 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
One-shot Unsupervised Domain Adaptation with Personalized Diffusion Models
Mar 31, 2023
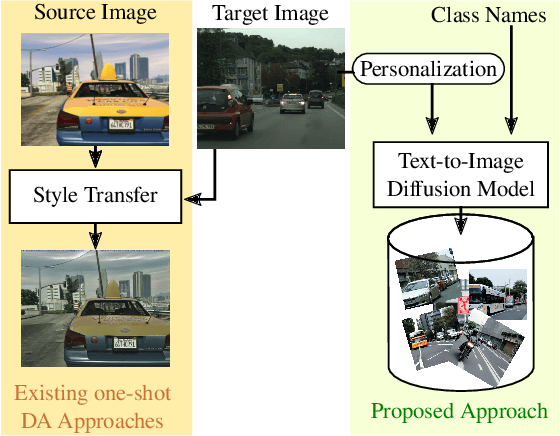
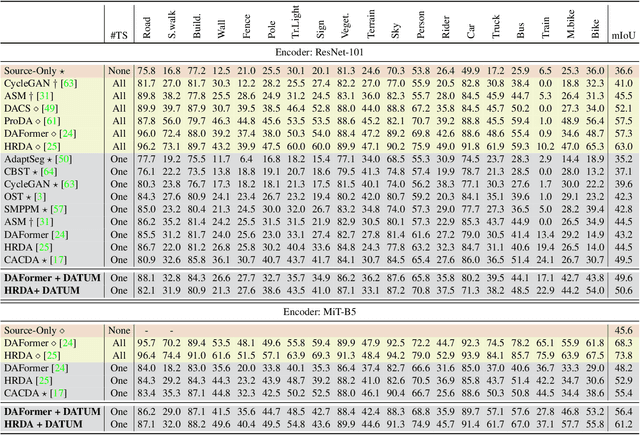
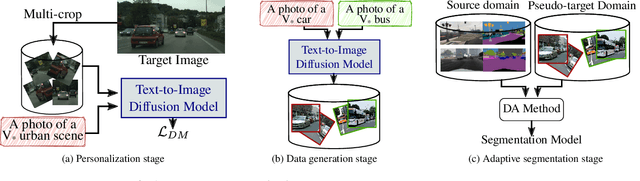
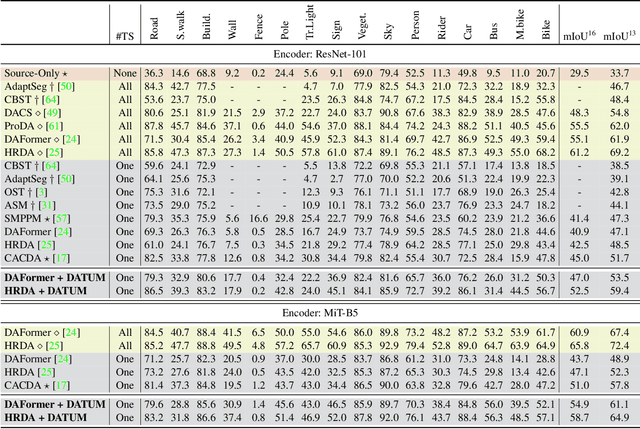
Adapting a segmentation model from a labeled source domain to a target domain, where a single unlabeled datum is available, is one the most challenging problems in domain adaptation and is otherwise known as one-shot unsupervised domain adaptation (OSUDA). Most of the prior works have addressed the problem by relying on style transfer techniques, where the source images are stylized to have the appearance of the target domain. Departing from the common notion of transferring only the target ``texture'' information, we leverage text-to-image diffusion models (e.g., Stable Diffusion) to generate a synthetic target dataset with photo-realistic images that not only faithfully depict the style of the target domain, but are also characterized by novel scenes in diverse contexts. The text interface in our method Data AugmenTation with diffUsion Models (DATUM) endows us with the possibility of guiding the generation of images towards desired semantic concepts while respecting the original spatial context of a single training image, which is not possible in existing OSUDA methods. Extensive experiments on standard benchmarks show that our DATUM surpasses the state-of-the-art OSUDA methods by up to +7.1%. The implementation is available at https://github.com/yasserben/DATUM
