 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
On Background Bias in Deep Metric Learning
Oct 04, 2022

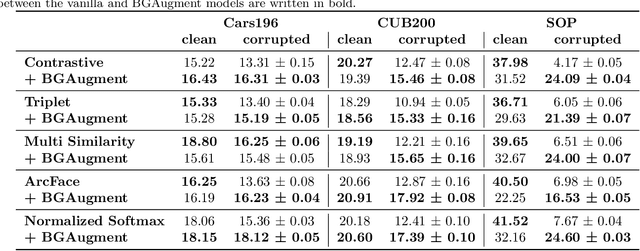

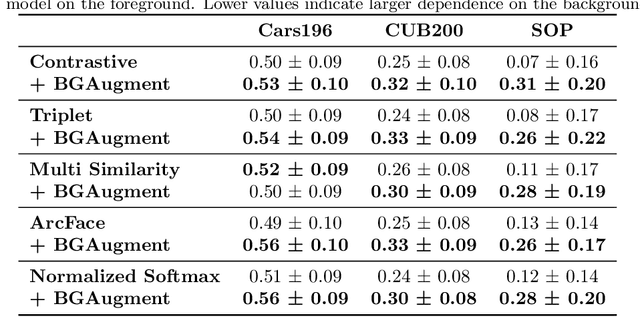
Deep Metric Learning trains a neural network to map input images to a lower-dimensional embedding space such that similar images are closer together than dissimilar images. When used for item retrieval, a query image is embedded using the trained model and the closest items from a database storing their respective embeddings are returned as the most similar items for the query. Especially in product retrieval, where a user searches for a certain product by taking a photo of it, the image background is usually not important and thus should not influence the embedding process. Ideally, the retrieval process always returns fitting items for the photographed object, regardless of the environment the photo was taken in. In this paper, we analyze the influence of the image background on Deep Metric Learning models by utilizing five common loss functions and three common datasets. We find that Deep Metric Learning networks are prone to so-called background bias, which can lead to a severe decrease in retrieval performance when changing the image background during inference. We also show that replacing the background of images during training with random background images alleviates this issue. Since we use an automatic background removal method to do this background replacement, no additional manual labeling work and model changes are required while inference time stays the same. Qualitative and quantitative analyses, for which we introduce a new evaluation metric, confirm that models trained with replaced backgrounds attend more to the main object in the image, benefitting item retrieval systems.
Immersive Neural Graphics Primitives
Nov 24, 2022
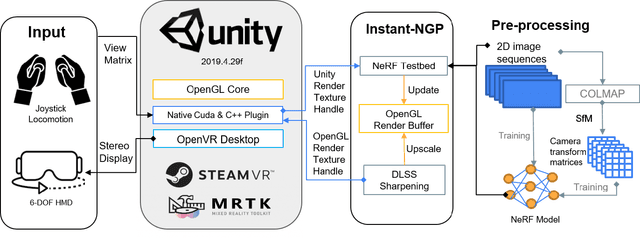

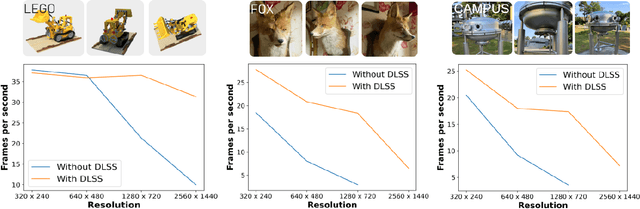
Neural radiance field (NeRF), in particular its extension by instant neural graphics primitives, is a novel rendering method for view synthesis that uses real-world images to build photo-realistic immersive virtual scenes. Despite its potential, research on the combination of NeRF and virtual reality (VR) remains sparse. Currently, there is no integration into typical VR systems available, and the performance and suitability of NeRF implementations for VR have not been evaluated, for instance, for different scene complexities or screen resolutions. In this paper, we present and evaluate a NeRF-based framework that is capable of rendering scenes in immersive VR allowing users to freely move their heads to explore complex real-world scenes. We evaluate our framework by benchmarking three different NeRF scenes concerning their rendering performance at different scene complexities and resolutions. Utilizing super-resolution, our approach can yield a frame rate of 30 frames per second with a resolution of 1280x720 pixels per eye. We discuss potential applications of our framework and provide an open source implementation online.
