 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
A New Data-Driven Method to Identify Violent Facial Expression
Aug 16, 2023
Human Facial Expressions plays an important role in identifying human actions or intention. Facial expressions can represent any specific action of any person and the pattern of violent behavior of any person strongly depends on the geographic region. Here we have designed an automated system by using a Convolutional Neural Network which can detect whether a person has any intention to commit any crime or not. Here we proposed a new method that can identify criminal intentions or violent behavior of any person before executing crimes more efficiently by using very little data on facial expressions before executing a crime or any violent tasks. Instead of using image features which is a time-consuming and faulty method we used an automated feature selector Convolutional Neural Network model which can capture exact facial expressions for training and then can predict that target facial expressions more accurately. Here we used only the facial data of a specific geographic region which can represent the violent and before-crime before-crime facial patterns of the people of the whole region.
DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models
Sep 30, 2023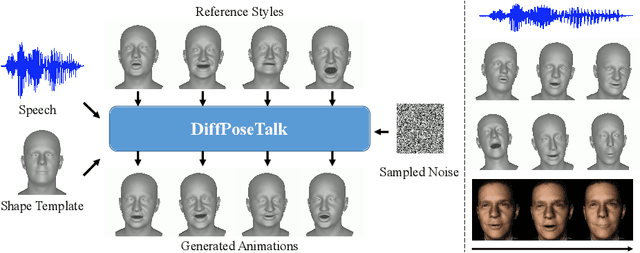
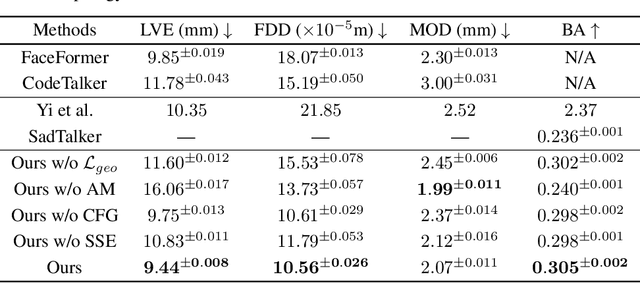
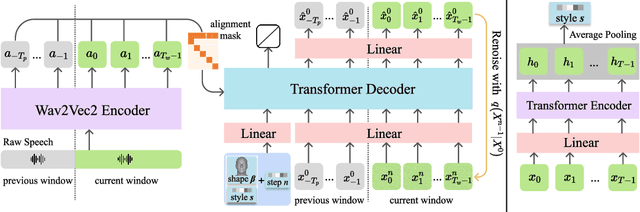
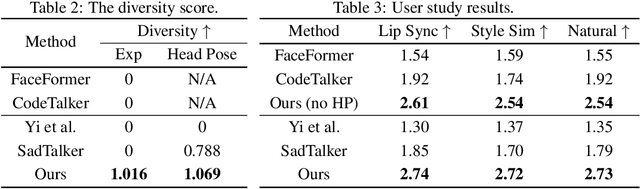
The generation of stylistic 3D facial animations driven by speech poses a significant challenge as it requires learning a many-to-many mapping between speech, style, and the corresponding natural facial motion. However, existing methods either employ a deterministic model for speech-to-motion mapping or encode the style using a one-hot encoding scheme. Notably, the one-hot encoding approach fails to capture the complexity of the style and thus limits generalization ability. In this paper, we propose DiffPoseTalk, a generative framework based on the diffusion model combined with a style encoder that extracts style embeddings from short reference videos. During inference, we employ classifier-free guidance to guide the generation process based on the speech and style. We extend this to include the generation of head poses, thereby enhancing user perception. Additionally, we address the shortage of scanned 3D talking face data by training our model on reconstructed 3DMM parameters from a high-quality, in-the-wild audio-visual dataset. Our extensive experiments and user study demonstrate that our approach outperforms state-of-the-art methods. The code and dataset will be made publicly available.
Learning Triangular Distribution in Visual World
Dec 04, 2023Convolution neural network is successful in pervasive vision tasks, including label distribution learning, which usually takes the form of learning an injection from the non-linear visual features to the well-defined labels. However, how the discrepancy between features is mapped to the label discrepancy is ambient, and its correctness is not guaranteed. To address these problems, we study the mathematical connection between feature and its label, presenting a general and simple framework for label distribution learning. We propose a so-called Triangular Distribution Transform (TDT) to build an injective function between feature and label, guaranteeing that any symmetric feature discrepancy linearly reflects the difference between labels. The proposed TDT can be used as a plug-in in mainstream backbone networks to address different label distribution learning tasks. Experiments on Facial Age Recognition, Illumination Chromaticity Estimation, and Aesthetics assessment show that TDT achieves on-par or better results than the prior arts.
