 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamAvatar: Streaming Diffusion Models for Real-Time Interactive Human Avatars
Dec 26, 2025Real-time, streaming interactive avatars represent a critical yet challenging goal in digital human research. Although diffusion-based human avatar generation methods achieve remarkable success, their non-causal architecture and high computational costs make them unsuitable for streaming. Moreover, existing interactive approaches are typically limited to head-and-shoulder region, limiting their ability to produce gestures and body motions. To address these challenges, we propose a two-stage autoregressive adaptation and acceleration framework that applies autoregressive distillation and adversarial refinement to adapt a high-fidelity human video diffusion model for real-time, interactive streaming. To ensure long-term stability and consistency, we introduce three key components: a Reference Sink, a Reference-Anchored Positional Re-encoding (RAPR) strategy, and a Consistency-Aware Discriminator. Building on this framework, we develop a one-shot, interactive, human avatar model capable of generating both natural talking and listening behaviors with coherent gestures. Extensive experiments demonstrate that our method achieves state-of-the-art performance, surpassing existing approaches in generation quality, real-time efficiency, and interaction naturalness. Project page: https://streamavatar.github.io .
ActAvatar: Temporally-Aware Precise Action Control for Talking Avatars
Dec 22, 2025Despite significant advances in talking avatar generation, existing methods face critical challenges: insufficient text-following capability for diverse actions, lack of temporal alignment between actions and audio content, and dependency on additional control signals such as pose skeletons. We present ActAvatar, a framework that achieves phase-level precision in action control through textual guidance by capturing both action semantics and temporal context. Our approach introduces three core innovations: (1) Phase-Aware Cross-Attention (PACA), which decomposes prompts into a global base block and temporally-anchored phase blocks, enabling the model to concentrate on phase-relevant tokens for precise temporal-semantic alignment; (2) Progressive Audio-Visual Alignment, which aligns modality influence with the hierarchical feature learning process-early layers prioritize text for establishing action structure while deeper layers emphasize audio for refining lip movements, preventing modality interference; (3) A two-stage training strategy that first establishes robust audio-visual correspondence on diverse data, then injects action control through fine-tuning on structured annotations, maintaining both audio-visual alignment and the model's text-following capabilities. Extensive experiments demonstrate that ActAvatar significantly outperforms state-of-the-art methods in both action control and visual quality.
Tailor: An Integrated Text-Driven CG-Ready Human and Garment Generation System
Mar 15, 2025Creating detailed 3D human avatars with garments typically requires specialized expertise and labor-intensive processes. Although recent advances in generative AI have enabled text-to-3D human/clothing generation, current methods fall short in offering accessible, integrated pipelines for producing ready-to-use clothed avatars. To solve this, we introduce Tailor, an integrated text-to-avatar system that generates high-fidelity, customizable 3D humans with simulation-ready garments. Our system includes a three-stage pipeline. We first employ a large language model to interpret textual descriptions into parameterized body shapes and semantically matched garment templates. Next, we develop topology-preserving deformation with novel geometric losses to adapt garments precisely to body geometries. Furthermore, an enhanced texture diffusion module with a symmetric local attention mechanism ensures both view consistency and photorealistic details. Quantitative and qualitative evaluations demonstrate that Tailor outperforms existing SoTA methods in terms of fidelity, usability, and diversity. Code will be available for academic use.
DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models
Sep 30, 2023



The generation of stylistic 3D facial animations driven by speech poses a significant challenge as it requires learning a many-to-many mapping between speech, style, and the corresponding natural facial motion. However, existing methods either employ a deterministic model for speech-to-motion mapping or encode the style using a one-hot encoding scheme. Notably, the one-hot encoding approach fails to capture the complexity of the style and thus limits generalization ability. In this paper, we propose DiffPoseTalk, a generative framework based on the diffusion model combined with a style encoder that extracts style embeddings from short reference videos. During inference, we employ classifier-free guidance to guide the generation process based on the speech and style. We extend this to include the generation of head poses, thereby enhancing user perception. Additionally, we address the shortage of scanned 3D talking face data by training our model on reconstructed 3DMM parameters from a high-quality, in-the-wild audio-visual dataset. Our extensive experiments and user study demonstrate that our approach outperforms state-of-the-art methods. The code and dataset will be made publicly available.