From Face to Natural Image: Learning Real Degradation for Blind Image Super-Resolution
Oct 03, 2022
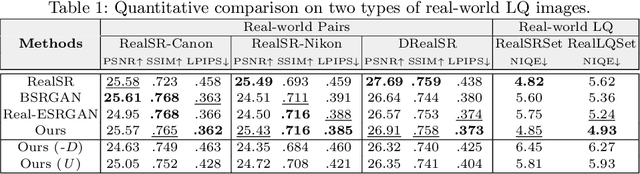
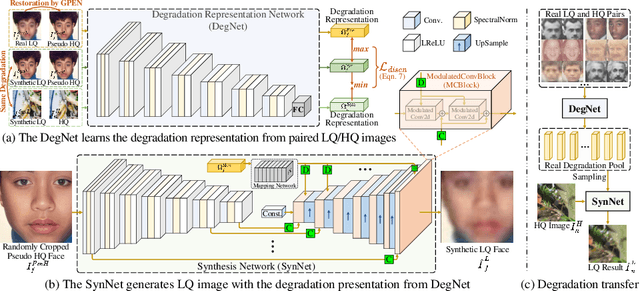

Designing proper training pairs is critical for super-resolving the real-world low-quality (LQ) images, yet suffers from the difficulties in either acquiring paired ground-truth HQ images or synthesizing photo-realistic degraded observations. Recent works mainly circumvent this by simulating the degradation with handcrafted or estimated degradation parameters. However, existing synthetic degradation models are incapable to model complicated real degradation types, resulting in limited improvement on these scenarios, \eg, old photos. Notably, face images, which have the same degradation process with the natural images, can be robustly restored with photo-realistic textures by exploiting their specific structure priors. In this work, we use these real-world LQ face images and their restored HQ counterparts to model the complex real degradation (namely ReDegNet), and then transfer it to HQ natural images to synthesize their realistic LQ ones. Specifically, we take these paired HQ and LQ face images as inputs to explicitly predict the degradation-aware and content-independent representations, which control the degraded image generation. Subsequently, we transfer these real degradation representations from face to natural images to synthesize the degraded LQ natural images. Experiments show that our ReDegNet can well learn the real degradation process from face images, and the restoration network trained with our synthetic pairs performs favorably against SOTAs. More importantly, our method provides a new manner to handle the unsynthesizable real-world scenarios by learning their degradation representations through face images within them, which can be used for specifically fine-tuning. The source code is available at https://github.com/csxmli2016/ReDegNet.
Hide-and-Tell: Learning to Bridge Photo Streams for Visual Storytelling
Feb 03, 2020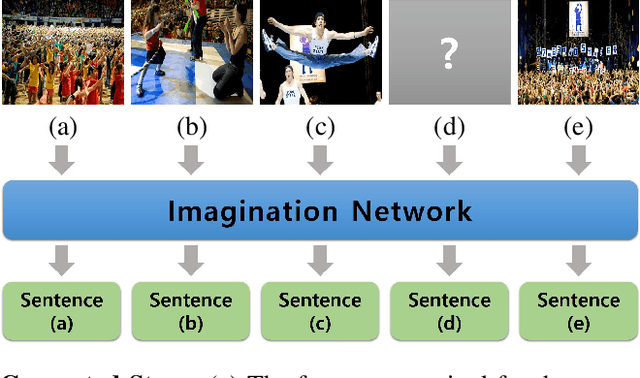
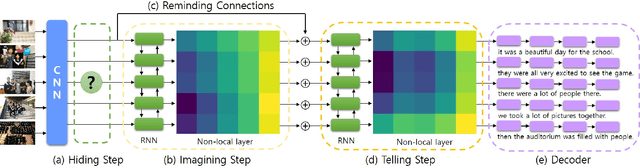
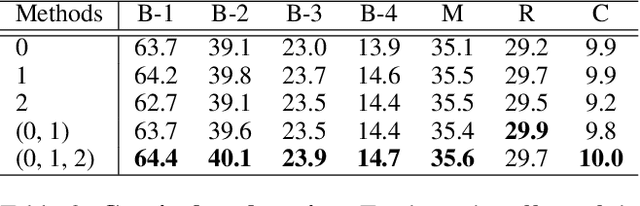
Visual storytelling is a task of creating a short story based on photo streams. Unlike existing visual captioning, storytelling aims to contain not only factual descriptions, but also human-like narration and semantics. However, the VIST dataset consists only of a small, fixed number of photos per story. Therefore, the main challenge of visual storytelling is to fill in the visual gap between photos with narrative and imaginative story. In this paper, we propose to explicitly learn to imagine a storyline that bridges the visual gap. During training, one or more photos is randomly omitted from the input stack, and we train the network to produce a full plausible story even with missing photo(s). Furthermore, we propose for visual storytelling a hide-and-tell model, which is designed to learn non-local relations across the photo streams and to refine and improve conventional RNN-based models. In experiments, we show that our scheme of hide-and-tell, and the network design are indeed effective at storytelling, and that our model outperforms previous state-of-the-art methods in automatic metrics. Finally, we qualitatively show the learned ability to interpolate storyline over visual gaps.
