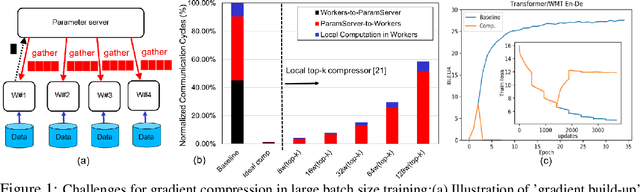
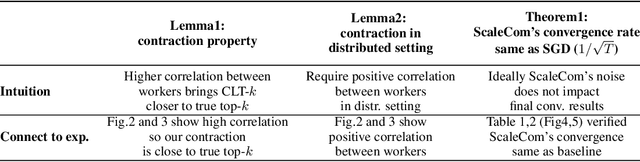
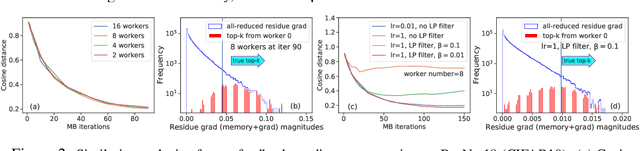
Large-scale distributed training of Deep Neural Networks (DNNs) on state-of-the-art platforms is expected to be severely communication constrained. To overcome this limitation, numerous gradient compression techniques have been proposed and have demonstrated high compression ratios. However, most existing methods do not scale well to large scale distributed systems (due to gradient build-up) and/or fail to evaluate model fidelity (test accuracy) on large datasets. To mitigate these issues, we propose a new compression technique, Scalable Sparsified Gradient Compression (ScaleCom), that leverages similarity in the gradient distribution amongst learners to provide significantly improved scalability. Using theoretical analysis, we show that ScaleCom provides favorable convergence guarantees and is compatible with gradient all-reduce techniques. Furthermore, we experimentally demonstrate that ScaleCom has small overheads, directly reduces gradient traffic and provides high compression rates (65-400X) and excellent scalability (up to 64 learners and 8-12X larger batch sizes over standard training) across a wide range of applications (image, language, and speech) without significant accuracy loss.
Bridging the Accuracy Gap for 2-bit Quantized Neural Networks
Jul 17, 2018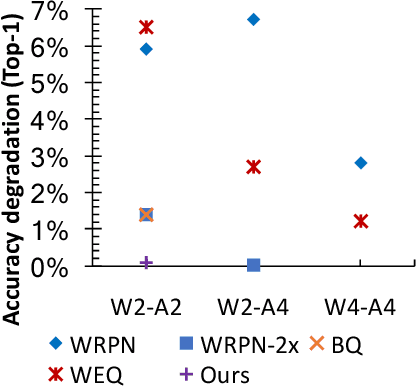
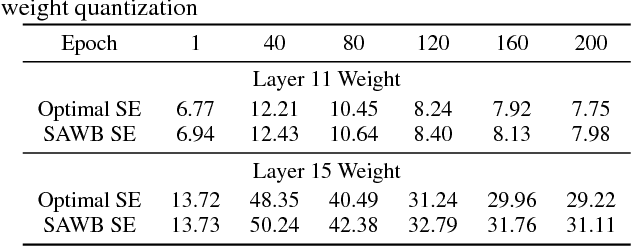
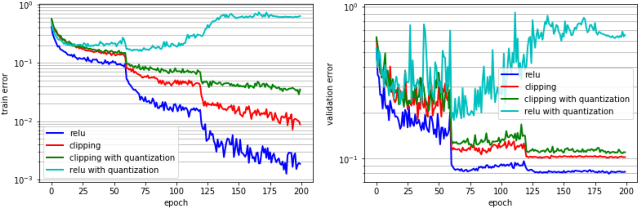
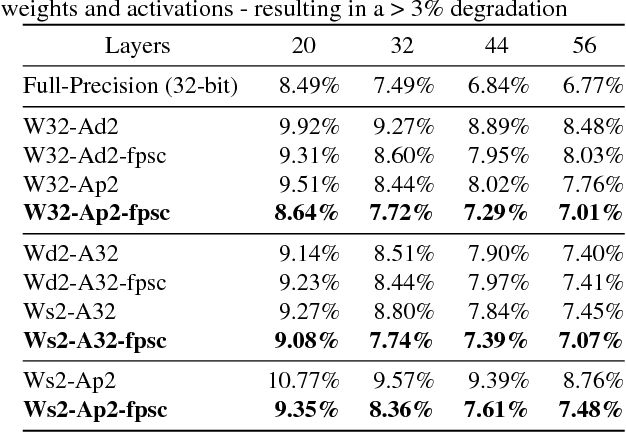
Deep learning algorithms achieve high classification accuracy at the expense of significant computation cost. In order to reduce this cost, several quantization schemes have gained attention recently with some focusing on weight quantization, and others focusing on quantizing activations. This paper proposes novel techniques that target weight and activation quantizations separately resulting in an overall quantized neural network (QNN). The activation quantization technique, PArameterized Clipping acTivation (PACT), uses an activation clipping parameter $\alpha$ that is optimized during training to find the right quantization scale. The weight quantization scheme, statistics-aware weight binning (SAWB), finds the optimal scaling factor that minimizes the quantization error based on the statistical characteristics of the distribution of weights without the need for an exhaustive search. The combination of PACT and SAWB results in a 2-bit QNN that achieves state-of-the-art classification accuracy (comparable to full precision networks) across a range of popular models and datasets.
PACT: Parameterized Clipping Activation for Quantized Neural Networks
Jul 17, 2018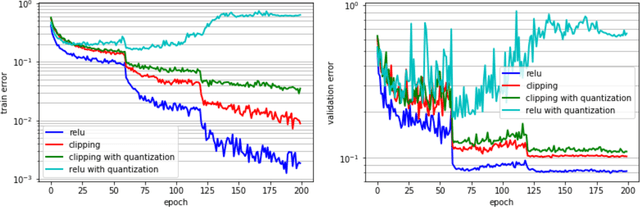
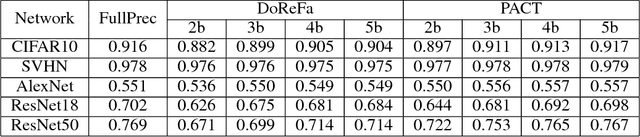
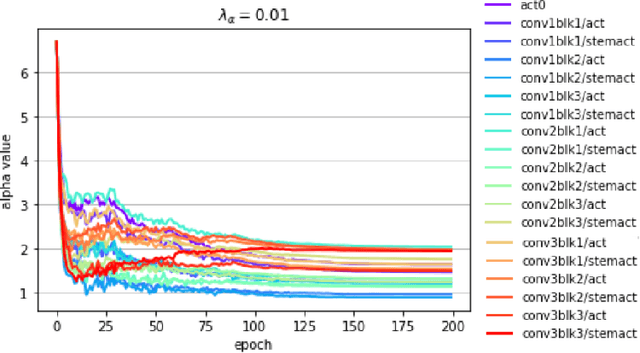

Deep learning algorithms achieve high classification accuracy at the expense of significant computation cost. To address this cost, a number of quantization schemes have been proposed - but most of these techniques focused on quantizing weights, which are relatively smaller in size compared to activations. This paper proposes a novel quantization scheme for activations during training - that enables neural networks to work well with ultra low precision weights and activations without any significant accuracy degradation. This technique, PArameterized Clipping acTivation (PACT), uses an activation clipping parameter $\alpha$ that is optimized during training to find the right quantization scale. PACT allows quantizing activations to arbitrary bit precisions, while achieving much better accuracy relative to published state-of-the-art quantization schemes. We show, for the first time, that both weights and activations can be quantized to 4-bits of precision while still achieving accuracy comparable to full precision networks across a range of popular models and datasets. We also show that exploiting these reduced-precision computational units in hardware can enable a super-linear improvement in inferencing performance due to a significant reduction in the area of accelerator compute engines coupled with the ability to retain the quantized model and activation data in on-chip memories.
