 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJVLGS: Joint Vision-Language Gas Leak Segmentation
Aug 27, 2025Gas leaks pose serious threats to human health and contribute significantly to atmospheric pollution, drawing increasing public concern. However, the lack of effective detection methods hampers timely and accurate identification of gas leaks. While some vision-based techniques leverage infrared videos for leak detection, the blurry and non-rigid nature of gas clouds often limits their effectiveness. To address these challenges, we propose a novel framework called Joint Vision-Language Gas leak Segmentation (JVLGS), which integrates the complementary strengths of visual and textual modalities to enhance gas leak representation and segmentation. Recognizing that gas leaks are sporadic and many video frames may contain no leak at all, our method incorporates a post-processing step to reduce false positives caused by noise and non-target objects, an issue that affects many existing approaches. Extensive experiments conducted across diverse scenarios show that JVLGS significantly outperforms state-of-the-art gas leak segmentation methods. We evaluate our model under both supervised and few-shot learning settings, and it consistently achieves strong performance in both, whereas competing methods tend to perform well in only one setting or poorly in both. Code available at: https://github.com/GeekEagle/JVLGS
Real-World Image Super Resolution via Unsupervised Bi-directional Cycle Domain Transfer Learning based Generative Adversarial Network
Nov 19, 2022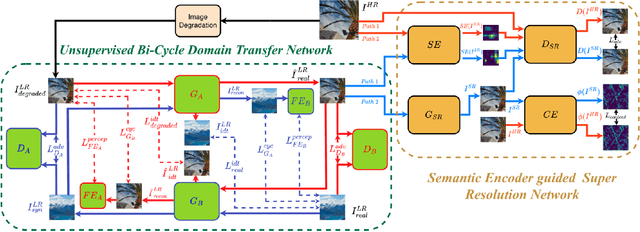


Deep Convolutional Neural Networks (DCNNs) have exhibited impressive performance on image super-resolution tasks. However, these deep learning-based super-resolution methods perform poorly in real-world super-resolution tasks, where the paired high-resolution and low-resolution images are unavailable and the low-resolution images are degraded by complicated and unknown kernels. To break these limitations, we propose the Unsupervised Bi-directional Cycle Domain Transfer Learning-based Generative Adversarial Network (UBCDTL-GAN), which consists of an Unsupervised Bi-directional Cycle Domain Transfer Network (UBCDTN) and the Semantic Encoder guided Super Resolution Network (SESRN). First, the UBCDTN is able to produce an approximated real-like LR image through transferring the LR image from an artificially degraded domain to the real-world LR image domain. Second, the SESRN has the ability to super-resolve the approximated real-like LR image to a photo-realistic HR image. Extensive experiments on unpaired real-world image benchmark datasets demonstrate that the proposed method achieves superior performance compared to state-of-the-art methods.
Semantic Encoder Guided Generative Adversarial Face Ultra-Resolution Network
Nov 18, 2022



Face super-resolution is a domain-specific image super-resolution, which aims to generate High-Resolution (HR) face images from their Low-Resolution (LR) counterparts. In this paper, we propose a novel face super-resolution method, namely Semantic Encoder guided Generative Adversarial Face Ultra-Resolution Network (SEGA-FURN) to ultra-resolve an unaligned tiny LR face image to its HR counterpart with multiple ultra-upscaling factors (e.g., 4x and 8x). The proposed network is composed of a novel semantic encoder that has the ability to capture the embedded semantics to guide adversarial learning and a novel generator that uses a hierarchical architecture named Residual in Internal Dense Block (RIDB). Moreover, we propose a joint discriminator which discriminates both image data and embedded semantics. The joint discriminator learns the joint probability distribution of the image space and latent space. We also use a Relativistic average Least Squares loss (RaLS) as the adversarial loss to alleviate the gradient vanishing problem and enhance the stability of the training procedure. Extensive experiments on large face datasets have proved that the proposed method can achieve superior super-resolution results and significantly outperform other state-of-the-art methods in both qualitative and quantitative comparisons.