HFORD: High-Fidelity and Occlusion-Robust De-identification for Face Privacy Protection
Nov 15, 2023With the popularity of smart devices and the development of computer vision technology, concerns about face privacy protection are growing. The face de-identification technique is a practical way to solve the identity protection problem. The existing facial de-identification methods have revealed several problems, including the impact on the realism of anonymized results when faced with occlusions and the inability to maintain identity-irrelevant details in anonymized results. We present a High-Fidelity and Occlusion-Robust De-identification (HFORD) method to deal with these issues. This approach can disentangle identities and attributes while preserving image-specific details such as background, facial features (e.g., wrinkles), and lighting, even in occluded scenes. To disentangle the latent codes in the GAN inversion space, we introduce an Identity Disentanglement Module (IDM). This module selects the latent codes that are closely related to the identity. It further separates the latent codes into identity-related codes and attribute-related codes, enabling the network to preserve attributes while only modifying the identity. To ensure the preservation of image details and enhance the network's robustness to occlusions, we propose an Attribute Retention Module (ARM). This module adaptively preserves identity-irrelevant details and facial occlusions and blends them into the generated results in a modulated manner. Extensive experiments show that our method has higher quality, better detail fidelity, and stronger occlusion robustness than other face de-identification methods.
Toward High Quality Facial Representation Learning
Sep 07, 2023
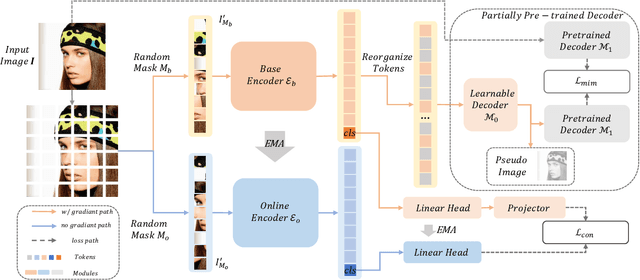

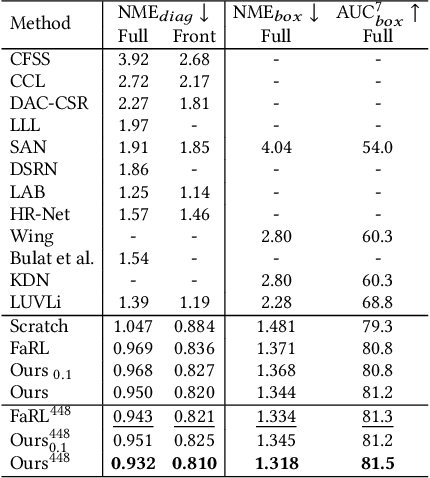
Face analysis tasks have a wide range of applications, but the universal facial representation has only been explored in a few works. In this paper, we explore high-performance pre-training methods to boost the face analysis tasks such as face alignment and face parsing. We propose a self-supervised pre-training framework, called \textbf{\it Mask Contrastive Face (MCF)}, with mask image modeling and a contrastive strategy specially adjusted for face domain tasks. To improve the facial representation quality, we use feature map of a pre-trained visual backbone as a supervision item and use a partially pre-trained decoder for mask image modeling. To handle the face identity during the pre-training stage, we further use random masks to build contrastive learning pairs. We conduct the pre-training on the LAION-FACE-cropped dataset, a variants of LAION-FACE 20M, which contains more than 20 million face images from Internet websites. For efficiency pre-training, we explore our framework pre-training performance on a small part of LAION-FACE-cropped and verify the superiority with different pre-training settings. Our model pre-trained with the full pre-training dataset outperforms the state-of-the-art methods on multiple downstream tasks. Our model achieves 0.932 NME$_{diag}$ for AFLW-19 face alignment and 93.96 F1 score for LaPa face parsing. Code is available at https://github.com/nomewang/MCF.