PV3D: A 3D Generative Model for Portrait Video Generation
Dec 13, 2022
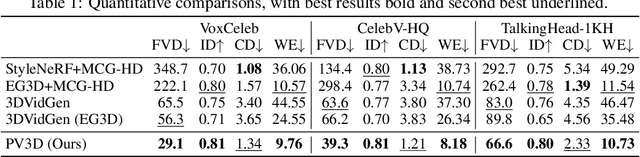
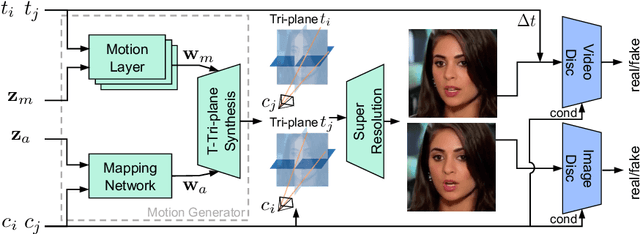
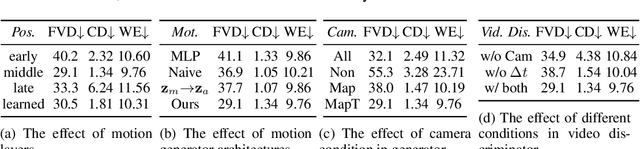
Recent advances in generative adversarial networks (GANs) have demonstrated the capabilities of generating stunning photo-realistic portrait images. While some prior works have applied such image GANs to unconditional 2D portrait video generation and static 3D portrait synthesis, there are few works successfully extending GANs for generating 3D-aware portrait videos. In this work, we propose PV3D, the first generative framework that can synthesize multi-view consistent portrait videos. Specifically, our method extends the recent static 3D-aware image GAN to the video domain by generalizing the 3D implicit neural representation to model the spatio-temporal space. To introduce motion dynamics to the generation process, we develop a motion generator by stacking multiple motion layers to generate motion features via modulated convolution. To alleviate motion ambiguities caused by camera/human motions, we propose a simple yet effective camera condition strategy for PV3D, enabling both temporal and multi-view consistent video generation. Moreover, PV3D introduces two discriminators for regularizing the spatial and temporal domains to ensure the plausibility of the generated portrait videos. These elaborated designs enable PV3D to generate 3D-aware motion-plausible portrait videos with high-quality appearance and geometry, significantly outperforming prior works. As a result, PV3D is able to support many downstream applications such as animating static portraits and view-consistent video motion editing. Code and models will be released at https://showlab.github.io/pv3d.
HARP: Personalized Hand Reconstruction from a Monocular RGB Video
Dec 19, 2022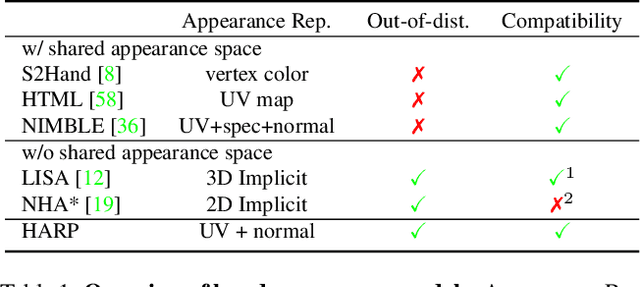



We present HARP (HAnd Reconstruction and Personalization), a personalized hand avatar creation approach that takes a short monocular RGB video of a human hand as input and reconstructs a faithful hand avatar exhibiting a high-fidelity appearance and geometry. In contrast to the major trend of neural implicit representations, HARP models a hand with a mesh-based parametric hand model, a vertex displacement map, a normal map, and an albedo without any neural components. As validated by our experiments, the explicit nature of our representation enables a truly scalable, robust, and efficient approach to hand avatar creation. HARP is optimized via gradient descent from a short sequence captured by a hand-held mobile phone and can be directly used in AR/VR applications with real-time rendering capability. To enable this, we carefully design and implement a shadow-aware differentiable rendering scheme that is robust to high degree articulations and self-shadowing regularly present in hand motion sequences, as well as challenging lighting conditions. It also generalizes to unseen poses and novel viewpoints, producing photo-realistic renderings of hand animations performing highly-articulated motions. Furthermore, the learned HARP representation can be used for improving 3D hand pose estimation quality in challenging viewpoints. The key advantages of HARP are validated by the in-depth analyses on appearance reconstruction, novel-view and novel pose synthesis, and 3D hand pose refinement. It is an AR/VR-ready personalized hand representation that shows superior fidelity and scalability.
