 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemGS: Feed-Forward Semantic 3D Gaussian Splatting from Sparse Views for Generalizable Scene Understanding
Mar 03, 2026Semantic understanding of 3D scenes is essential for robots to operate effectively and safely in complex environments. Existing methods for semantic scene reconstruction and semantic-aware novel view synthesis often rely on dense multi-view inputs and require scene-specific optimization, limiting their practicality and scalability in real-world applications. To address these challenges, we propose SemGS, a feed-forward framework for reconstructing generalizable semantic fields from sparse image inputs. SemGS uses a dual-branch architecture to extract color and semantic features, where the two branches share shallow CNN layers, allowing semantic reasoning to leverage textural and structural cues in color appearance. We also incorporate a camera-aware attention mechanism into the feature extractor to explicitly model geometric relationships between camera viewpoints. The extracted features are decoded into dual-Gaussians that share geometric consistency while preserving branch-specific attributes, and further rasterized to synthesize semantic maps under novel viewpoints. Additionally, we introduce a regional smoothness loss to enhance semantic coherence. Experiments show that SemGS achieves state-of-the-art performance on benchmark datasets, while providing rapid inference and strong generalization capabilities across diverse synthetic and real-world scenarios.
Learn the Ropes, Then Trust the Wins: Self-imitation with Progressive Exploration for Agentic Reinforcement Learning
Sep 26, 2025
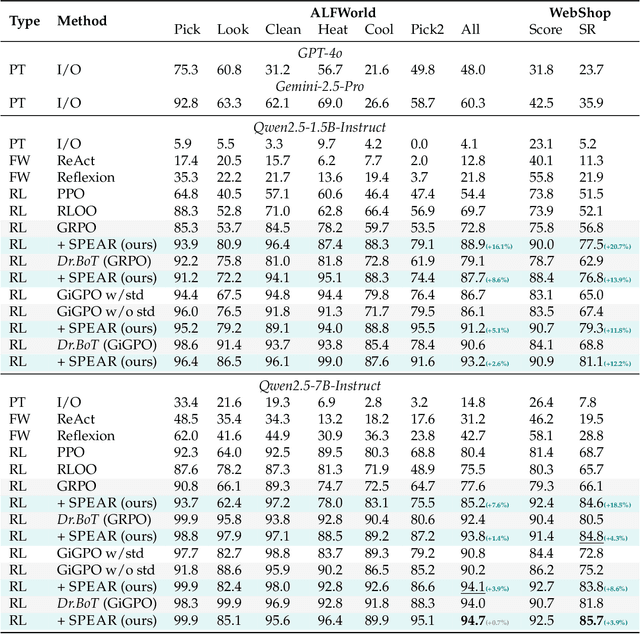
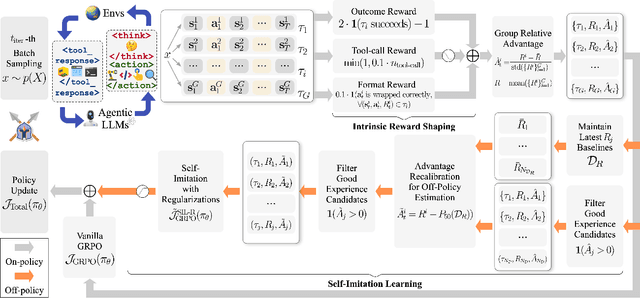
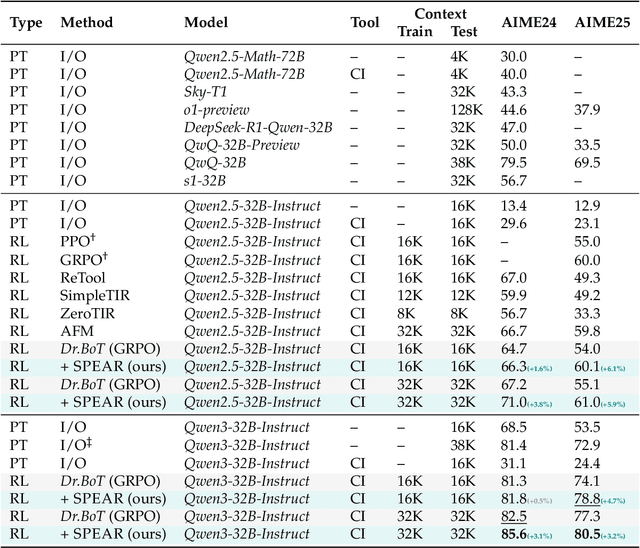
Reinforcement learning (RL) is the dominant paradigm for sharpening strategic tool use capabilities of LLMs on long-horizon, sparsely-rewarded agent tasks, yet it faces a fundamental challenge of exploration-exploitation trade-off. Existing studies stimulate exploration through the lens of policy entropy, but such mechanical entropy maximization is prone to RL training instability due to the multi-turn distribution shifting. In this paper, we target the progressive exploration-exploitation balance under the guidance of the agent own experiences without succumbing to either entropy collapsing or runaway divergence. We propose SPEAR, a curriculum-based self-imitation learning (SIL) recipe for training agentic LLMs. It extends the vanilla SIL framework, where a replay buffer stores self-generated promising trajectories for off-policy update, by gradually steering the policy evolution within a well-balanced range of entropy across stages. Specifically, our approach incorporates a curriculum to manage the exploration process, utilizing intrinsic rewards to foster skill-level exploration and facilitating action-level exploration through SIL. At first, the auxiliary tool call reward plays a critical role in the accumulation of tool-use skills, enabling broad exposure to the unfamiliar distributions of the environment feedback with an upward entropy trend. As training progresses, self-imitation gets strengthened to exploit existing successful patterns from replayed experiences for comparative action-level exploration, accelerating solution iteration without unbounded entropy growth. To further stabilize training, we recalibrate the advantages of experiences in the replay buffer to address the potential policy drift. Reugularizations such as the clipping of tokens with high covariance between probability and advantage are introduced to the trajectory-level entropy control to curb over-confidence.
Tailor: An Integrated Text-Driven CG-Ready Human and Garment Generation System
Mar 15, 2025Creating detailed 3D human avatars with garments typically requires specialized expertise and labor-intensive processes. Although recent advances in generative AI have enabled text-to-3D human/clothing generation, current methods fall short in offering accessible, integrated pipelines for producing ready-to-use clothed avatars. To solve this, we introduce Tailor, an integrated text-to-avatar system that generates high-fidelity, customizable 3D humans with simulation-ready garments. Our system includes a three-stage pipeline. We first employ a large language model to interpret textual descriptions into parameterized body shapes and semantically matched garment templates. Next, we develop topology-preserving deformation with novel geometric losses to adapt garments precisely to body geometries. Furthermore, an enhanced texture diffusion module with a symmetric local attention mechanism ensures both view consistency and photorealistic details. Quantitative and qualitative evaluations demonstrate that Tailor outperforms existing SoTA methods in terms of fidelity, usability, and diversity. Code will be available for academic use.
Towards Better Robustness: Progressively Joint Pose-3DGS Learning for Arbitrarily Long Videos
Jan 25, 2025