DiffSLVA: Harnessing Diffusion Models for Sign Language Video Anonymization
Nov 27, 2023Since American Sign Language (ASL) has no standard written form, Deaf signers frequently share videos in order to communicate in their native language. However, since both hands and face convey critical linguistic information in signed languages, sign language videos cannot preserve signer privacy. While signers have expressed interest, for a variety of applications, in sign language video anonymization that would effectively preserve linguistic content, attempts to develop such technology have had limited success, given the complexity of hand movements and facial expressions. Existing approaches rely predominantly on precise pose estimations of the signer in video footage and often require sign language video datasets for training. These requirements prevent them from processing videos 'in the wild,' in part because of the limited diversity present in current sign language video datasets. To address these limitations, our research introduces DiffSLVA, a novel methodology that utilizes pre-trained large-scale diffusion models for zero-shot text-guided sign language video anonymization. We incorporate ControlNet, which leverages low-level image features such as HED (Holistically-Nested Edge Detection) edges, to circumvent the need for pose estimation. Additionally, we develop a specialized module dedicated to capturing facial expressions, which are critical for conveying essential linguistic information in signed languages. We then combine the above methods to achieve anonymization that better preserves the essential linguistic content of the original signer. This innovative methodology makes possible, for the first time, sign language video anonymization that could be used for real-world applications, which would offer significant benefits to the Deaf and Hard-of-Hearing communities. We demonstrate the effectiveness of our approach with a series of signer anonymization experiments.
Versatile Face Animator: Driving Arbitrary 3D Facial Avatar in RGBD Space
Aug 11, 2023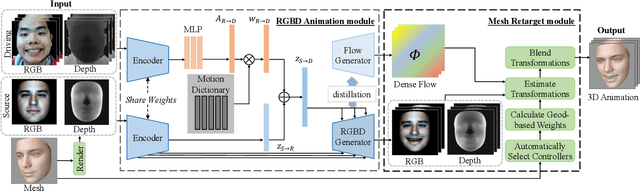

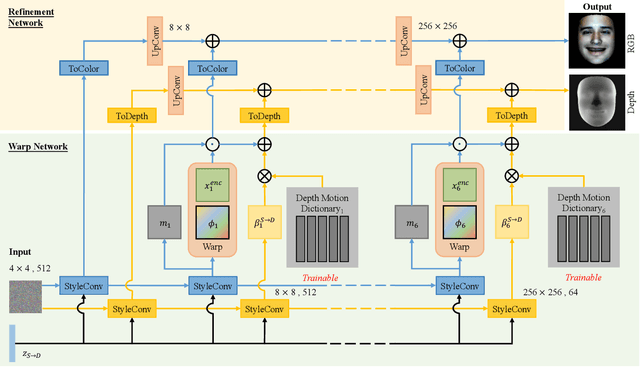
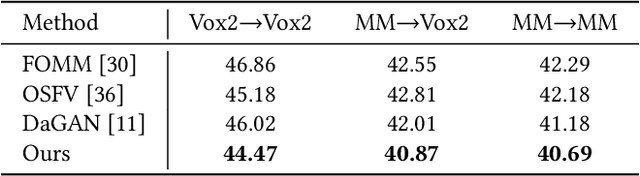
Creating realistic 3D facial animation is crucial for various applications in the movie production and gaming industry, especially with the burgeoning demand in the metaverse. However, prevalent methods such as blendshape-based approaches and facial rigging techniques are time-consuming, labor-intensive, and lack standardized configurations, making facial animation production challenging and costly. In this paper, we propose a novel self-supervised framework, Versatile Face Animator, which combines facial motion capture with motion retargeting in an end-to-end manner, eliminating the need for blendshapes or rigs. Our method has the following two main characteristics: 1) we propose an RGBD animation module to learn facial motion from raw RGBD videos by hierarchical motion dictionaries and animate RGBD images rendered from 3D facial mesh coarse-to-fine, enabling facial animation on arbitrary 3D characters regardless of their topology, textures, blendshapes, and rigs; and 2) we introduce a mesh retarget module to utilize RGBD animation to create 3D facial animation by manipulating facial mesh with controller transformations, which are estimated from dense optical flow fields and blended together with geodesic-distance-based weights. Comprehensive experiments demonstrate the effectiveness of our proposed framework in generating impressive 3D facial animation results, highlighting its potential as a promising solution for the cost-effective and efficient production of facial animation in the metaverse.