DynIBaR: Neural Dynamic Image-Based Rendering
Nov 28, 2022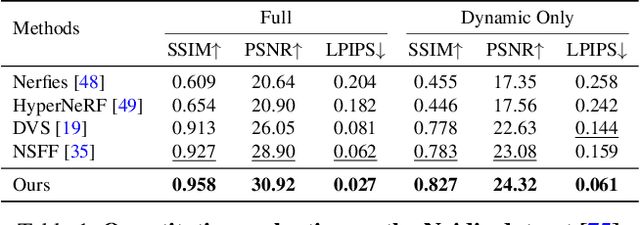
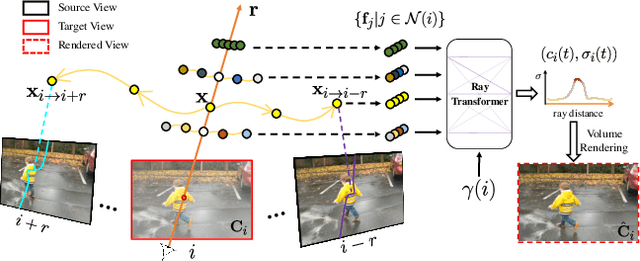
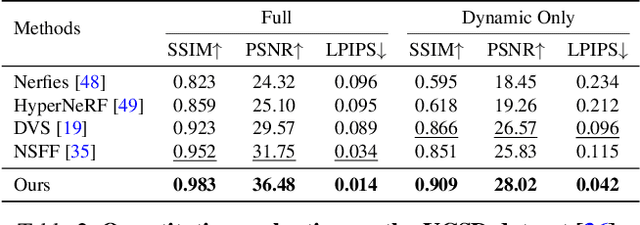
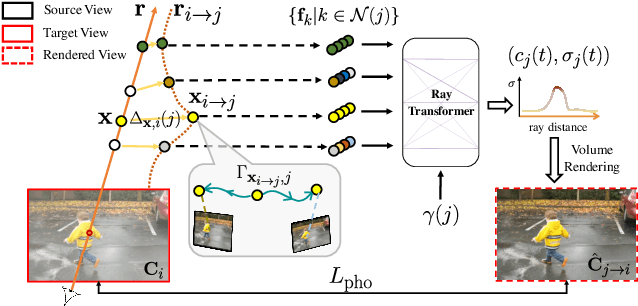
We address the problem of synthesizing novel views from a monocular video depicting a complex dynamic scene. State-of-the-art methods based on temporally varying Neural Radiance Fields (aka dynamic NeRFs) have shown impressive results on this task. However, for long videos with complex object motions and uncontrolled camera trajectories, these methods can produce blurry or inaccurate renderings, hampering their use in real-world applications. Instead of encoding the entire dynamic scene within the weights of an MLP, we present a new approach that addresses these limitations by adopting a volumetric image-based rendering framework that synthesizes new viewpoints by aggregating features from nearby views in a scene-motion-aware manner. Our system retains the advantages of prior methods in its ability to model complex scenes and view-dependent effects, but also enables synthesizing photo-realistic novel views from long videos featuring complex scene dynamics with unconstrained camera trajectories. We demonstrate significant improvements over state-of-the-art methods on dynamic scene datasets, and also apply our approach to in-the-wild videos with challenging camera and object motion, where prior methods fail to produce high-quality renderings. Our project webpage is at dynibar.github.io.