FONT: Flow-guided One-shot Talking Head Generation with Natural Head Motions
Mar 31, 2023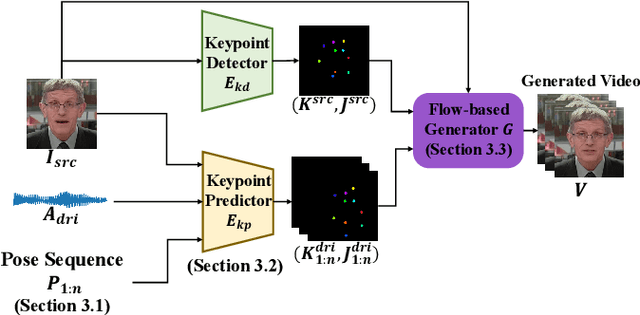
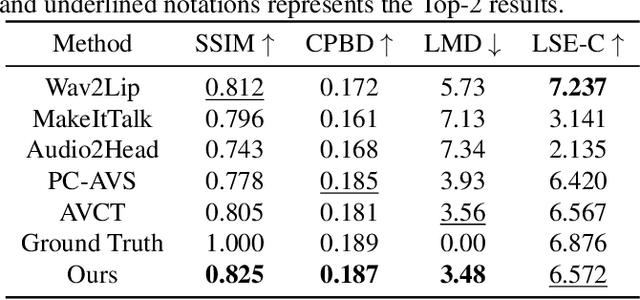
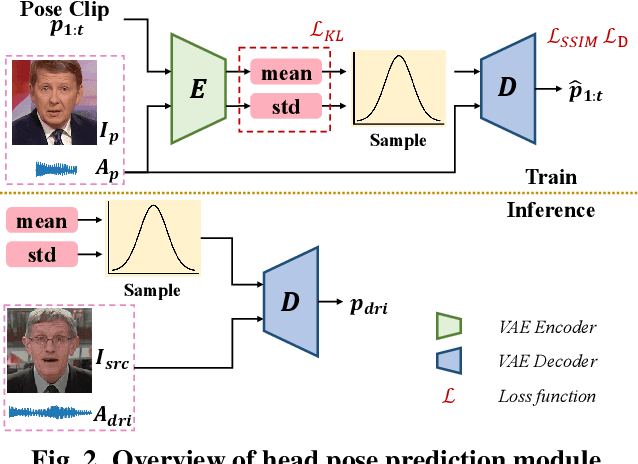
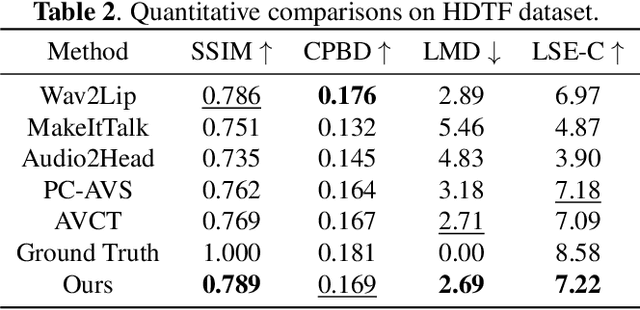
One-shot talking head generation has received growing attention in recent years, with various creative and practical applications. An ideal natural and vivid generated talking head video should contain natural head pose changes. However, it is challenging to map head pose sequences from driving audio since there exists a natural gap between audio-visual modalities. In this work, we propose a Flow-guided One-shot model that achieves NaTural head motions(FONT) over generated talking heads. Specifically, the head pose prediction module is designed to generate head pose sequences from the source face and driving audio. We add the random sampling operation and the structural similarity constraint to model the diversity in the one-to-many mapping between audio-visual modality, thus predicting natural head poses. Then we develop a keypoint predictor that produces unsupervised keypoints from the source face, driving audio and pose sequences to describe the facial structure information. Finally, a flow-guided occlusion-aware generator is employed to produce photo-realistic talking head videos from the estimated keypoints and source face. Extensive experimental results prove that FONT generates talking heads with natural head poses and synchronized mouth shapes, outperforming other compared methods.