FaceStudio: Put Your Face Everywhere in Seconds
Dec 06, 2023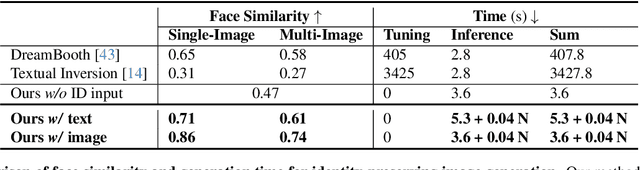
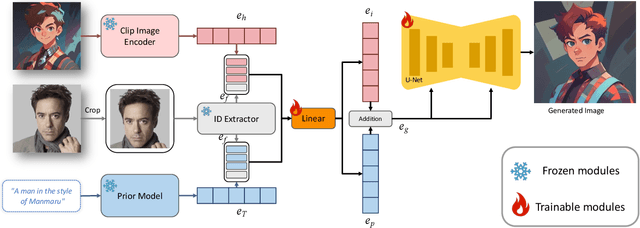
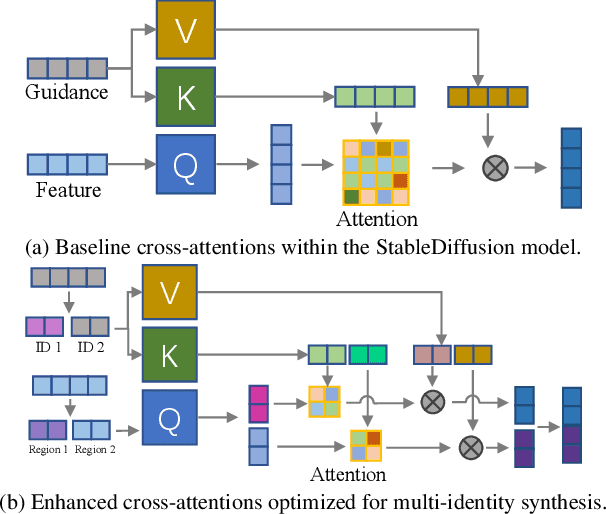

This study investigates identity-preserving image synthesis, an intriguing task in image generation that seeks to maintain a subject's identity while adding a personalized, stylistic touch. Traditional methods, such as Textual Inversion and DreamBooth, have made strides in custom image creation, but they come with significant drawbacks. These include the need for extensive resources and time for fine-tuning, as well as the requirement for multiple reference images. To overcome these challenges, our research introduces a novel approach to identity-preserving synthesis, with a particular focus on human images. Our model leverages a direct feed-forward mechanism, circumventing the need for intensive fine-tuning, thereby facilitating quick and efficient image generation. Central to our innovation is a hybrid guidance framework, which combines stylized images, facial images, and textual prompts to guide the image generation process. This unique combination enables our model to produce a variety of applications, such as artistic portraits and identity-blended images. Our experimental results, including both qualitative and quantitative evaluations, demonstrate the superiority of our method over existing baseline models and previous works, particularly in its remarkable efficiency and ability to preserve the subject's identity with high fidelity.
Prompting Visual-Language Models for Dynamic Facial Expression Recognition
Aug 25, 2023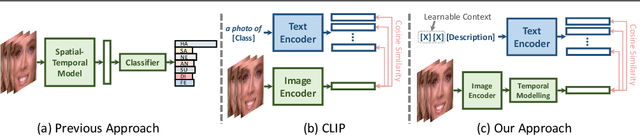
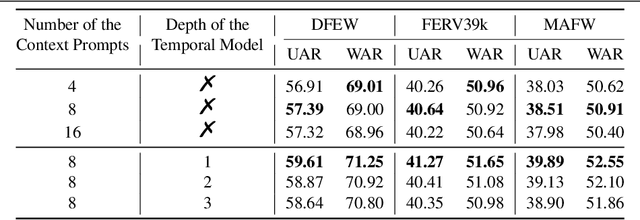
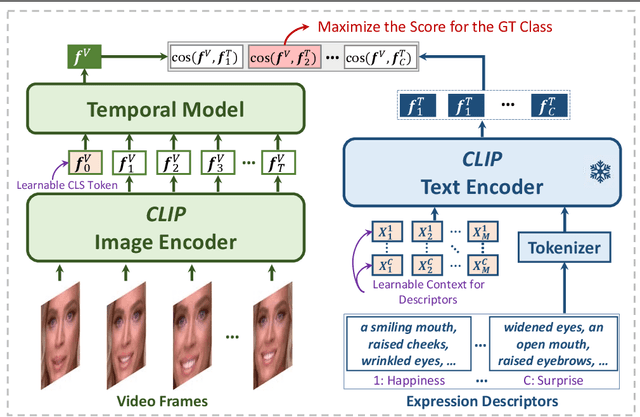
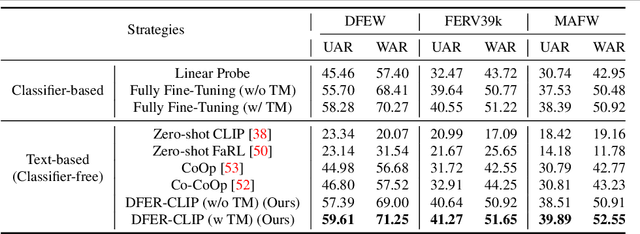
This paper presents a novel visual-language model called DFER-CLIP, which is based on the CLIP model and designed for in-the-wild Dynamic Facial Expression Recognition (DFER). Specifically, the proposed DFER-CLIP consists of a visual part and a textual part. For the visual part, based on the CLIP image encoder, a temporal model consisting of several Transformer encoders is introduced for extracting temporal facial expression features, and the final feature embedding is obtained as a learnable "class" token. For the textual part, we use as inputs textual descriptions of the facial behaviour that is related to the classes (facial expressions) that we are interested in recognising -- those descriptions are generated using large language models, like ChatGPT. This, in contrast to works that use only the class names and more accurately captures the relationship between them. Alongside the textual description, we introduce a learnable token which helps the model learn relevant context information for each expression during training. Extensive experiments demonstrate the effectiveness of the proposed method and show that our DFER-CLIP also achieves state-of-the-art results compared with the current supervised DFER methods on the DFEW, FERV39k, and MAFW benchmarks. Code is publicly available at https://github.com/zengqunzhao/DFER-CLIP.