High-fidelity Facial Avatar Reconstruction from Monocular Video with Generative Priors
Nov 28, 2022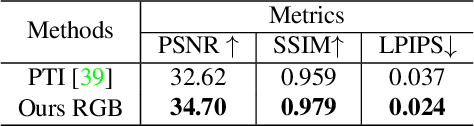
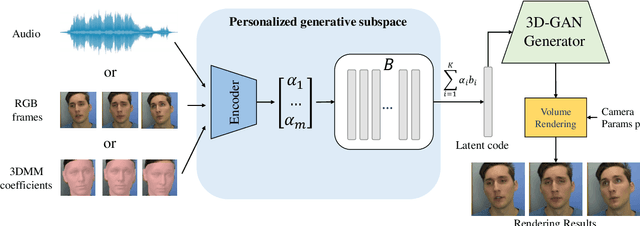
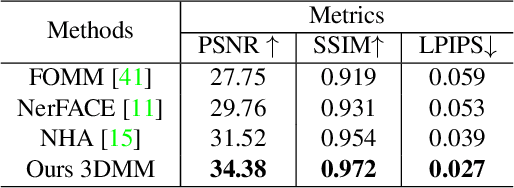
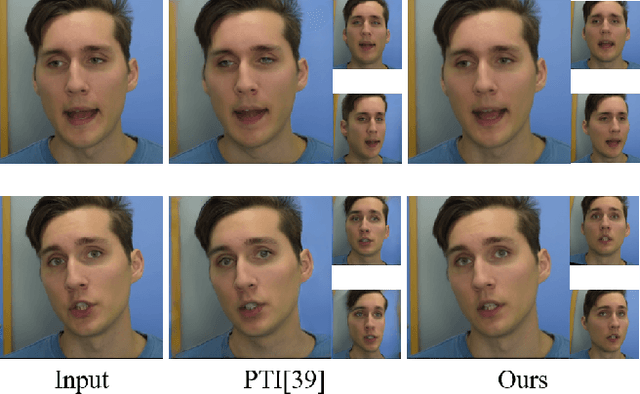
High-fidelity facial avatar reconstruction from a monocular video is a significant research problem in computer graphics and computer vision. Recently, Neural Radiance Field (NeRF) has shown impressive novel view rendering results and has been considered for facial avatar reconstruction. However, the complex facial dynamics and missing 3D information in monocular videos raise significant challenges for faithful facial reconstruction. In this work, we propose a new method for NeRF-based facial avatar reconstruction that utilizes 3D-aware generative prior. Different from existing works that depend on a conditional deformation field for dynamic modeling, we propose to learn a personalized generative prior, which is formulated as a local and low dimensional subspace in the latent space of 3D-GAN. We propose an efficient method to construct the personalized generative prior based on a small set of facial images of a given individual. After learning, it allows for photo-realistic rendering with novel views and the face reenactment can be realized by performing navigation in the latent space. Our proposed method is applicable for different driven signals, including RGB images, 3DMM coefficients, and audios. Compared with existing works, we obtain superior novel view synthesis results and faithfully face reenactment performance.
Sample-specific repetitive learning for photo aesthetic assessment and highlight region extraction
Sep 18, 2019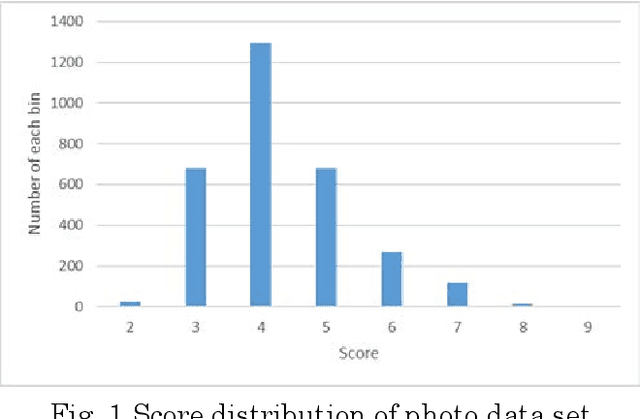
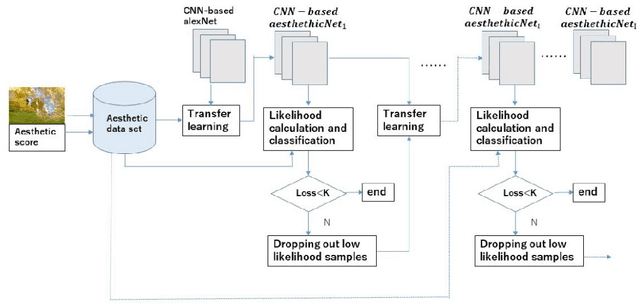

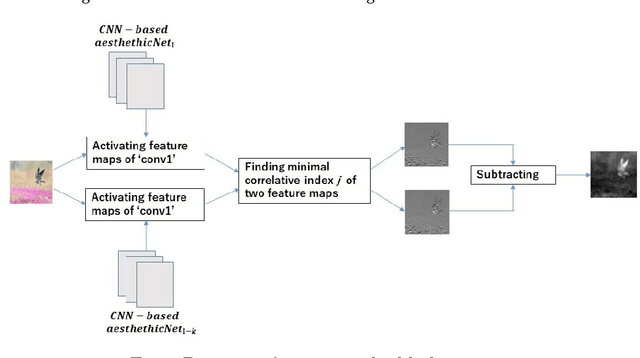
