 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Teal: Learning-Accelerated Optimization of Traffic Engineering
Oct 25, 2022
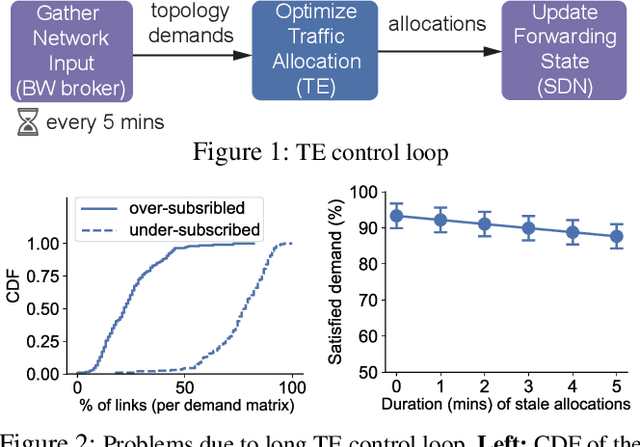

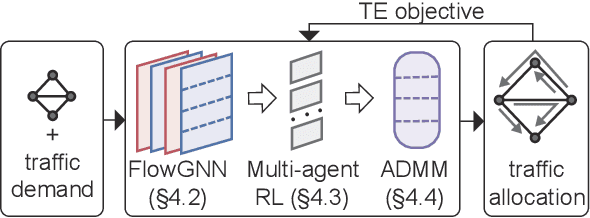
In the last decade, global cloud wide-area networks (WANs) have grown 10$\times$ in size due to the deployment of new network sites and datacenters, making it challenging for commercial optimization engines to solve the network traffic engineering (TE) problem within the temporal budget of a few minutes. In this work, we show that carefully designed deep learning models are key to accelerating the running time of intra-WAN TE systems for large deployments since deep learning is both massively parallel and it benefits from the wealth of historical traffic allocation data from production WANs. However, off-the-shelf deep learning methods fail to perform well on the TE task since they ignore the effects of network connectivity on flow allocations. They are also faced with a tractability challenge posed by the large problem scale of TE optimization. Moreover, neural networks do not have mechanisms to readily enforce hard constraints on model outputs (e.g., link capacity constraints). We tackle these challenges by designing a deep learning-based TE system -- Teal. First, Teal leverages graph neural networks (GNN) to faithfully capture connectivity and model network flows. Second, Teal devises a multi-agent reinforcement learning (RL) algorithm to process individual demands independently in parallel to lower the problem scale. Finally, Teal reduces link capacity violations and improves solution quality using the alternating direction method of multipliers (ADMM). We evaluate Teal on traffic matrices of a global commercial cloud provider and find that Teal computes near-optimal traffic allocations with a 59$\times$ speedup over state-of-the-art TE systems on a WAN topology of over 1,500 nodes.