SparCE: Sparsity aware General Purpose Core Extensions to Accelerate Deep Neural Networks
Nov 29, 2017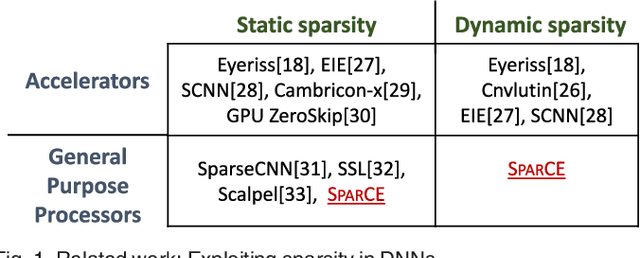
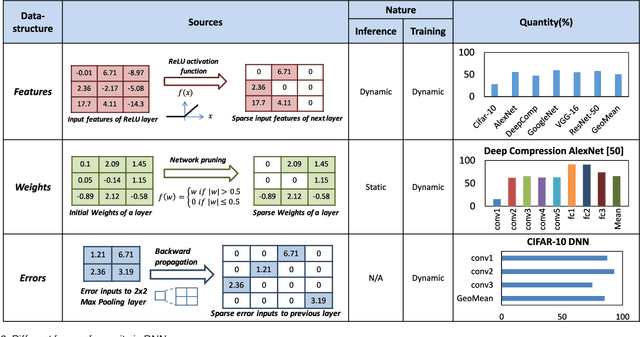

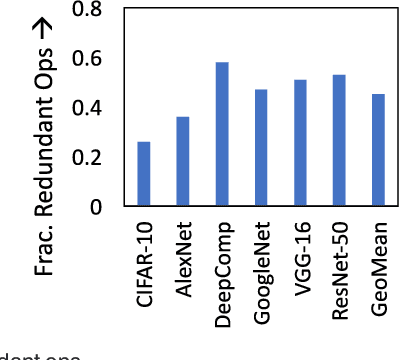
Deep Neural Networks (DNNs) have emerged as the method of choice for solving a wide range of machine learning tasks. The enormous computational demands posed by DNNs have most commonly been addressed through the design of custom accelerators. However, these accelerators are prohibitive in many design scenarios (e.g., wearable devices and IoT sensors), due to stringent area/cost constraints. Accelerating DNNs on these low-power systems, comprising of mainly the general-purpose processor (GPP) cores, requires new approaches. We improve the performance of DNNs on GPPs by exploiting a key attribute of DNNs, i.e., sparsity. We propose Sparsity aware Core Extensions (SparCE)- a set of micro-architectural and ISA extensions that leverage sparsity and are minimally intrusive and low-overhead. We dynamically detect zero operands and skip a set of future instructions that use it. Our design ensures that the instructions to be skipped are prevented from even being fetched, as squashing instructions comes with a penalty. SparCE consists of 2 key micro-architectural enhancements- a Sparsity Register File (SpRF) that tracks zero registers and a Sparsity aware Skip Address (SASA) table that indicates instructions to be skipped. When an instruction is fetched, SparCE dynamically pre-identifies whether the following instruction(s) can be skipped and appropriately modifies the program counter, thereby skipping the redundant instructions and improving performance. We model SparCE using the gem5 architectural simulator, and evaluate our approach on 6 image-recognition DNNs in the context of both training and inference using the Caffe framework. On a scalar microprocessor, SparCE achieves 19%-31% reduction in application-level. We also evaluate SparCE on a 4-way SIMD ARMv8 processor using the OpenBLAS library, and demonstrate that SparCE achieves 8%-15% reduction in the application-level execution time.