Very Lightweight Photo Retouching Network with Conditional Sequential Modulation
Apr 13, 2021
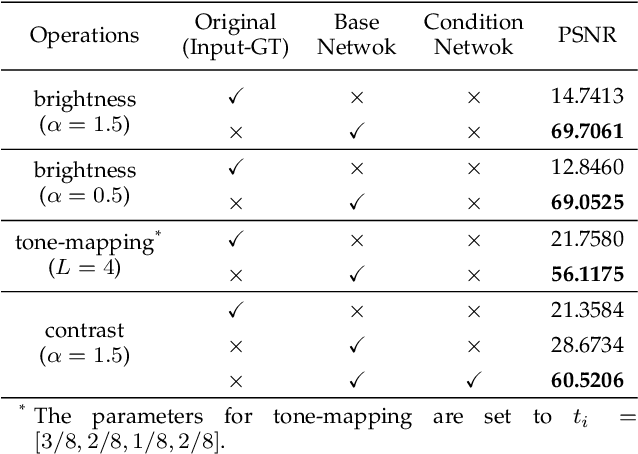
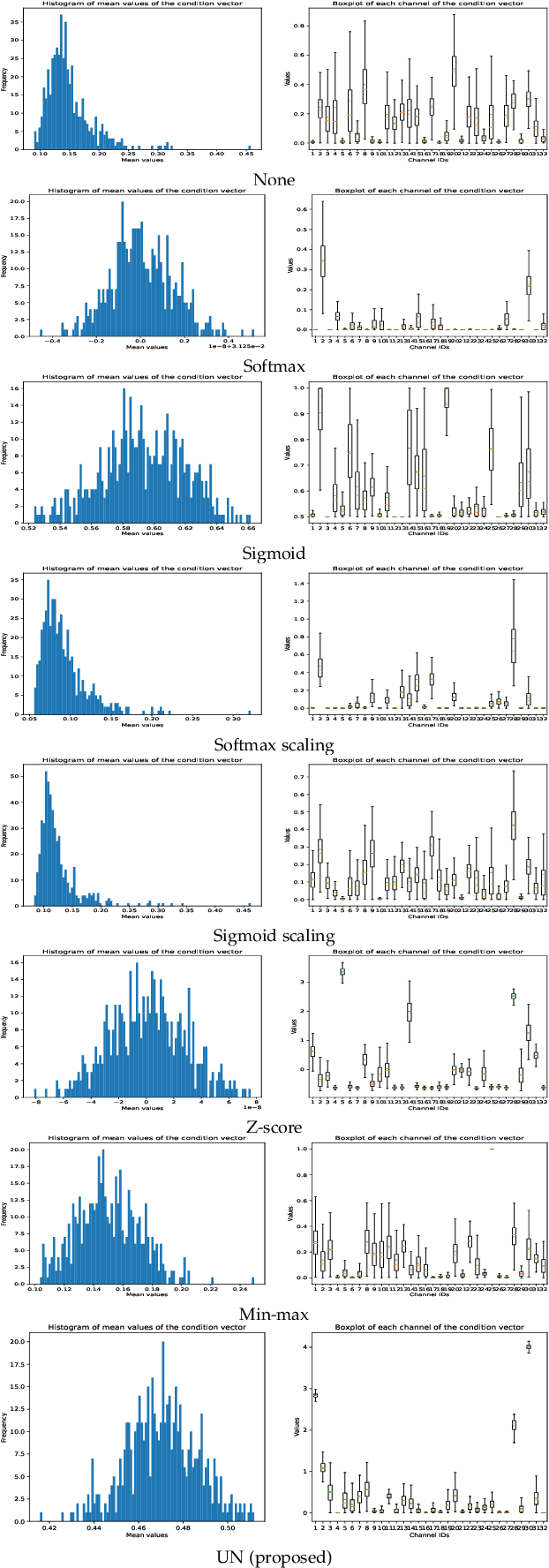
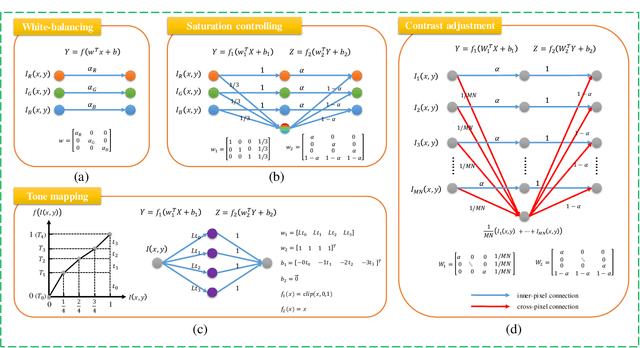
Photo retouching aims at improving the aesthetic visual quality of images that suffer from photographic defects such as poor contrast, over/under exposure, and inharmonious saturation. In practice, photo retouching can be accomplished by a series of image processing operations. As most commonly-used retouching operations are pixel-independent, i.e., the manipulation on one pixel is uncorrelated with its neighboring pixels, we can take advantage of this property and design a specialized algorithm for efficient global photo retouching. We analyze these global operations and find that they can be mathematically formulated by a Multi-Layer Perceptron (MLP). Based on this observation, we propose an extremely lightweight framework -- Conditional Sequential Retouching Network (CSRNet). Benefiting from the utilization of $1\times1$ convolution, CSRNet only contains less than 37K trainable parameters, which are orders of magnitude smaller than existing learning-based methods. Experiments show that our method achieves state-of-the-art performance on the benchmark MIT-Adobe FiveK dataset quantitively and qualitatively. In addition to achieve global photo retouching, the proposed framework can be easily extended to learn local enhancement effects. The extended model, namly CSRNet-L, also achieves competitive results in various local enhancement tasks. Codes will be available.