Decoupling Features in Hierarchical Propagation for Video Object Segmentation
Oct 19, 2022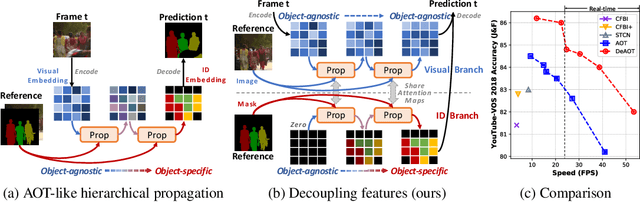
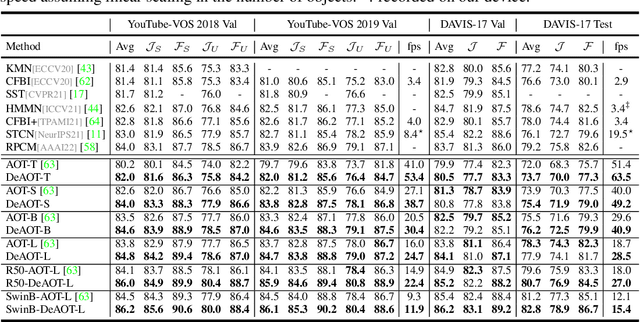
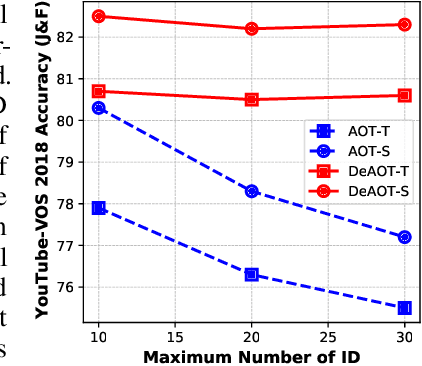
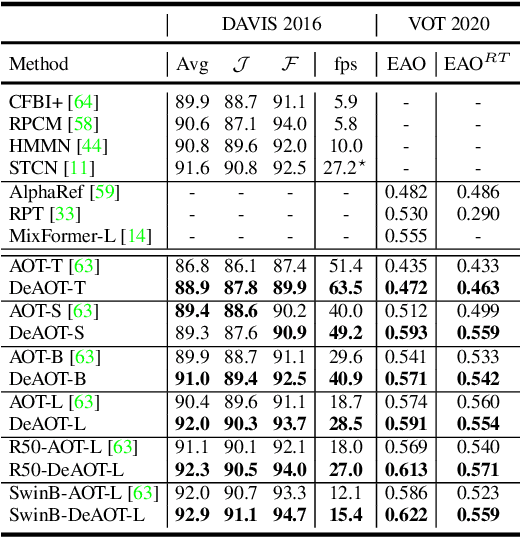
This paper focuses on developing a more effective method of hierarchical propagation for semi-supervised Video Object Segmentation (VOS). Based on vision transformers, the recently-developed Associating Objects with Transformers (AOT) approach introduces hierarchical propagation into VOS and has shown promising results. The hierarchical propagation can gradually propagate information from past frames to the current frame and transfer the current frame feature from object-agnostic to object-specific. However, the increase of object-specific information will inevitably lead to the loss of object-agnostic visual information in deep propagation layers. To solve such a problem and further facilitate the learning of visual embeddings, this paper proposes a Decoupling Features in Hierarchical Propagation (DeAOT) approach. Firstly, DeAOT decouples the hierarchical propagation of object-agnostic and object-specific embeddings by handling them in two independent branches. Secondly, to compensate for the additional computation from dual-branch propagation, we propose an efficient module for constructing hierarchical propagation, i.e., Gated Propagation Module, which is carefully designed with single-head attention. Extensive experiments show that DeAOT significantly outperforms AOT in both accuracy and efficiency. On YouTube-VOS, DeAOT can achieve 86.0% at 22.4fps and 82.0% at 53.4fps. Without test-time augmentations, we achieve new state-of-the-art performance on four benchmarks, i.e., YouTube-VOS (86.2%), DAVIS 2017 (86.2%), DAVIS 2016 (92.9%), and VOT 2020 (0.622). Project page: https://github.com/z-x-yang/AOT.
