 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignX: The Foundation Model for Sign Recognition
Apr 22, 2025The complexity of sign language data processing brings many challenges. The current approach to recognition of ASL signs aims to translate RGB sign language videos through pose information into English-based ID glosses, which serve to uniquely identify ASL signs. Note that there is no shared convention for assigning such glosses to ASL signs, so it is essential that the same glossing conventions are used for all of the data in the datasets that are employed. This paper proposes SignX, a foundation model framework for sign recognition. It is a concise yet powerful framework applicable to multiple human activity recognition scenarios. First, we developed a Pose2Gloss component based on an inverse diffusion model, which contains a multi-track pose fusion layer that unifies five of the most powerful pose information sources--SMPLer-X, DWPose, Mediapipe, PrimeDepth, and Sapiens Segmentation--into a single latent pose representation. Second, we trained a Video2Pose module based on ViT that can directly convert raw video into signer pose representation. Through this 2-stage training framework, we enable sign language recognition models to be compatible with existing pose formats, laying the foundation for the common pose estimation necessary for sign recognition. Experimental results show that SignX can recognize signs from sign language video, producing predicted gloss representations with greater accuracy than has been reported in prior work.
New Capability to Look Up an ASL Sign from a Video Example
Jul 18, 2024



Looking up an unknown sign in an ASL dictionary can be difficult. Most ASL dictionaries are organized based on English glosses, despite the fact that (1) there is no convention for assigning English-based glosses to ASL signs; and (2) there is no 1-1 correspondence between ASL signs and English words. Furthermore, what if the user does not know either the meaning of the target sign or its possible English translation(s)? Some ASL dictionaries enable searching through specification of articulatory properties, such as handshapes, locations, movement properties, etc. However, this is a cumbersome process and does not always result in successful lookup. Here we describe a new system, publicly shared on the Web, to enable lookup of a video of an ASL sign (e.g., a webcam recording or a clip from a continuous signing video). The user submits a video for analysis and is presented with the five most likely sign matches, in decreasing order of likelihood, so that the user can confirm the selection and then be taken to our ASLLRP Sign Bank entry for that sign. Furthermore, this video lookup is also integrated into our newest version of SignStream(R) software to facilitate linguistic annotation of ASL video data, enabling the user to directly look up a sign in the video being annotated, and, upon confirmation of the match, to directly enter into the annotation the gloss and features of that sign, greatly increasing the efficiency and consistency of linguistic annotations of ASL video data.
DiffSLVA: Harnessing Diffusion Models for Sign Language Video Anonymization
Nov 27, 2023



Since American Sign Language (ASL) has no standard written form, Deaf signers frequently share videos in order to communicate in their native language. However, since both hands and face convey critical linguistic information in signed languages, sign language videos cannot preserve signer privacy. While signers have expressed interest, for a variety of applications, in sign language video anonymization that would effectively preserve linguistic content, attempts to develop such technology have had limited success, given the complexity of hand movements and facial expressions. Existing approaches rely predominantly on precise pose estimations of the signer in video footage and often require sign language video datasets for training. These requirements prevent them from processing videos 'in the wild,' in part because of the limited diversity present in current sign language video datasets. To address these limitations, our research introduces DiffSLVA, a novel methodology that utilizes pre-trained large-scale diffusion models for zero-shot text-guided sign language video anonymization. We incorporate ControlNet, which leverages low-level image features such as HED (Holistically-Nested Edge Detection) edges, to circumvent the need for pose estimation. Additionally, we develop a specialized module dedicated to capturing facial expressions, which are critical for conveying essential linguistic information in signed languages. We then combine the above methods to achieve anonymization that better preserves the essential linguistic content of the original signer. This innovative methodology makes possible, for the first time, sign language video anonymization that could be used for real-world applications, which would offer significant benefits to the Deaf and Hard-of-Hearing communities. We demonstrate the effectiveness of our approach with a series of signer anonymization experiments.
Challenges for Linguistically-Driven Computer-Based Sign Recognition from Continuous Signing for American Sign Language
Nov 01, 2023



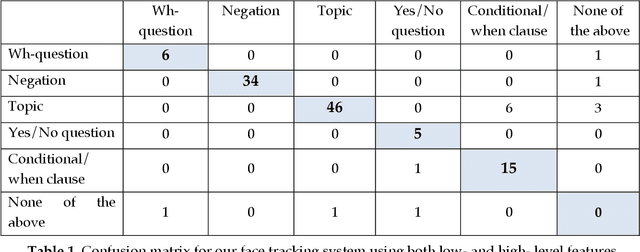
There have been recent advances in computer-based recognition of isolated, citation-form signs from video. There are many challenges for such a task, not least the naturally occurring inter- and intra- signer synchronic variation in sign production, including sociolinguistic variation in the realization of certain signs. However, there are several significant factors that make recognition of signs from continuous signing an even more difficult problem. This article presents an overview of such challenges, based in part on findings from a large corpus of linguistically annotated video data for American Sign Language (ASL). Some linguistic regularities in the structure of signs that can boost handshape and sign recognition are also discussed.
ASL Video Corpora & Sign Bank: Resources Available through the American Sign Language Linguistic Research Project (ASLLRP)
Jan 19, 2022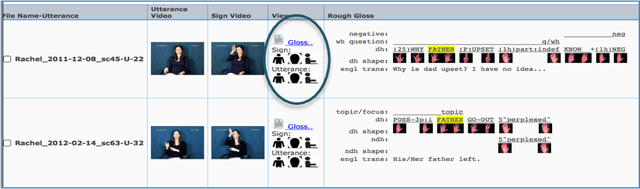
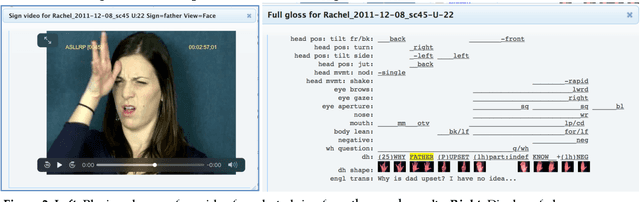
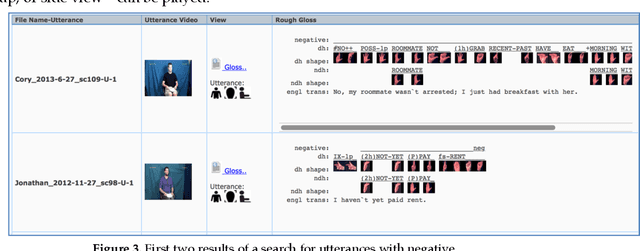
The American Sign Language Linguistic Research Project (ASLLRP) provides Internet access to high-quality ASL video data, generally including front and side views and a close-up of the face. The manual and non-manual components of the signing have been linguistically annotated using SignStream(R). The recently expanded video corpora can be browsed and searched through the Data Access Interface (DAI 2) we have designed; it is possible to carry out complex searches. The data from our corpora can also be downloaded; annotations are available in an XML export format. We have also developed the ASLLRP Sign Bank, which contains almost 6,000 sign entries for lexical signs, with distinct English-based glosses, with a total of 41,830 examples of lexical signs (in addition to about 300 gestures, over 1,000 fingerspelled signs, and 475 classifier examples). The Sign Bank is likewise accessible and searchable on the Internet; it can also be accessed from within SignStream(R) (software to facilitate linguistic annotation and analysis of visual language data) to make annotations more accurate and efficient. Here we describe the available resources. These data have been used for many types of research in linguistics and in computer-based sign language recognition from video; examples of such research are provided in the latter part of this article.