HyperINR: A Fast and Predictive Hypernetwork for Implicit Neural Representations via Knowledge Distillation
Apr 09, 2023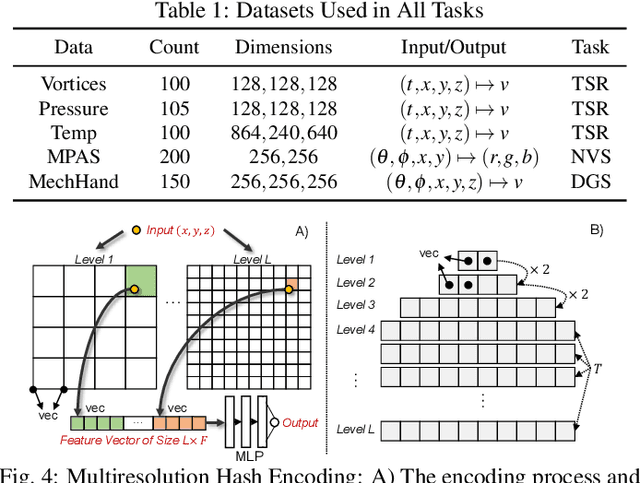
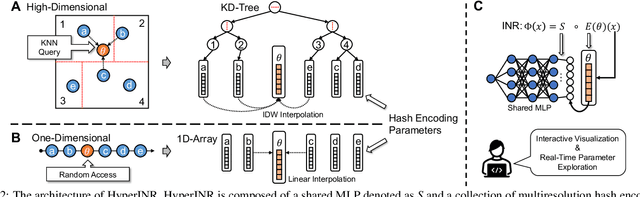
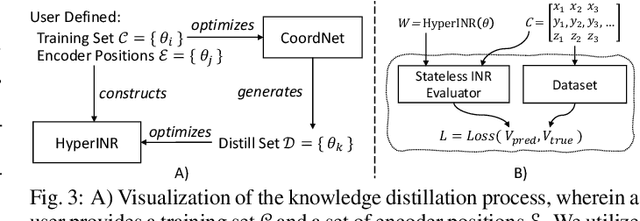
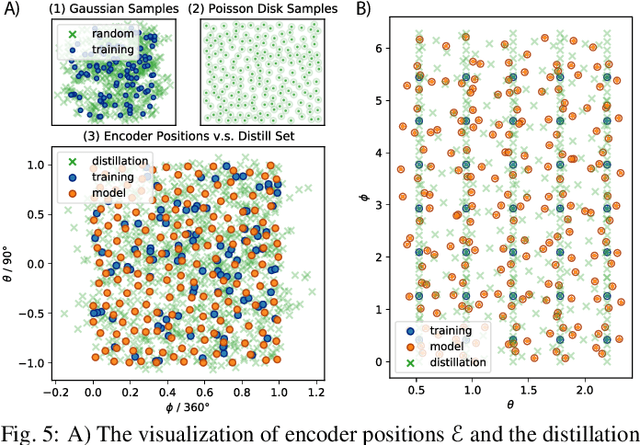
Implicit Neural Representations (INRs) have recently exhibited immense potential in the field of scientific visualization for both data generation and visualization tasks. However, these representations often consist of large multi-layer perceptrons (MLPs), necessitating millions of operations for a single forward pass, consequently hindering interactive visual exploration. While reducing the size of the MLPs and employing efficient parametric encoding schemes can alleviate this issue, it compromises generalizability for unseen parameters, rendering it unsuitable for tasks such as temporal super-resolution. In this paper, we introduce HyperINR, a novel hypernetwork architecture capable of directly predicting the weights for a compact INR. By harnessing an ensemble of multiresolution hash encoding units in unison, the resulting INR attains state-of-the-art inference performance (up to 100x higher inference bandwidth) and can support interactive photo-realistic volume visualization. Additionally, by incorporating knowledge distillation, exceptional data and visualization generation quality is achieved, making our method valuable for real-time parameter exploration. We validate the effectiveness of the HyperINR architecture through a comprehensive ablation study. We showcase the versatility of HyperINR across three distinct scientific domains: novel view synthesis, temporal super-resolution of volume data, and volume rendering with dynamic global shadows. By simultaneously achieving efficiency and generalizability, HyperINR paves the way for applying INR in a wider array of scientific visualization applications.