Cluster and Aggregate: Face Recognition with Large Probe Set
Oct 19, 2022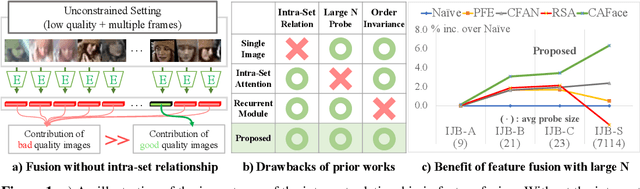
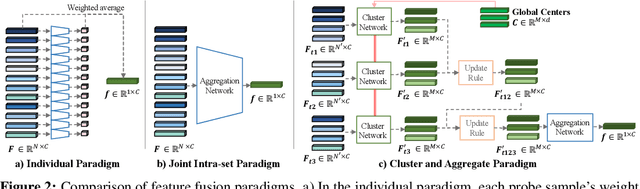
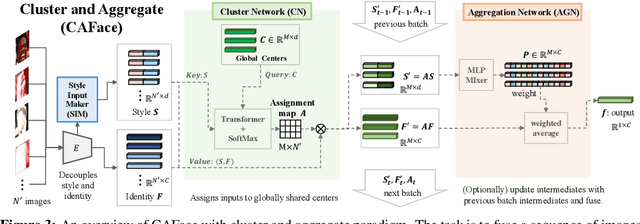

Feature fusion plays a crucial role in unconstrained face recognition where inputs (probes) comprise of a set of $N$ low quality images whose individual qualities vary. Advances in attention and recurrent modules have led to feature fusion that can model the relationship among the images in the input set. However, attention mechanisms cannot scale to large $N$ due to their quadratic complexity and recurrent modules suffer from input order sensitivity. We propose a two-stage feature fusion paradigm, Cluster and Aggregate, that can both scale to large $N$ and maintain the ability to perform sequential inference with order invariance. Specifically, Cluster stage is a linear assignment of $N$ inputs to $M$ global cluster centers, and Aggregation stage is a fusion over $M$ clustered features. The clustered features play an integral role when the inputs are sequential as they can serve as a summarization of past features. By leveraging the order-invariance of incremental averaging operation, we design an update rule that achieves batch-order invariance, which guarantees that the contributions of early image in the sequence do not diminish as time steps increase. Experiments on IJB-B and IJB-S benchmark datasets show the superiority of the proposed two-stage paradigm in unconstrained face recognition. Code and pretrained models are available in https://github.com/mk-minchul/caface
Cyber Mobility Mirror: Deep Learning-based Real-time 3D Object Perception and Reconstruction Using Roadside LiDAR
