 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowAct-R1: Towards Interactive Humanoid Video Generation
Jan 15, 2026Interactive humanoid video generation aims to synthesize lifelike visual agents that can engage with humans through continuous and responsive video. Despite recent advances in video synthesis, existing methods often grapple with the trade-off between high-fidelity synthesis and real-time interaction requirements. In this paper, we propose FlowAct-R1, a framework specifically designed for real-time interactive humanoid video generation. Built upon a MMDiT architecture, FlowAct-R1 enables the streaming synthesis of video with arbitrary durations while maintaining low-latency responsiveness. We introduce a chunkwise diffusion forcing strategy, complemented by a novel self-forcing variant, to alleviate error accumulation and ensure long-term temporal consistency during continuous interaction. By leveraging efficient distillation and system-level optimizations, our framework achieves a stable 25fps at 480p resolution with a time-to-first-frame (TTFF) of only around 1.5 seconds. The proposed method provides holistic and fine-grained full-body control, enabling the agent to transition naturally between diverse behavioral states in interactive scenarios. Experimental results demonstrate that FlowAct-R1 achieves exceptional behavioral vividness and perceptual realism, while maintaining robust generalization across diverse character styles.
DreamActor-M1: Holistic, Expressive and Robust Human Image Animation with Hybrid Guidance
Apr 03, 2025While recent image-based human animation methods achieve realistic body and facial motion synthesis, critical gaps remain in fine-grained holistic controllability, multi-scale adaptability, and long-term temporal coherence, which leads to their lower expressiveness and robustness. We propose a diffusion transformer (DiT) based framework, DreamActor-M1, with hybrid guidance to overcome these limitations. For motion guidance, our hybrid control signals that integrate implicit facial representations, 3D head spheres, and 3D body skeletons achieve robust control of facial expressions and body movements, while producing expressive and identity-preserving animations. For scale adaptation, to handle various body poses and image scales ranging from portraits to full-body views, we employ a progressive training strategy using data with varying resolutions and scales. For appearance guidance, we integrate motion patterns from sequential frames with complementary visual references, ensuring long-term temporal coherence for unseen regions during complex movements. Experiments demonstrate that our method outperforms the state-of-the-art works, delivering expressive results for portraits, upper-body, and full-body generation with robust long-term consistency. Project Page: https://grisoon.github.io/DreamActor-M1/.
INFP: Audio-Driven Interactive Head Generation in Dyadic Conversations
Dec 05, 2024Imagine having a conversation with a socially intelligent agent. It can attentively listen to your words and offer visual and linguistic feedback promptly. This seamless interaction allows for multiple rounds of conversation to flow smoothly and naturally. In pursuit of actualizing it, we propose INFP, a novel audio-driven head generation framework for dyadic interaction. Unlike previous head generation works that only focus on single-sided communication, or require manual role assignment and explicit role switching, our model drives the agent portrait dynamically alternates between speaking and listening state, guided by the input dyadic audio. Specifically, INFP comprises a Motion-Based Head Imitation stage and an Audio-Guided Motion Generation stage. The first stage learns to project facial communicative behaviors from real-life conversation videos into a low-dimensional motion latent space, and use the motion latent codes to animate a static image. The second stage learns the mapping from the input dyadic audio to motion latent codes through denoising, leading to the audio-driven head generation in interactive scenarios. To facilitate this line of research, we introduce DyConv, a large scale dataset of rich dyadic conversations collected from the Internet. Extensive experiments and visualizations demonstrate superior performance and effectiveness of our method. Project Page: https://grisoon.github.io/INFP/.