3D Gaussian Splatting (3DGS) has emerged as a powerful representation due to its efficiency and high-fidelity rendering. However, 3DGS training requires a known camera pose for each input view, typically obtained by Structure-from-Motion (SfM) pipelines. Pioneering works have attempted to relax this restriction but still face difficulties when handling long sequences with complex camera trajectories. In this work, we propose Rob-GS, a robust framework to progressively estimate camera poses and optimize 3DGS for arbitrarily long video sequences. Leveraging the inherent continuity of videos, we design an adjacent pose tracking method to ensure stable pose estimation between consecutive frames. To handle arbitrarily long inputs, we adopt a "divide and conquer" scheme that adaptively splits the video sequence into several segments and optimizes them separately. Extensive experiments on the Tanks and Temples dataset and our collected real-world dataset show that our Rob-GS outperforms the state-of-the-arts.
PVP-Recon: Progressive View Planning via Warping Consistency for Sparse-View Surface Reconstruction
Sep 09, 2024



Neural implicit representations have revolutionized dense multi-view surface reconstruction, yet their performance significantly diminishes with sparse input views. A few pioneering works have sought to tackle the challenge of sparse-view reconstruction by leveraging additional geometric priors or multi-scene generalizability. However, they are still hindered by the imperfect choice of input views, using images under empirically determined viewpoints to provide considerable overlap. We propose PVP-Recon, a novel and effective sparse-view surface reconstruction method that progressively plans the next best views to form an optimal set of sparse viewpoints for image capturing. PVP-Recon starts initial surface reconstruction with as few as 3 views and progressively adds new views which are determined based on a novel warping score that reflects the information gain of each newly added view. This progressive view planning progress is interleaved with a neural SDF-based reconstruction module that utilizes multi-resolution hash features, enhanced by a progressive training scheme and a directional Hessian loss. Quantitative and qualitative experiments on three benchmark datasets show that our framework achieves high-quality reconstruction with a constrained input budget and outperforms existing baselines.
Gaussian in the Dark: Real-Time View Synthesis From Inconsistent Dark Images Using Gaussian Splatting
Aug 20, 2024