Feb 28, 2022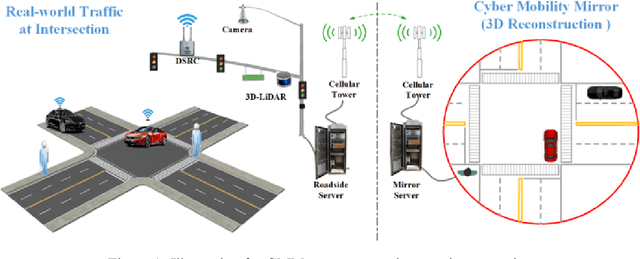
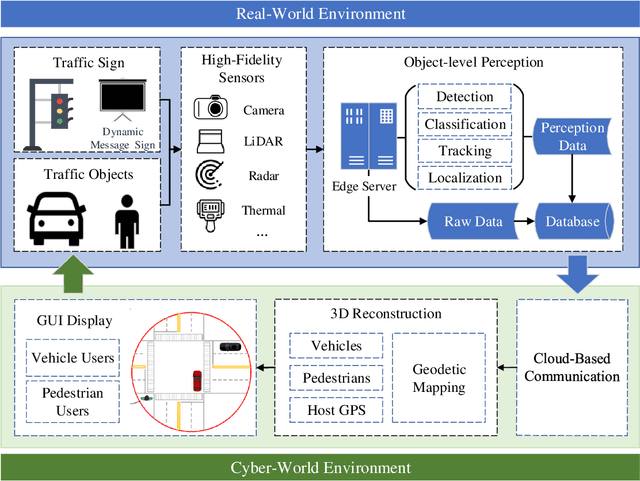
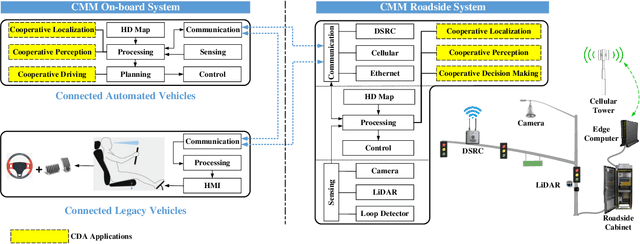
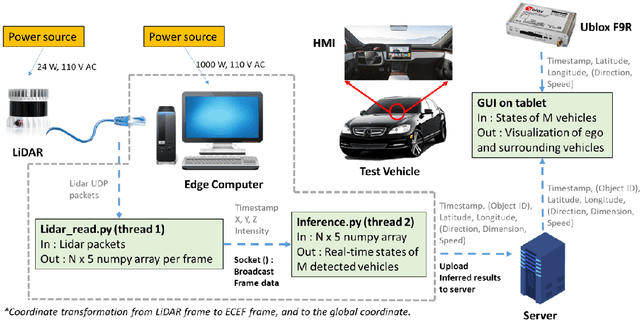
Enabling Cooperative Driving Automation (CDA) requires high-fidelity and real-time perception information, which is available from onboard sensors or vehicle-to-everything (V2X) communications. Nevertheless, the accessibility of this information may suffer from the range and occlusion of perception or limited penetration rates in connectivity. In this paper, we introduce the prototype of Cyber Mobility Mirror (CMM), a next-generation real-time traffic surveillance system for 3D object detection, classification, tracking, and reconstruction, to provide CAVs with wide-range high-fidelity perception information in a mixed traffic environment. The CMM system consists of six main components: 1) the data pre-processor to retrieve and pre-process raw data from the roadside LiDAR; 2) the 3D object detector to generate 3D bounding boxes based on point cloud data; 3) the multi-objects tracker to endow unique IDs to detected objects and estimate their dynamic states; 4) the global locator to map positioning information from the LiDAR coordinate to geographic coordinate using coordinate transformation; 5) the cloud-based communicator to transmit perception information from roadside sensors to equipped vehicles; and 6) the onboard advisor to reconstruct and display the real-time traffic conditions via Graphical User Interface (GUI). In this study, a field-operational prototype system is deployed at a real-world intersection, University Avenue and Iowa Avenue in Riverside, California to assess the feasibility and performance of our CMM system. Results from field tests demonstrate that our CMM prototype system can provide satisfactory perception performance with 96.99% precision and 83.62% recall. High-fidelity real-time traffic conditions (at the object level) can be displayed on the GUI of the equipped vehicle with a frequency of 3-4 Hz.