BLiRF-RF: Bandlimited Radiance Fields for Dynamic Scene Modeling
Mar 18, 2023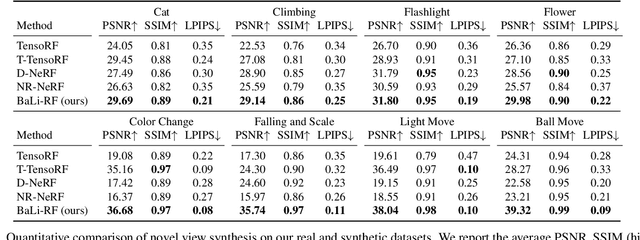
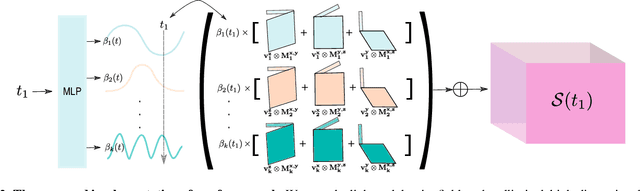

Reasoning the 3D structure of a non-rigid dynamic scene from a single moving camera is an under-constrained problem. Inspired by the remarkable progress of neural radiance fields (NeRFs) in photo-realistic novel view synthesis of static scenes, extensions have been proposed for dynamic settings. These methods heavily rely on neural priors in order to regularize the problem. In this work, we take a step back and reinvestigate how current implementations may entail deleterious effects, including limited expressiveness, entanglement of light and density fields, and sub-optimal motion localization. As a remedy, we advocate for a bridge between classic non-rigid-structure-from-motion (\nrsfm) and NeRF, enabling the well-studied priors of the former to constrain the latter. To this end, we propose a framework that factorizes time and space by formulating a scene as a composition of bandlimited, high-dimensional signals. We demonstrate compelling results across complex dynamic scenes that involve changes in lighting, texture and long-range dynamics.
HandNeRF: Neural Radiance Fields for Animatable Interacting Hands
Mar 24, 2023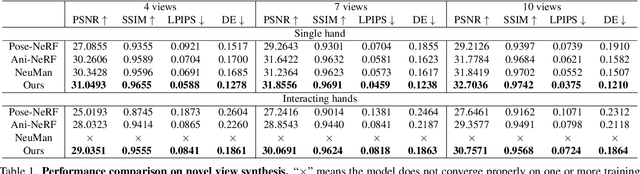
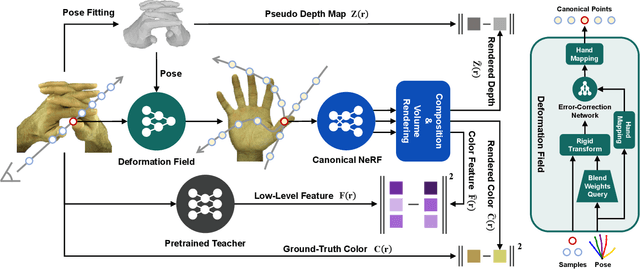
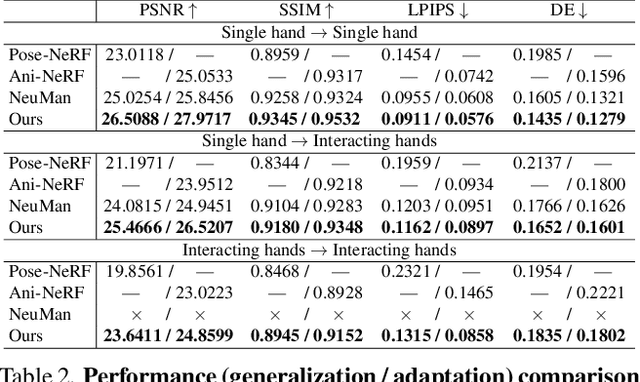
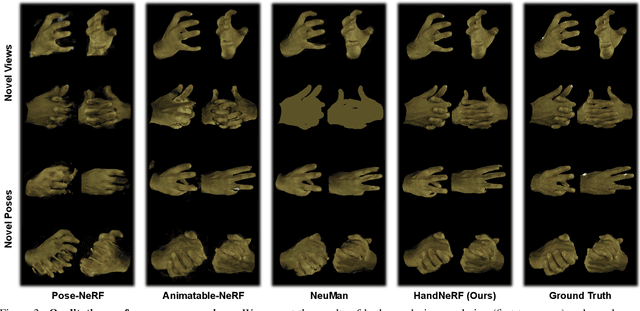
We propose a novel framework to reconstruct accurate appearance and geometry with neural radiance fields (NeRF) for interacting hands, enabling the rendering of photo-realistic images and videos for gesture animation from arbitrary views. Given multi-view images of a single hand or interacting hands, an off-the-shelf skeleton estimator is first employed to parameterize the hand poses. Then we design a pose-driven deformation field to establish correspondence from those different poses to a shared canonical space, where a pose-disentangled NeRF for one hand is optimized. Such unified modeling efficiently complements the geometry and texture cues in rarely-observed areas for both hands. Meanwhile, we further leverage the pose priors to generate pseudo depth maps as guidance for occlusion-aware density learning. Moreover, a neural feature distillation method is proposed to achieve cross-domain alignment for color optimization. We conduct extensive experiments to verify the merits of our proposed HandNeRF and report a series of state-of-the-art results both qualitatively and quantitatively on the large-scale InterHand2.6M dataset.