3D Gaussian Splatting has recently emerged as a powerful representation that can synthesize remarkable novel views using consistent multi-view images as input. However, we notice that images captured in dark environments where the scenes are not fully illuminated can exhibit considerable brightness variations and multi-view inconsistency, which poses great challenges to 3D Gaussian Splatting and severely degrades its performance. To tackle this problem, we propose Gaussian-DK. Observing that inconsistencies are mainly caused by camera imaging, we represent a consistent radiance field of the physical world using a set of anisotropic 3D Gaussians, and design a camera response module to compensate for multi-view inconsistencies. We also introduce a step-based gradient scaling strategy to constrain Gaussians near the camera, which turn out to be floaters, from splitting and cloning. Experiments on our proposed benchmark dataset demonstrate that Gaussian-DK produces high-quality renderings without ghosting and floater artifacts and significantly outperforms existing methods. Furthermore, we can also synthesize light-up images by controlling exposure levels that clearly show details in shadow areas.
DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models
Sep 30, 2023



The generation of stylistic 3D facial animations driven by speech poses a significant challenge as it requires learning a many-to-many mapping between speech, style, and the corresponding natural facial motion. However, existing methods either employ a deterministic model for speech-to-motion mapping or encode the style using a one-hot encoding scheme. Notably, the one-hot encoding approach fails to capture the complexity of the style and thus limits generalization ability. In this paper, we propose DiffPoseTalk, a generative framework based on the diffusion model combined with a style encoder that extracts style embeddings from short reference videos. During inference, we employ classifier-free guidance to guide the generation process based on the speech and style. We extend this to include the generation of head poses, thereby enhancing user perception. Additionally, we address the shortage of scanned 3D talking face data by training our model on reconstructed 3DMM parameters from a high-quality, in-the-wild audio-visual dataset. Our extensive experiments and user study demonstrate that our approach outperforms state-of-the-art methods. The code and dataset will be made publicly available.
Indoor Scene Reconstruction with Fine-Grained Details Using Hybrid Representation and Normal Prior Enhancement
Sep 14, 2023



The reconstruction of indoor scenes from multi-view RGB images is challenging due to the coexistence of flat and texture-less regions alongside delicate and fine-grained regions. Recent methods leverage neural radiance fields aided by predicted surface normal priors to recover the scene geometry. These methods excel in producing complete and smooth results for floor and wall areas. However, they struggle to capture complex surfaces with high-frequency structures due to the inadequate neural representation and the inaccurately predicted normal priors. To improve the capacity of the implicit representation, we propose a hybrid architecture to represent low-frequency and high-frequency regions separately. To enhance the normal priors, we introduce a simple yet effective image sharpening and denoising technique, coupled with a network that estimates the pixel-wise uncertainty of the predicted surface normal vectors. Identifying such uncertainty can prevent our model from being misled by unreliable surface normal supervisions that hinder the accurate reconstruction of intricate geometries. Experiments on the benchmark datasets show that our method significantly outperforms existing methods in terms of reconstruction quality.
O^2-Recon: Completing 3D Reconstruction of Occluded Objects in the Scene with a Pre-trained 2D Diffusion Model
Aug 18, 2023Occlusion is a common issue in 3D reconstruction from RGB-D videos, often blocking the complete reconstruction of objects and presenting an ongoing problem. In this paper, we propose a novel framework, empowered by a 2D diffusion-based in-painting model, to reconstruct complete surfaces for the hidden parts of objects. Specifically, we utilize a pre-trained diffusion model to fill in the hidden areas of 2D images. Then we use these in-painted images to optimize a neural implicit surface representation for each instance for 3D reconstruction. Since creating the in-painting masks needed for this process is tricky, we adopt a human-in-the-loop strategy that involves very little human engagement to generate high-quality masks. Moreover, some parts of objects can be totally hidden because the videos are usually shot from limited perspectives. To ensure recovering these invisible areas, we develop a cascaded network architecture for predicting signed distance field, making use of different frequency bands of positional encoding and maintaining overall smoothness. Besides the commonly used rendering loss, Eikonal loss, and silhouette loss, we adopt a CLIP-based semantic consistency loss to guide the surface from unseen camera angles. Experiments on ScanNet scenes show that our proposed framework achieves state-of-the-art accuracy and completeness in object-level reconstruction from scene-level RGB-D videos.