Learning Non-Stationary Time-Series with Dynamic Pattern Extractions
Nov 20, 2021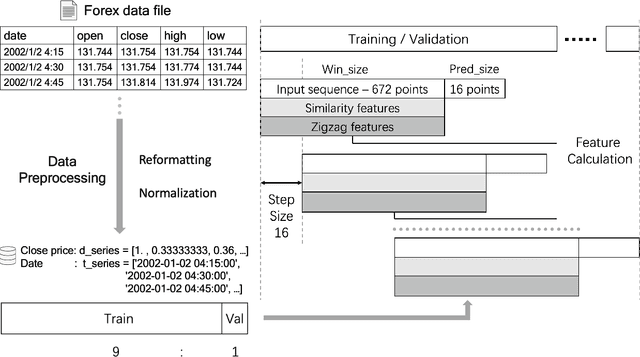
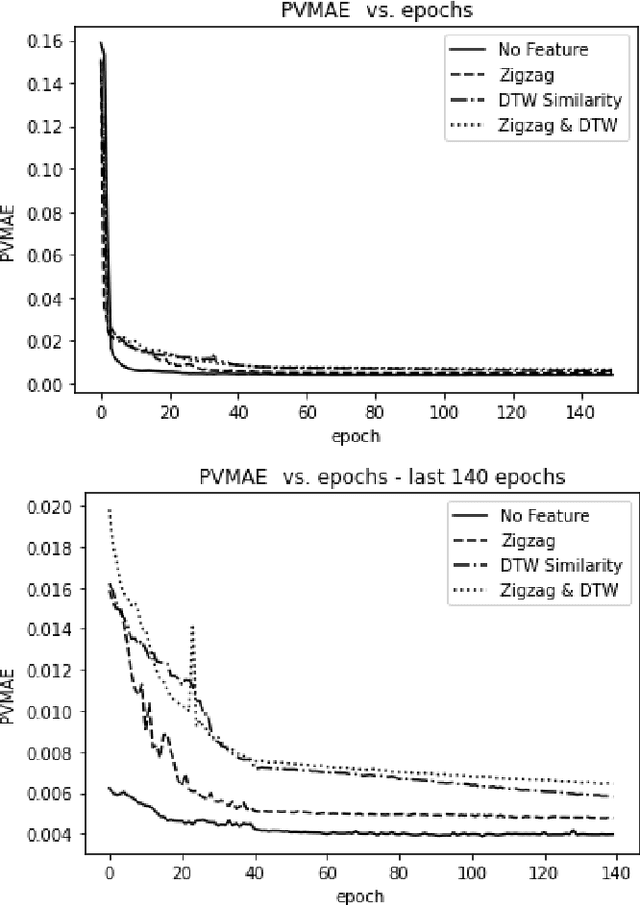
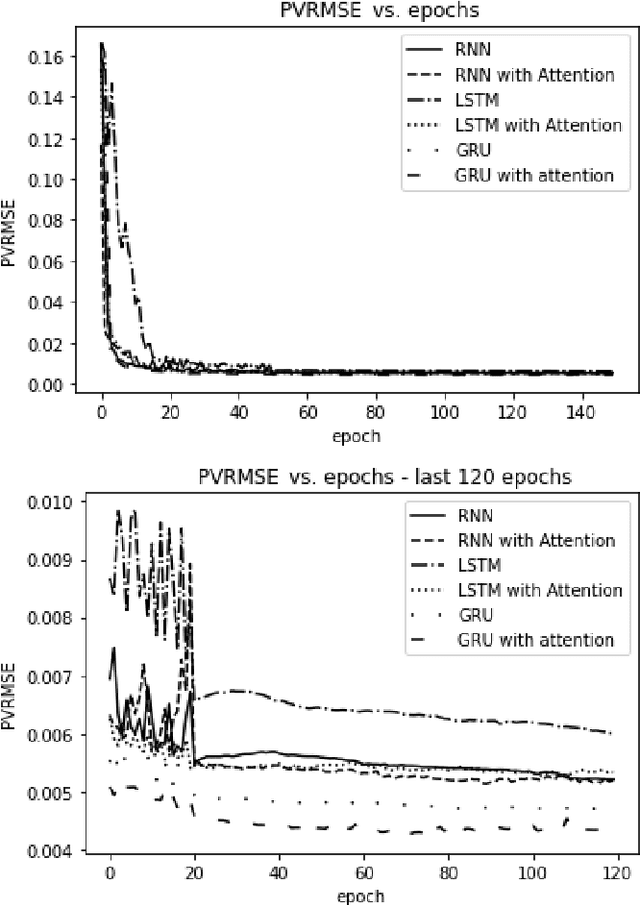
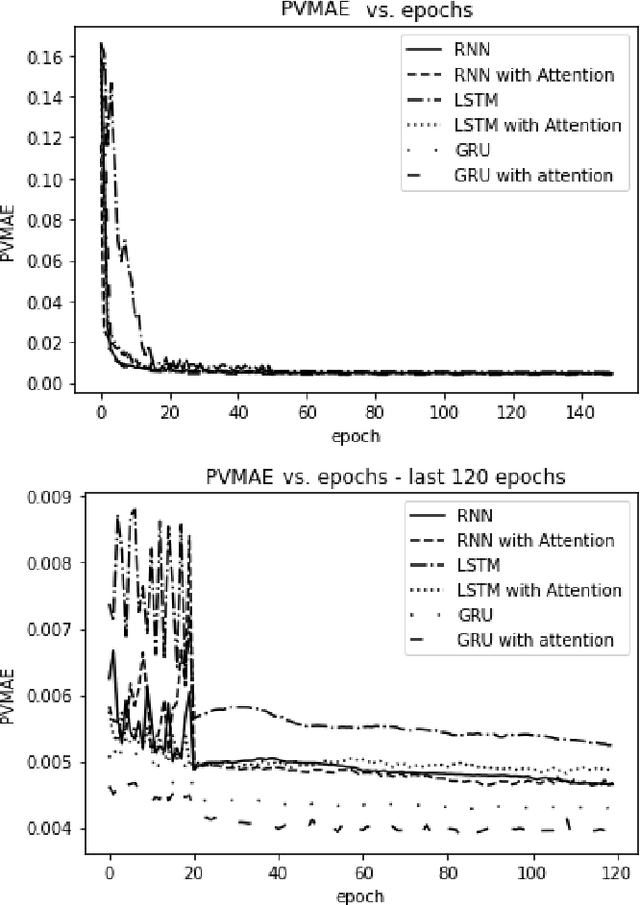
The era of information explosion had prompted the accumulation of a tremendous amount of time-series data, including stationary and non-stationary time-series data. State-of-the-art algorithms have achieved a decent performance in dealing with stationary temporal data. However, traditional algorithms that tackle stationary time-series do not apply to non-stationary series like Forex trading. This paper investigates applicable models that can improve the accuracy of forecasting future trends of non-stationary time-series sequences. In particular, we focus on identifying potential models and investigate the effects of recognizing patterns from historical data. We propose a combination of \rebuttal{the} seq2seq model based on RNN, along with an attention mechanism and an enriched set features extracted via dynamic time warping and zigzag peak valley indicators. Customized loss functions and evaluating metrics have been designed to focus more on the predicting sequence's peaks and valley points. Our results show that our model can predict 4-hour future trends with high accuracy in the Forex dataset, which is crucial in realistic scenarios to assist foreign exchange trading decision making. We further provide evaluations of the effects of various loss functions, evaluation metrics, model variants, and components on model performance.