Efficient Scale-Invariant Generator with Column-Row Entangled Pixel Synthesis
Mar 29, 2023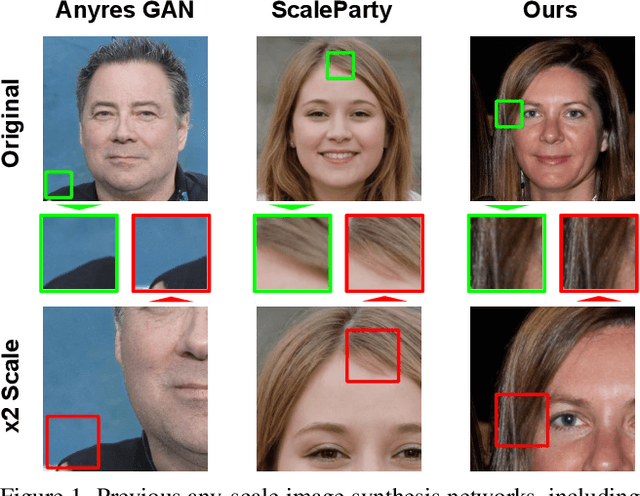
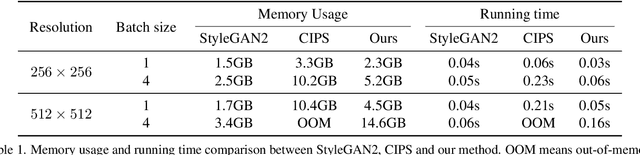
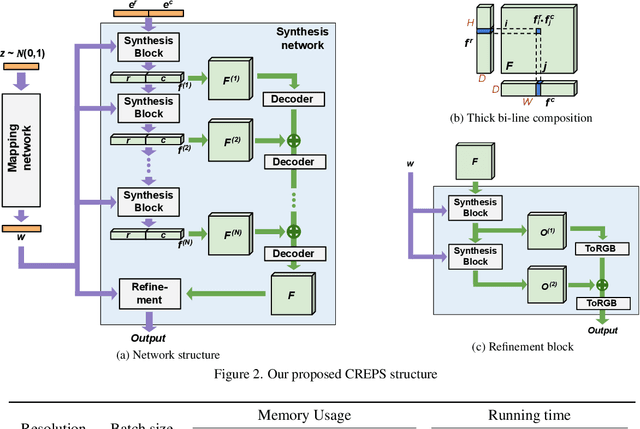

Any-scale image synthesis offers an efficient and scalable solution to synthesize photo-realistic images at any scale, even going beyond 2K resolution. However, existing GAN-based solutions depend excessively on convolutions and a hierarchical architecture, which introduce inconsistency and the $``$texture sticking$"$ issue when scaling the output resolution. From another perspective, INR-based generators are scale-equivariant by design, but their huge memory footprint and slow inference hinder these networks from being adopted in large-scale or real-time systems. In this work, we propose $\textbf{C}$olumn-$\textbf{R}$ow $\textbf{E}$ntangled $\textbf{P}$ixel $\textbf{S}$ynthesis ($\textbf{CREPS}$), a new generative model that is both efficient and scale-equivariant without using any spatial convolutions or coarse-to-fine design. To save memory footprint and make the system scalable, we employ a novel bi-line representation that decomposes layer-wise feature maps into separate $``$thick$"$ column and row encodings. Experiments on various datasets, including FFHQ, LSUN-Church, MetFaces, and Flickr-Scenery, confirm CREPS' ability to synthesize scale-consistent and alias-free images at any arbitrary resolution with proper training and inference speed. Code is available at https://github.com/VinAIResearch/CREPS.
