 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC$^2$T: Captioning-Structure and LLM-Aligned Common-Sense Reward Learning for Traffic--Vehicle Coordination
Apr 10, 2026State-of-the-art (SOTA) urban traffic control increasingly employs Multi-Agent Reinforcement Learning (MARL) to coordinate Traffic Light Controllers (TLCs) and Connected Autonomous Vehicles (CAVs). However, the performance of these systems is fundamentally capped by their hand-crafted, myopic rewards (e.g., intersection pressure), which fail to capture high-level, human-centric goals like safety, flow stability, and comfort. To overcome this limitation, we introduce C2T, a novel framework that learns a common-sense coordination model from traffic-vehicle dynamics. C2T distills "common-sense" knowledge from a Large Language Model (LLM) into a learned intrinsic reward function. This new reward is then used to guide the coordination policy of a cooperative multi-intersection TLC MARL system on CityFlow-based multi-intersection benchmarks. Our framework significantly outperforms strong MARL baselines in traffic efficiency, safety, and an energy-related proxy. We further highlight C2T's flexibility in principle, allowing distinct "efficiency-focused" versus "safety-focused" policies by modifying the LLM prompt.
Jano: Adaptive Diffusion Generation with Early-stage Convergence Awareness
Feb 28, 2026Diffusion models have achieved remarkable success in generative AI, yet their computational efficiency remains a significant challenge, particularly for Diffusion Transformers (DiTs) requiring intensive full-attention computation. While existing acceleration approaches focus on content-agnostic uniform optimization strategies, we observe that different regions in generated content exhibit heterogeneous convergence patterns during the denoising process. We present Jano, a training-free framework that leverages this insight for efficient region-aware generation. Jano introduces an early-stage complexity recognition algorithm that accurately identifies regional convergence requirements within initial denoising steps, coupled with an adaptive token scheduling runtime that optimizes computational resource allocation. Through comprehensive evaluation on state-of-the-art models, Jano achieves substantial acceleration (average 2.0 times speedup, up to 2.4 times) while preserving generation quality. Our work challenges conventional uniform processing assumptions and provides a practical solution for accelerating large-scale content generation. The source code of our implementation is available at https://github.com/chen-yy20/Jano.
DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI
Feb 16, 2026Moving beyond the traditional paradigm of adapting internet-pretrained models to physical tasks, we present DM0, an Embodied-Native Vision-Language-Action (VLA) framework designed for Physical AI. Unlike approaches that treat physical grounding as a fine-tuning afterthought, DM0 unifies embodied manipulation and navigation by learning from heterogeneous data sources from the onset. Our methodology follows a comprehensive three-stage pipeline: Pretraining, Mid-Training, and Post-Training. First, we conduct large-scale unified pretraining on the Vision-Language Model (VLM) using diverse corpora--seamlessly integrating web text, autonomous driving scenarios, and embodied interaction logs-to jointly acquire semantic knowledge and physical priors. Subsequently, we build a flow-matching action expert atop the VLM. To reconcile high-level reasoning with low-level control, DM0 employs a hybrid training strategy: for embodied data, gradients from the action expert are not backpropagated to the VLM to preserve generalized representations, while the VLM remains trainable on non-embodied data. Furthermore, we introduce an Embodied Spatial Scaffolding strategy to construct spatial Chain-of-Thought (CoT) reasoning, effectively constraining the action solution space. Experiments on the RoboChallenge benchmark demonstrate that DM0 achieves state-of-the-art performance in both Specialist and Generalist settings on Table30.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
HARDMath2: A Benchmark for Applied Mathematics Built by Students as Part of a Graduate Class
May 17, 2025Large language models (LLMs) have shown remarkable progress in mathematical problem-solving, but evaluation has largely focused on problems that have exact analytical solutions or involve formal proofs, often overlooking approximation-based problems ubiquitous in applied science and engineering. To fill this gap, we build on prior work and present HARDMath2, a dataset of 211 original problems covering the core topics in an introductory graduate applied math class, including boundary-layer analysis, WKB methods, asymptotic solutions of nonlinear partial differential equations, and the asymptotics of oscillatory integrals. This dataset was designed and verified by the students and instructors of a core graduate applied mathematics course at Harvard. We build the dataset through a novel collaborative environment that challenges students to write and refine difficult problems consistent with the class syllabus, peer-validate solutions, test different models, and automatically check LLM-generated solutions against their own answers and numerical ground truths. Evaluation results show that leading frontier models still struggle with many of the problems in the dataset, highlighting a gap in the mathematical reasoning skills of current LLMs. Importantly, students identified strategies to create increasingly difficult problems by interacting with the models and exploiting common failure modes. This back-and-forth with the models not only resulted in a richer and more challenging benchmark but also led to qualitative improvements in the students' understanding of the course material, which is increasingly important as we enter an age where state-of-the-art language models can solve many challenging problems across a wide domain of fields.
Krysalis Hand: A Lightweight, High-Payload, 18-DoF Anthropomorphic End-Effector for Robotic Learning and Dexterous Manipulation
Apr 17, 2025
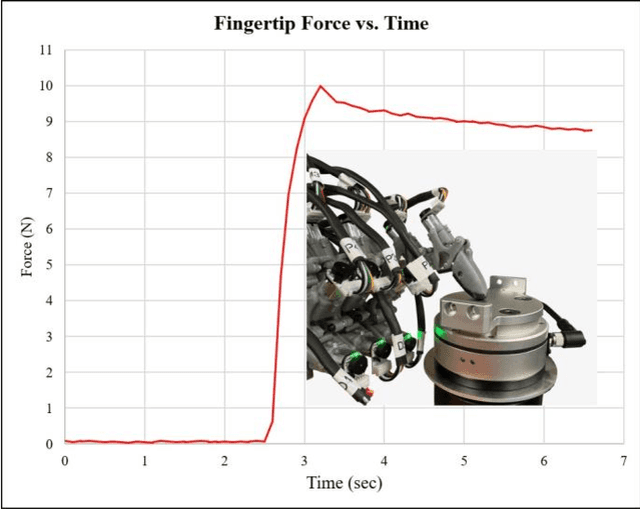