An Overview of the Data-Loader Landscape: Comparative Performance Analysis
Sep 27, 2022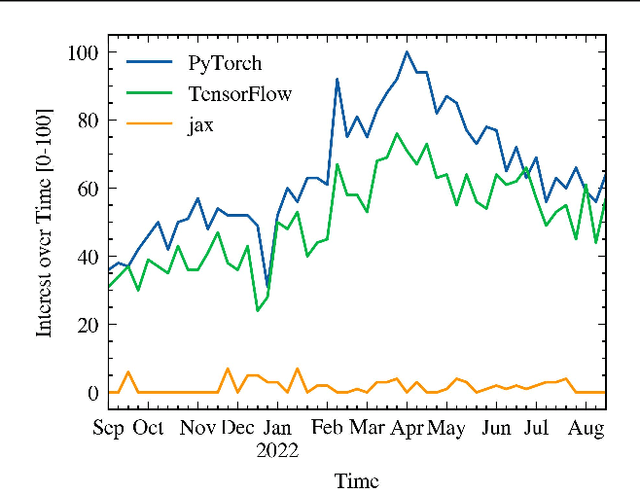
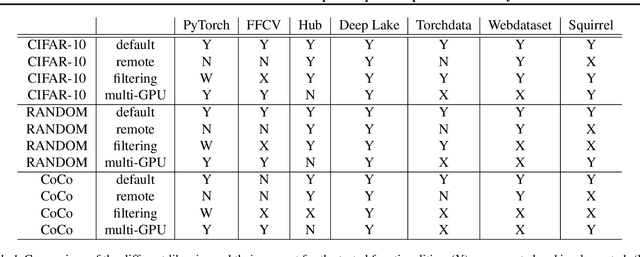
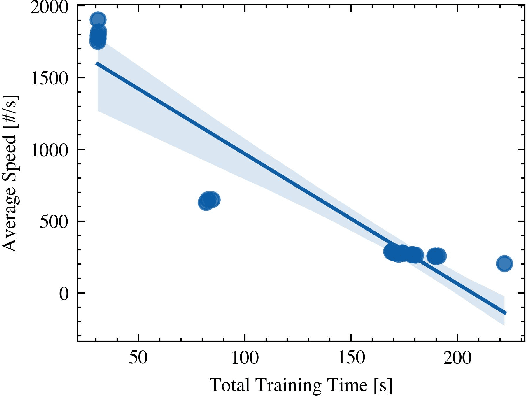
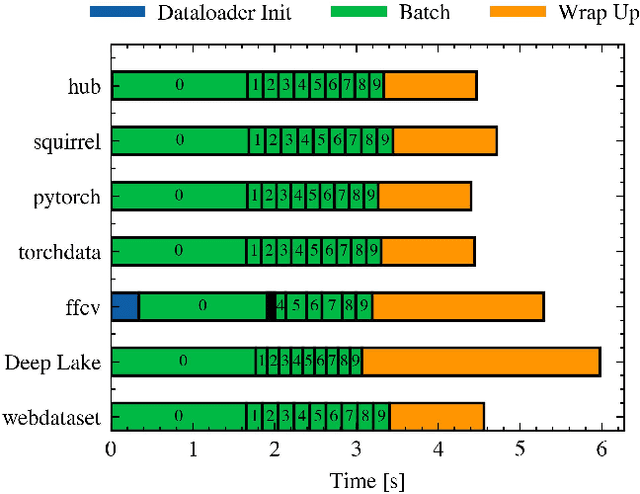
Dataloaders, in charge of moving data from storage into GPUs while training machine learning models, might hold the key to drastically improving the performance of training jobs. Recent advances have shown promise not only by considerably decreasing training time but also by offering new features such as loading data from remote storage like S3. In this paper, we are the first to distinguish the dataloader as a separate component in the Deep Learning (DL) workflow and to outline its structure and features. Finally, we offer a comprehensive comparison of the different dataloading libraries available, their trade-offs in terms of functionality, usability, and performance and the insights derived from them.