DyVEDeep: Dynamic Variable Effort Deep Neural Networks
Apr 04, 2017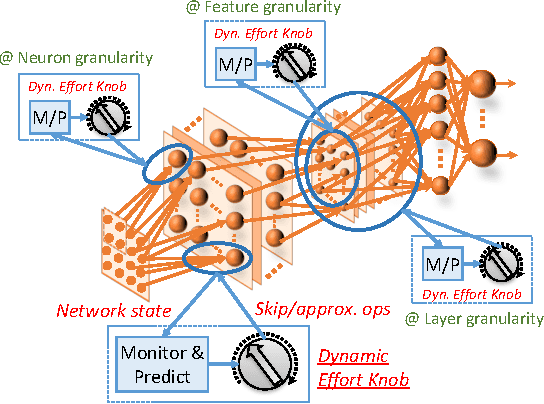
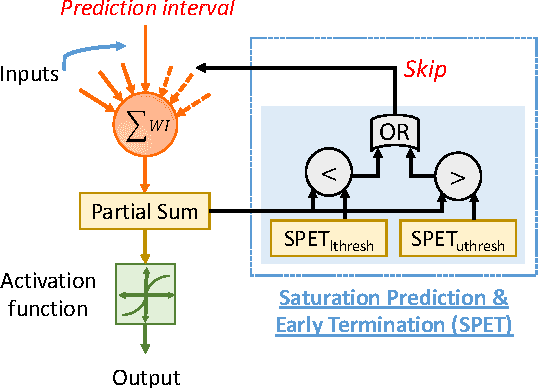
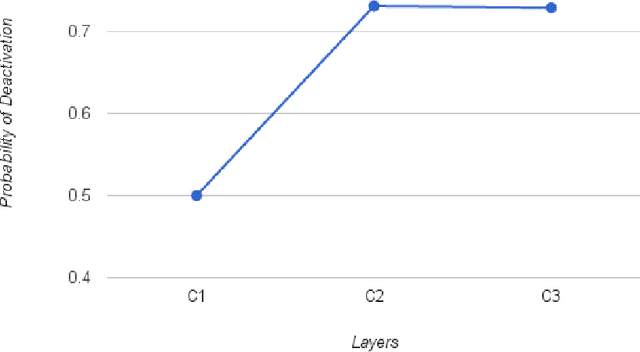
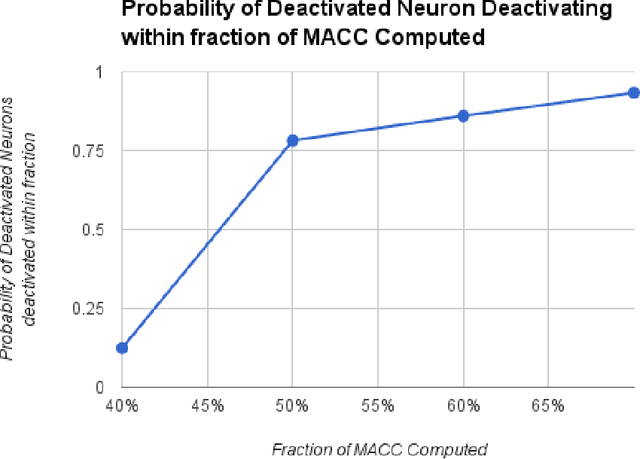
Deep Neural Networks (DNNs) have advanced the state-of-the-art in a variety of machine learning tasks and are deployed in increasing numbers of products and services. However, the computational requirements of training and evaluating large-scale DNNs are growing at a much faster pace than the capabilities of the underlying hardware platforms that they are executed upon. In this work, we propose Dynamic Variable Effort Deep Neural Networks (DyVEDeep) to reduce the computational requirements of DNNs during inference. Previous efforts propose specialized hardware implementations for DNNs, statically prune the network, or compress the weights. Complementary to these approaches, DyVEDeep is a dynamic approach that exploits the heterogeneity in the inputs to DNNs to improve their compute efficiency with comparable classification accuracy. DyVEDeep equips DNNs with dynamic effort mechanisms that, in the course of processing an input, identify how critical a group of computations are to classify the input. DyVEDeep dynamically focuses its compute effort only on the critical computa- tions, while skipping or approximating the rest. We propose 3 effort knobs that operate at different levels of granularity viz. neuron, feature and layer levels. We build DyVEDeep versions for 5 popular image recognition benchmarks - one for CIFAR-10 and four for ImageNet (AlexNet, OverFeat and VGG-16, weight-compressed AlexNet). Across all benchmarks, DyVEDeep achieves 2.1x-2.6x reduction in the number of scalar operations, which translates to 1.8x-2.3x performance improvement over a Caffe-based implementation, with < 0.5% loss in accuracy.