PersonaTalk: Bring Attention to Your Persona in Visual Dubbing
Sep 09, 2024



For audio-driven visual dubbing, it remains a considerable challenge to uphold and highlight speaker's persona while synthesizing accurate lip synchronization. Existing methods fall short of capturing speaker's unique speaking style or preserving facial details. In this paper, we present PersonaTalk, an attention-based two-stage framework, including geometry construction and face rendering, for high-fidelity and personalized visual dubbing. In the first stage, we propose a style-aware audio encoding module that injects speaking style into audio features through a cross-attention layer. The stylized audio features are then used to drive speaker's template geometry to obtain lip-synced geometries. In the second stage, a dual-attention face renderer is introduced to render textures for the target geometries. It consists of two parallel cross-attention layers, namely Lip-Attention and Face-Attention, which respectively sample textures from different reference frames to render the entire face. With our innovative design, intricate facial details can be well preserved. Comprehensive experiments and user studies demonstrate our advantages over other state-of-the-art methods in terms of visual quality, lip-sync accuracy and persona preservation. Furthermore, as a person-generic framework, PersonaTalk can achieve competitive performance as state-of-the-art person-specific methods. Project Page: https://grisoon.github.io/PersonaTalk/.
MaTe3D: Mask-guided Text-based 3D-aware Portrait Editing
Dec 12, 2023



Recently, 3D-aware face editing has witnessed remarkable progress. Although current approaches successfully perform mask-guided or text-based editing, these properties have not been combined into a single method. To address this limitation, we propose \textbf{MaTe3D}: mask-guided text-based 3D-aware portrait editing. First, we propose a new SDF-based 3D generator. To better perform masked-based editing (mainly happening in local areas), we propose SDF and density consistency losses, aiming to effectively model both the global and local representations jointly. Second, we introduce an inference-optimized method. We introduce two techniques based on the SDS (Score Distillation Sampling), including a blending SDS and a conditional SDS. The former aims to overcome the mismatch problem between geometry and appearance, ultimately harming fidelity. The conditional SDS contributes to further producing satisfactory and stable results. Additionally, we create CatMask-HQ dataset, a large-scale high-resolution cat face annotations. We perform experiments on both the FFHQ and CatMask-HQ datasets to demonstrate the effectiveness of the proposed method. Our method generates faithfully a edited 3D-aware face image given a modified mask and a text prompt. Our code and models will be publicly released.
VividTalk: One-Shot Audio-Driven Talking Head Generation Based on 3D Hybrid Prior
Dec 07, 2023Audio-driven talking head generation has drawn much attention in recent years, and many efforts have been made in lip-sync, expressive facial expressions, natural head pose generation, and high video quality. However, no model has yet led or tied on all these metrics due to the one-to-many mapping between audio and motion. In this paper, we propose VividTalk, a two-stage generic framework that supports generating high-visual quality talking head videos with all the above properties. Specifically, in the first stage, we map the audio to mesh by learning two motions, including non-rigid expression motion and rigid head motion. For expression motion, both blendshape and vertex are adopted as the intermediate representation to maximize the representation ability of the model. For natural head motion, a novel learnable head pose codebook with a two-phase training mechanism is proposed. In the second stage, we proposed a dual branch motion-vae and a generator to transform the meshes into dense motion and synthesize high-quality video frame-by-frame. Extensive experiments show that the proposed VividTalk can generate high-visual quality talking head videos with lip-sync and realistic enhanced by a large margin, and outperforms previous state-of-the-art works in objective and subjective comparisons.