SYNTA: A novel approach for deep learning-based image analysis in muscle histopathology using photo-realistic synthetic data
Aug 03, 2022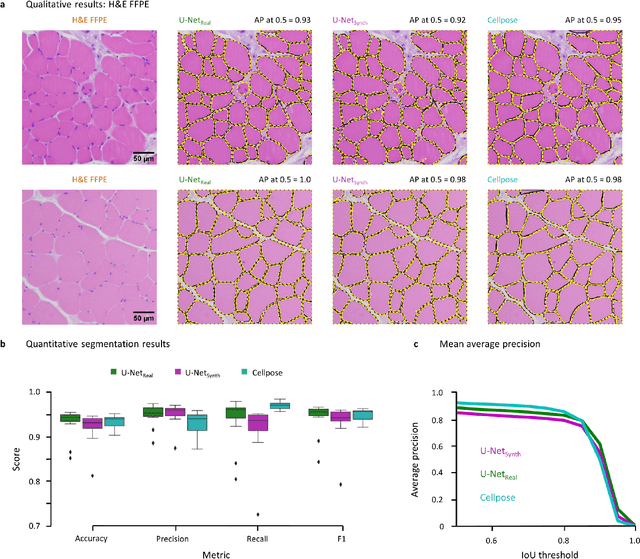
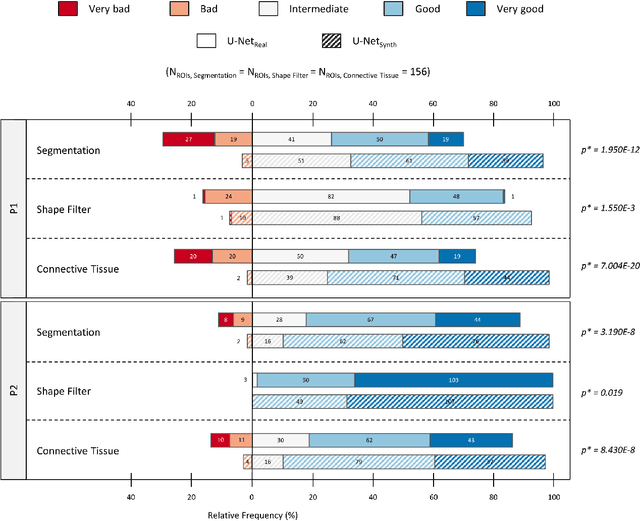
Artificial intelligence (AI), machine learning, and deep learning (DL) methods are becoming increasingly important in the field of biomedical image analysis. However, to exploit the full potential of such methods, a representative number of experimentally acquired images containing a significant number of manually annotated objects is needed as training data. Here we introduce SYNTA (synthetic data) as a novel approach for the generation of synthetic, photo-realistic, and highly complex biomedical images as training data for DL systems. We show the versatility of our approach in the context of muscle fiber and connective tissue analysis in histological sections. We demonstrate that it is possible to perform robust and expert-level segmentation tasks on previously unseen real-world data, without the need for manual annotations using synthetic training data alone. Being a fully parametric technique, our approach poses an interpretable and controllable alternative to Generative Adversarial Networks (GANs) and has the potential to significantly accelerate quantitative image analysis in a variety of biomedical applications in microscopy and beyond.
LayoutDiffuse: Adapting Foundational Diffusion Models for Layout-to-Image Generation
Feb 16, 2023
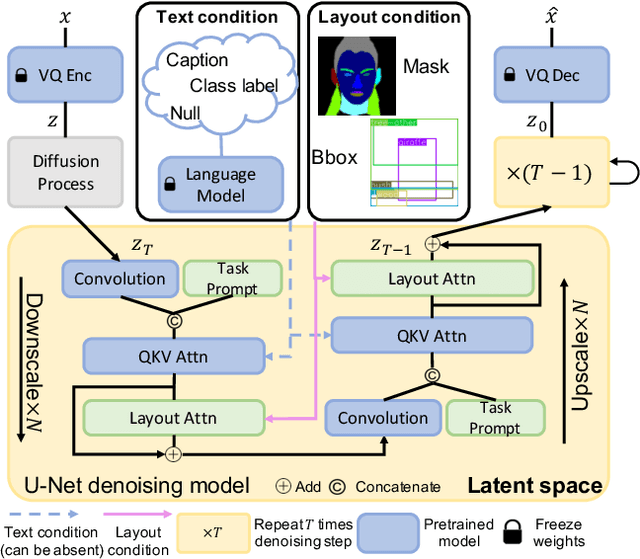
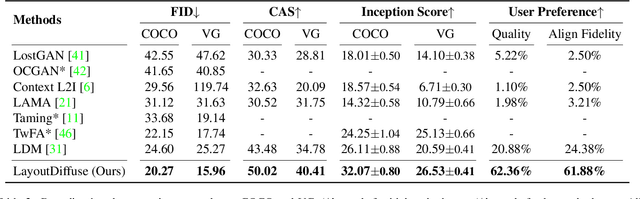
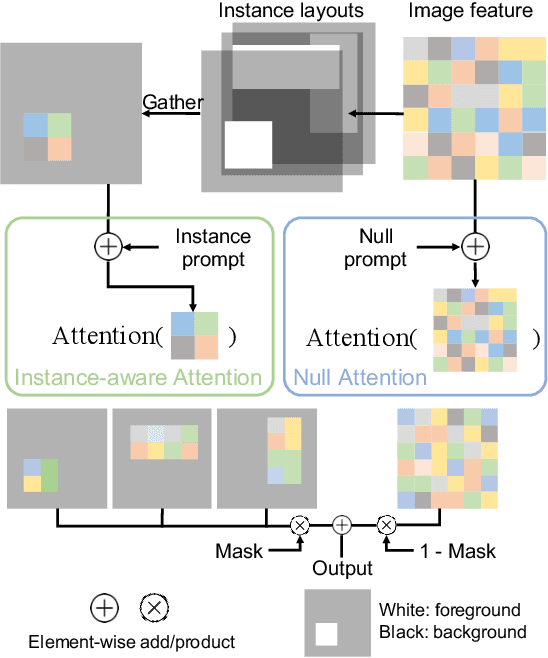
Layout-to-image generation refers to the task of synthesizing photo-realistic images based on semantic layouts. In this paper, we propose LayoutDiffuse that adapts a foundational diffusion model pretrained on large-scale image or text-image datasets for layout-to-image generation. By adopting a novel neural adaptor based on layout attention and task-aware prompts, our method trains efficiently, generates images with both high perceptual quality and layout alignment, and needs less data. Experiments on three datasets show that our method significantly outperforms other 10 generative models based on GANs, VQ-VAE, and diffusion models.
