 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHMS-BERT: Hybrid Multi-Task Self-Training for Multilingual and Multi-Label Cyberbullying Detection
Mar 13, 2026Cyberbullying on social media is inherently multilingual and multi-faceted, where abusive behaviors often overlap across multiple categories. Existing methods are commonly limited by monolingual assumptions or single-task formulations, which restrict their effectiveness in realistic multilingual and multi-label scenarios. In this paper, we propose HMS-BERT, a hybrid multi-task self-training framework for multilingual and multi-label cyberbullying detection. Built upon a pretrained multilingual BERT backbone, HMS-BERT integrates contextual representations with handcrafted linguistic features and jointly optimizes a fine-grained multi-label abuse classification task and a three-class main classification task. To address labeled data scarcity in low-resource languages, an iterative self-training strategy with confidence-based pseudo-labeling is introduced to facilitate cross-lingual knowledge transfer. Experiments on four public datasets demonstrate that HMS-BERT achieves strong performance, attaining a macro F1-score of up to 0.9847 on the multi-label task and an accuracy of 0.6775 on the main classification task. Ablation studies further verify the effectiveness of the proposed components.
MMformer with Adaptive Transferable Attention: Advancing Multivariate Time Series Forecasting for Environmental Applications
Apr 18, 2025



Environmental crisis remains a global challenge that affects public health and environmental quality. Despite extensive research, accurately forecasting environmental change trends to inform targeted policies and assess prediction efficiency remains elusive. Conventional methods for multivariate time series (MTS) analysis often fail to capture the complex dynamics of environmental change. To address this, we introduce an innovative meta-learning MTS model, MMformer with Adaptive Transferable Multi-head Attention (ATMA), which combines self-attention and meta-learning for enhanced MTS forecasting. Specifically, MMformer is used to model and predict the time series of seven air quality indicators across 331 cities in China from January 2018 to June 2021 and the time series of precipitation and temperature at 2415 monitoring sites during the summer (276 days) from 2012 to 2014, validating the network's ability to perform and forecast MTS data successfully. Experimental results demonstrate that in these datasets, the MMformer model reaching SOTA outperforms iTransformer, Transformer, and the widely used traditional time series prediction algorithm SARIMAX in the prediction of MTS, reducing by 50\% in MSE, 20\% in MAE as compared to others in air quality datasets, reducing by 20\% in MAPE except SARIMAX. Compared with Transformer and SARIMAX in the climate datasets, MSE, MAE, and MAPE are decreased by 30\%, and there is an improvement compared to iTransformer. This approach represents a significant advance in our ability to forecast and respond to dynamic environmental quality challenges in diverse urban and rural environments. Its predictive capabilities provide valuable public health and environmental quality information, informing targeted interventions.
A New Data-Driven Method to Identify Violent Facial Expression
Aug 16, 2023Human Facial Expressions plays an important role in identifying human actions or intention. Facial expressions can represent any specific action of any person and the pattern of violent behavior of any person strongly depends on the geographic region. Here we have designed an automated system by using a Convolutional Neural Network which can detect whether a person has any intention to commit any crime or not. Here we proposed a new method that can identify criminal intentions or violent behavior of any person before executing crimes more efficiently by using very little data on facial expressions before executing a crime or any violent tasks. Instead of using image features which is a time-consuming and faulty method we used an automated feature selector Convolutional Neural Network model which can capture exact facial expressions for training and then can predict that target facial expressions more accurately. Here we used only the facial data of a specific geographic region which can represent the violent and before-crime before-crime facial patterns of the people of the whole region.