One-Shot High-Fidelity Talking-Head Synthesis with Deformable Neural Radiance Field
Apr 11, 2023Talking head generation aims to generate faces that maintain the identity information of the source image and imitate the motion of the driving image. Most pioneering methods rely primarily on 2D representations and thus will inevitably suffer from face distortion when large head rotations are encountered. Recent works instead employ explicit 3D structural representations or implicit neural rendering to improve performance under large pose changes. Nevertheless, the fidelity of identity and expression is not so desirable, especially for novel-view synthesis. In this paper, we propose HiDe-NeRF, which achieves high-fidelity and free-view talking-head synthesis. Drawing on the recently proposed Deformable Neural Radiance Fields, HiDe-NeRF represents the 3D dynamic scene into a canonical appearance field and an implicit deformation field, where the former comprises the canonical source face and the latter models the driving pose and expression. In particular, we improve fidelity from two aspects: (i) to enhance identity expressiveness, we design a generalized appearance module that leverages multi-scale volume features to preserve face shape and details; (ii) to improve expression preciseness, we propose a lightweight deformation module that explicitly decouples the pose and expression to enable precise expression modeling. Extensive experiments demonstrate that our proposed approach can generate better results than previous works. Project page: https://www.waytron.net/hidenerf/
Depth-Aware Generative Adversarial Network for Talking Head Video Generation
Mar 15, 2022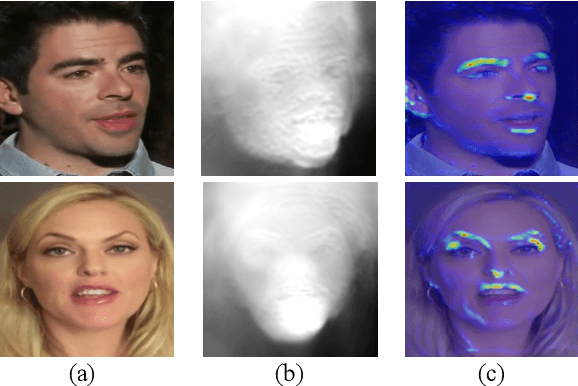
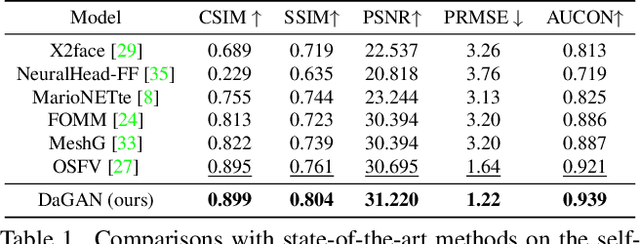
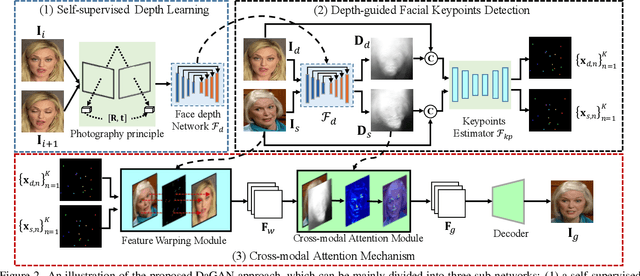
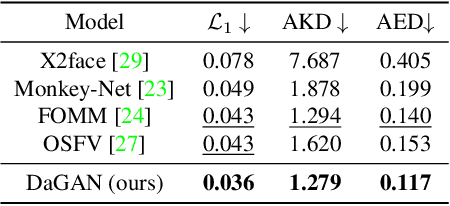
Talking head video generation aims to produce a synthetic human face video that contains the identity and pose information respectively from a given source image and a driving video.Existing works for this task heavily rely on 2D representations (e.g. appearance and motion) learned from the input images. However, dense 3D facial geometry (e.g. pixel-wise depth) is extremely important for this task as it is particularly beneficial for us to essentially generate accurate 3D face structures and distinguish noisy information from the possibly cluttered background. Nevertheless, dense 3D geometry annotations are prohibitively costly for videos and are typically not available for this video generation task. In this paper, we first introduce a self-supervised geometry learning method to automatically recover the dense 3D geometry (i.e.depth) from the face videos without the requirement of any expensive 3D annotation data. Based on the learned dense depth maps, we further propose to leverage them to estimate sparse facial keypoints that capture the critical movement of the human head. In a more dense way, the depth is also utilized to learn 3D-aware cross-modal (i.e. appearance and depth) attention to guide the generation of motion fields for warping source image representations. All these contributions compose a novel depth-aware generative adversarial network (DaGAN) for talking head generation. Extensive experiments conducted demonstrate that our proposed method can generate highly realistic faces, and achieve significant results on the unseen human faces.