NeRFLiX: High-Quality Neural View Synthesis by Learning a Degradation-Driven Inter-viewpoint MiXer
Mar 22, 2023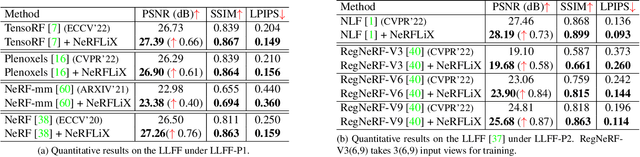
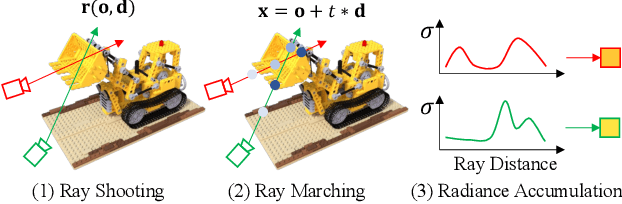
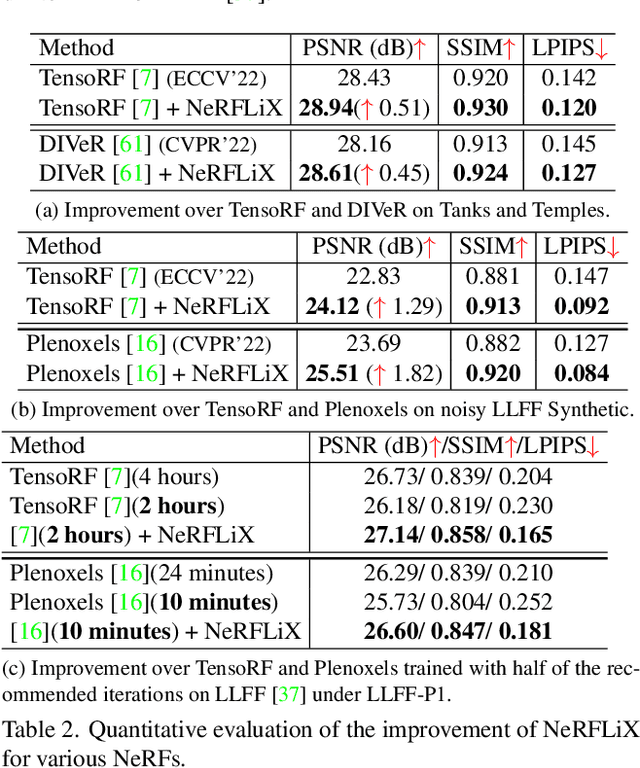
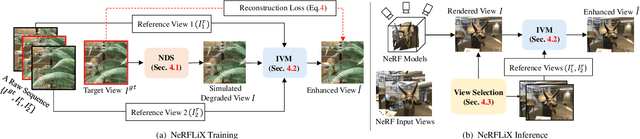
Neural radiance fields (NeRF) show great success in novel view synthesis. However, in real-world scenes, recovering high-quality details from the source images is still challenging for the existing NeRF-based approaches, due to the potential imperfect calibration information and scene representation inaccuracy. Even with high-quality training frames, the synthetic novel views produced by NeRF models still suffer from notable rendering artifacts, such as noise, blur, etc. Towards to improve the synthesis quality of NeRF-based approaches, we propose NeRFLiX, a general NeRF-agnostic restorer paradigm by learning a degradation-driven inter-viewpoint mixer. Specially, we design a NeRF-style degradation modeling approach and construct large-scale training data, enabling the possibility of effectively removing NeRF-native rendering artifacts for existing deep neural networks. Moreover, beyond the degradation removal, we propose an inter-viewpoint aggregation framework that is able to fuse highly related high-quality training images, pushing the performance of cutting-edge NeRF models to entirely new levels and producing highly photo-realistic synthetic views.