VividTalk: One-Shot Audio-Driven Talking Head Generation Based on 3D Hybrid Prior
Dec 07, 2023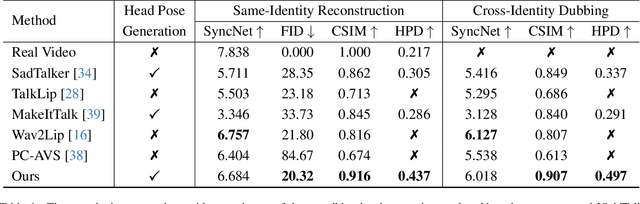
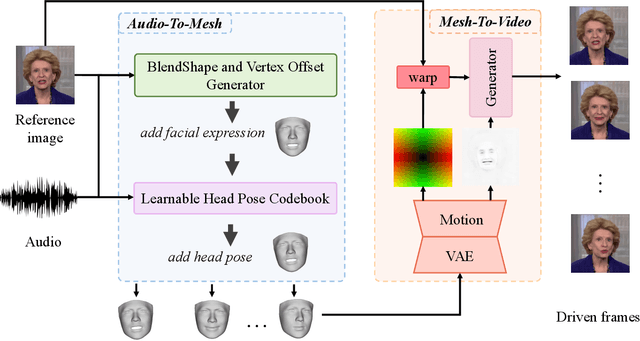
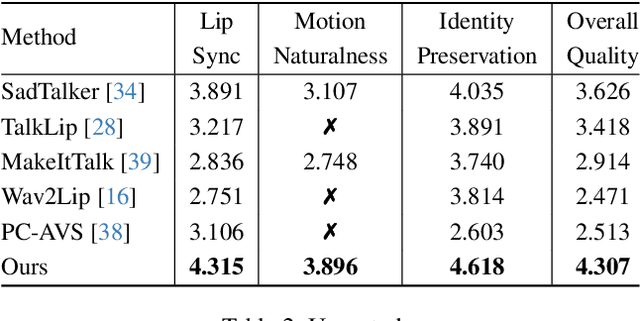
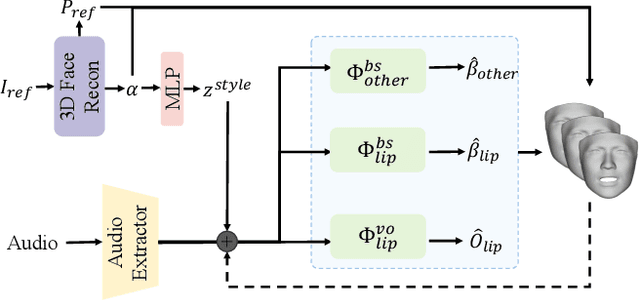
Audio-driven talking head generation has drawn much attention in recent years, and many efforts have been made in lip-sync, expressive facial expressions, natural head pose generation, and high video quality. However, no model has yet led or tied on all these metrics due to the one-to-many mapping between audio and motion. In this paper, we propose VividTalk, a two-stage generic framework that supports generating high-visual quality talking head videos with all the above properties. Specifically, in the first stage, we map the audio to mesh by learning two motions, including non-rigid expression motion and rigid head motion. For expression motion, both blendshape and vertex are adopted as the intermediate representation to maximize the representation ability of the model. For natural head motion, a novel learnable head pose codebook with a two-phase training mechanism is proposed. In the second stage, we proposed a dual branch motion-vae and a generator to transform the meshes into dense motion and synthesize high-quality video frame-by-frame. Extensive experiments show that the proposed VividTalk can generate high-visual quality talking head videos with lip-sync and realistic enhanced by a large margin, and outperforms previous state-of-the-art works in objective and subjective comparisons.