Using Chinese Text Processing Technique for the Processing of Sanskrit Based Indian Languages: Maximum Resource Utilization and Maximum Compatibility
Sep 27, 1995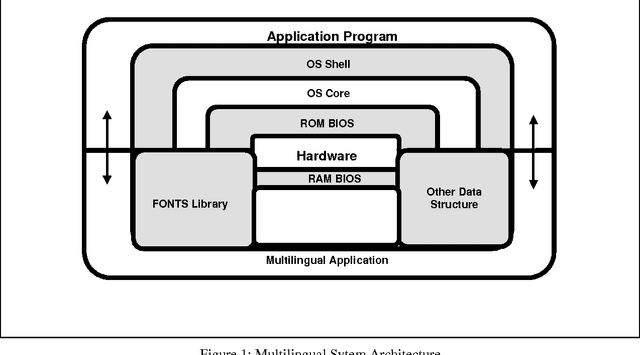
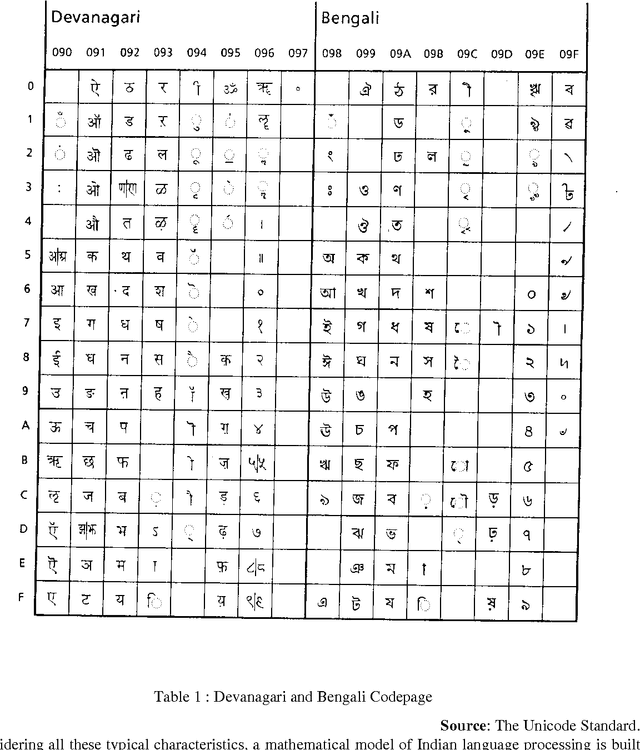
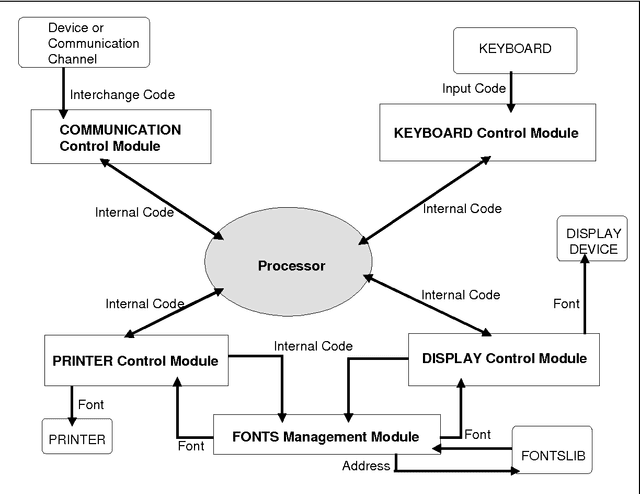
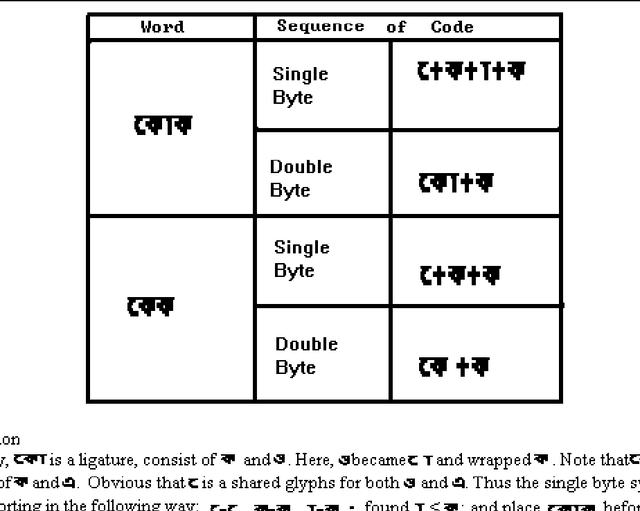
Chinese text processing systems are using Double Byte Coding , while almost all existing Sanskrit Based Indian Languages have been using Single Byte coding for text processing. Through observation, Chinese Information Processing Technique has already achieved great technical development both in east and west. In contrast,Indian Languages are being processed by computer, more or less, for word processing purpose. This paper mainly emphasizes the method of processing Indian languages from a Computational Linguistic point of view. An overall design method is illustrated in this paper.This method concentrated on maximum resource utilization and compatibility: the ultimate goal is to have a Multiplatform Multilingual System. Keywords Text Procrssing, Multilingual Text Processing, Chinese Language Processing, Indian Language Processing, Character Coding.