This paper presents the Krysalis Hand, a five-finger robotic end-effector that combines a lightweight design, high payload capacity, and a high number of degrees of freedom (DoF) to enable dexterous manipulation in both industrial and research settings. This design integrates the actuators within the hand while maintaining an anthropomorphic form. Each finger joint features a self-locking mechanism that allows the hand to sustain large external forces without active motor engagement. This approach shifts the payload limitation from the motor strength to the mechanical strength of the hand, allowing the use of smaller, more cost-effective motors. With 18 DoF and weighing only 790 grams, the Krysalis Hand delivers an active squeezing force of 10 N per finger and supports a passive payload capacity exceeding 10 lbs. These characteristics make Krysalis Hand one of the lightest, strongest, and most dexterous robotic end-effectors of its kind. Experimental evaluations validate its ability to perform intricate manipulation tasks and handle heavy payloads, underscoring its potential for industrial applications as well as academic research. All code related to the Krysalis Hand, including control and teleoperation, is available on the project GitHub repository: https://github.com/Soltanilara/Krysalis_Hand
Dynamic Attention and Bi-directional Fusion for Safety Helmet Wearing Detection
Nov 28, 2024Ensuring construction site safety requires accurate and real-time detection of workers' safety helmet use, despite challenges posed by cluttered environments, densely populated work areas, and hard-to-detect small or overlapping objects caused by building obstructions. This paper proposes a novel algorithm for safety helmet wearing detection, incorporating a dynamic attention within the detection head to enhance multi-scale perception. The mechanism combines feature-level attention for scale adaptation, spatial attention for spatial localization, and channel attention for task-specific insights, improving small object detection without additional computational overhead. Furthermore, a two-way fusion strategy enables bidirectional information flow, refining feature fusion through adaptive multi-scale weighting, and enhancing recognition of occluded targets. Experimental results demonstrate a 1.7% improvement in mAP@[.5:.95] compared to the best baseline while reducing GFLOPs by 11.9% on larger sizes. The proposed method surpasses existing models, providing an efficient and practical solution for real-world construction safety monitoring.
Efficient Diversity-based Experience Replay for Deep Reinforcement Learning
Oct 27, 2024



Deep Reinforcement Learning (DRL) has achieved remarkable success in solving complex decision-making problems by combining the representation capabilities of deep learning with the decision-making power of reinforcement learning. However, learning in sparse reward environments remains challenging due to insufficient feedback to guide the optimization of agents, especially in real-life environments with high-dimensional states. To tackle this issue, experience replay is commonly introduced to enhance learning efficiency through past experiences. Nonetheless, current methods of experience replay, whether based on uniform or prioritized sampling, frequently struggle with suboptimal learning efficiency and insufficient utilization of samples. This paper proposes a novel approach, diversity-based experience replay (DBER), which leverages the deterministic point process to prioritize diverse samples in state realizations. We conducted extensive experiments on Robotic Manipulation tasks in MuJoCo, Atari games, and realistic in-door environments in Habitat. The results show that our method not only significantly improves learning efficiency but also demonstrates superior performance in sparse reward environments with high-dimensional states, providing a simple yet effective solution for this field.
Enhancing LLM Agents for Code Generation with Possibility and Pass-rate Prioritized Experience Replay
Oct 16, 2024



Nowadays transformer-based Large Language Models (LLM) for code generation tasks usually apply sampling and filtering pipelines. Due to the sparse reward problem in code generation tasks caused by one-token incorrectness, transformer-based models will sample redundant programs till they find a correct one, leading to low efficiency. To overcome the challenge, we incorporate Experience Replay (ER) in the fine-tuning phase, where codes and programs produced are stored and will be replayed to give the LLM agent a chance to learn from past experiences. Based on the spirit of ER, we introduce a novel approach called BTP pipeline which consists of three phases: beam search sampling, testing phase, and prioritized experience replay phase. The approach makes use of failed programs collected by code models and replays programs with high Possibility and Pass-rate Prioritized value (P2Value) from the replay buffer to improve efficiency. P2Value comprehensively considers the possibility of transformers' output and pass rate and can make use of the redundant resources caused by the problem that most programs collected by LLMs fail to pass any tests. We empirically apply our approach in several LLMs, demonstrating that it enhances their performance in code generation tasks and surpasses existing baselines.