Continuously Controllable Facial Expression Editing in Talking Face Videos
Sep 17, 2022
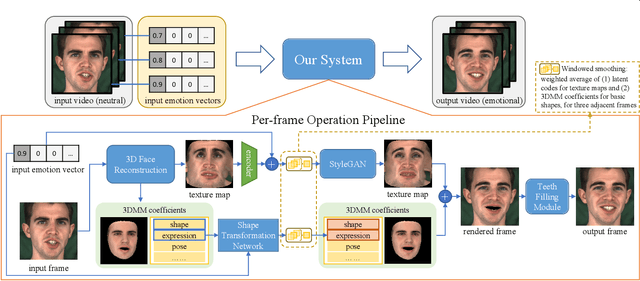

Recently audio-driven talking face video generation has attracted considerable attention. However, very few researches address the issue of emotional editing of these talking face videos with continuously controllable expressions, which is a strong demand in the industry. The challenge is that speech-related expressions and emotion-related expressions are often highly coupled. Meanwhile, traditional image-to-image translation methods cannot work well in our application due to the coupling of expressions with other attributes such as poses, i.e., translating the expression of the character in each frame may simultaneously change the head pose due to the bias of the training data distribution. In this paper, we propose a high-quality facial expression editing method for talking face videos, allowing the user to control the target emotion in the edited video continuously. We present a new perspective for this task as a special case of motion information editing, where we use a 3DMM to capture major facial movements and an associated texture map modeled by a StyleGAN to capture appearance details. Both representations (3DMM and texture map) contain emotional information and can be continuously modified by neural networks and easily smoothed by averaging in coefficient/latent spaces, making our method simple yet effective. We also introduce a mouth shape preservation loss to control the trade-off between lip synchronization and the degree of exaggeration of the edited expression. Extensive experiments and a user study show that our method achieves state-of-the-art performance across various evaluation criteria.
Dynamic Neural Textures: Generating Talking-Face Videos with Continuously Controllable Expressions
Apr 13, 2022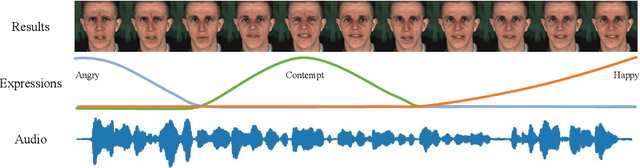
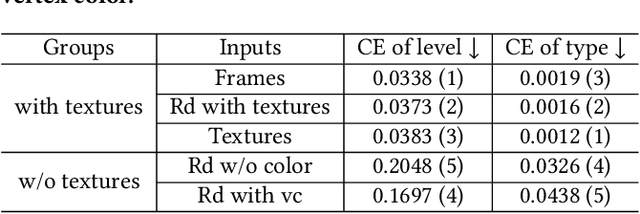
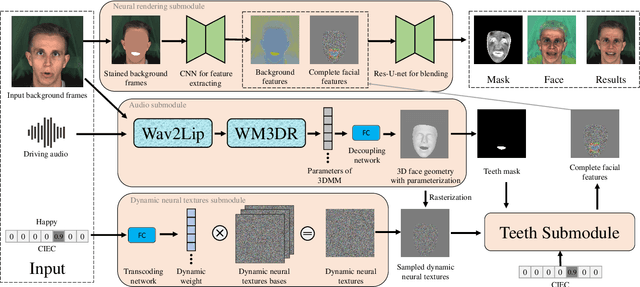
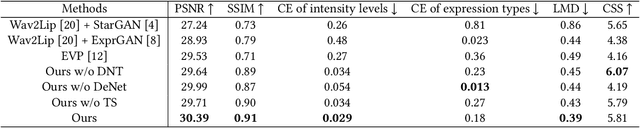
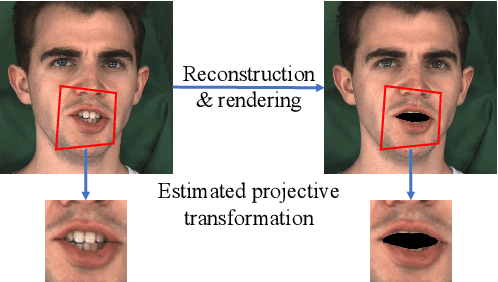
Recently, talking-face video generation has received considerable attention. So far most methods generate results with neutral expressions or expressions that are implicitly determined by neural networks in an uncontrollable way. In this paper, we propose a method to generate talking-face videos with continuously controllable expressions in real-time. Our method is based on an important observation: In contrast to facial geometry of moderate resolution, most expression information lies in textures. Then we make use of neural textures to generate high-quality talking face videos and design a novel neural network that can generate neural textures for image frames (which we called dynamic neural textures) based on the input expression and continuous intensity expression coding (CIEC). Our method uses 3DMM as a 3D model to sample the dynamic neural texture. The 3DMM does not cover the teeth area, so we propose a teeth submodule to complete the details in teeth. Results and an ablation study show the effectiveness of our method in generating high-quality talking-face videos with continuously controllable expressions. We also set up four baseline methods by combining existing representative methods and compare them with our method. Experimental results including a user study show that our method has the best performance.