Aesthetic assessment is subjective, and the distribution of the aesthetic levels is imbalanced. In order to realize the auto-assessment of photo aesthetics, we focus on retraining the CNN-based aesthetic assessment model by dropping out the unavailable samples in the middle levels from the training data set repetitively to overcome the effect of imbalanced aesthetic data on classification. Further, the method of extracting aesthetics highlight region of the photo image by using the two repetitively trained models is presented. Therefore, the correlation of the extracted region with the aesthetic levels is analyzed to illustrate what aesthetics features influence the aesthetic quality of the photo. Moreover, the testing data set is from the different data source called 500px. Experimental results show that the proposed method is effective.
Real-World Image Super Resolution via Unsupervised Bi-directional Cycle Domain Transfer Learning based Generative Adversarial Network
Nov 19, 2022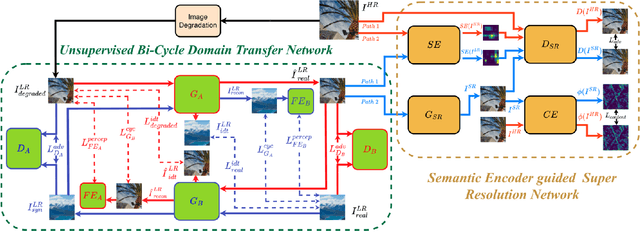
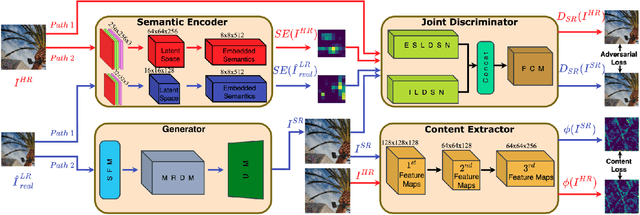
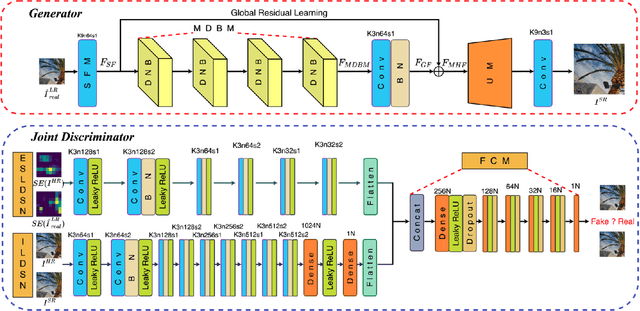

Deep Convolutional Neural Networks (DCNNs) have exhibited impressive performance on image super-resolution tasks. However, these deep learning-based super-resolution methods perform poorly in real-world super-resolution tasks, where the paired high-resolution and low-resolution images are unavailable and the low-resolution images are degraded by complicated and unknown kernels. To break these limitations, we propose the Unsupervised Bi-directional Cycle Domain Transfer Learning-based Generative Adversarial Network (UBCDTL-GAN), which consists of an Unsupervised Bi-directional Cycle Domain Transfer Network (UBCDTN) and the Semantic Encoder guided Super Resolution Network (SESRN). First, the UBCDTN is able to produce an approximated real-like LR image through transferring the LR image from an artificially degraded domain to the real-world LR image domain. Second, the SESRN has the ability to super-resolve the approximated real-like LR image to a photo-realistic HR image. Extensive experiments on unpaired real-world image benchmark datasets demonstrate that the proposed method achieves superior performance compared to state-of-the-art methods.