A Guide to Employ Hyperspectral Imaging for Assessing Wheat Quality at Different Stages of Supply Chain in Australia: A Review
Sep 13, 2022


Wheat is one of the major staple crops across the globe. Therefore, it is mandatory to measure, maintain and improve the wheat quality for human consumption. Traditional wheat quality measurement methods are mostly invasive, destructive and limited to small samples of wheat. In a typical supply chain of wheat, there are many receival points where bulk wheat arrives, gets stored and forwarded as per the requirements. In this receival points, the application of traditional quality measurement methods is difficult and often very expensive. Therefore, there is a need for non-invasive, non-destructive real-time methods for wheat quality assessments. One such method that fulfils the above-mentioned criteria is hyperspectral imaging (HSI) for food quality measurement and it can also be applied to bulk samples. In this paper, we have investigated how HSI has been used in the literature for assessing stored wheat quality. So that the required information to implement real-time digital quality assessment methods at the different stages of Australian supply chain can be made available in a single and compact document.
A Comprehensive Study on Large-Scale Graph Training: Benchmarking and Rethinking
Oct 14, 2022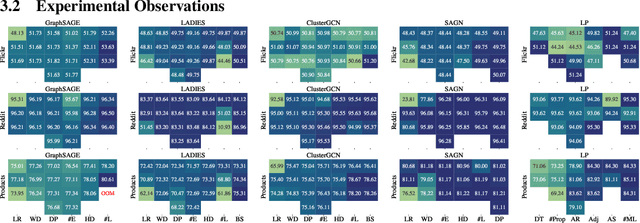
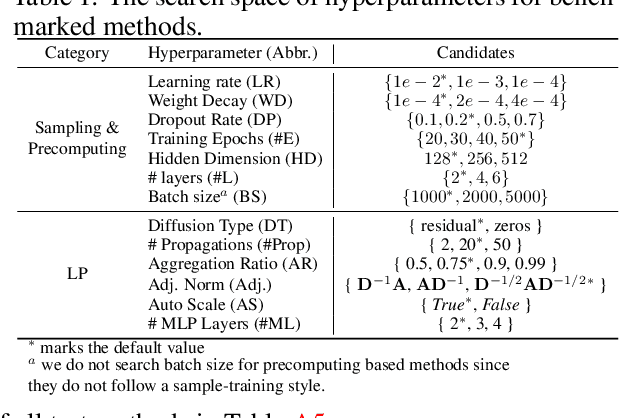

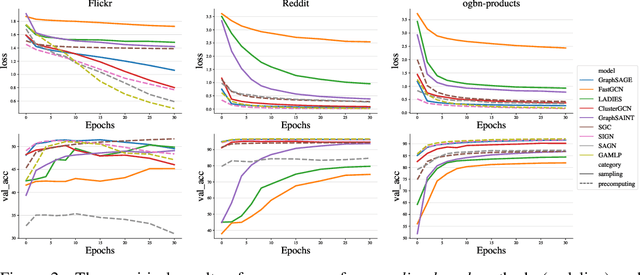
Large-scale graph training is a notoriously challenging problem for graph neural networks (GNNs). Due to the nature of evolving graph structures into the training process, vanilla GNNs usually fail to scale up, limited by the GPU memory space. Up to now, though numerous scalable GNN architectures have been proposed, we still lack a comprehensive survey and fair benchmark of this reservoir to find the rationale for designing scalable GNNs. To this end, we first systematically formulate the representative methods of large-scale graph training into several branches and further establish a fair and consistent benchmark for them by a greedy hyperparameter searching. In addition, regarding efficiency, we theoretically evaluate the time and space complexity of various branches and empirically compare them w.r.t GPU memory usage, throughput, and convergence. Furthermore, We analyze the pros and cons for various branches of scalable GNNs and then present a new ensembling training manner, named EnGCN, to address the existing issues. Remarkably, our proposed method has achieved new state-of-the-art (SOTA) performance on large-scale datasets. Our code is available at https://github.com/VITA-Group/Large_Scale_GCN_Benchmarking.
Frame Mining: a Free Lunch for Learning Robotic Manipulation from 3D Point Clouds
Oct 14, 2022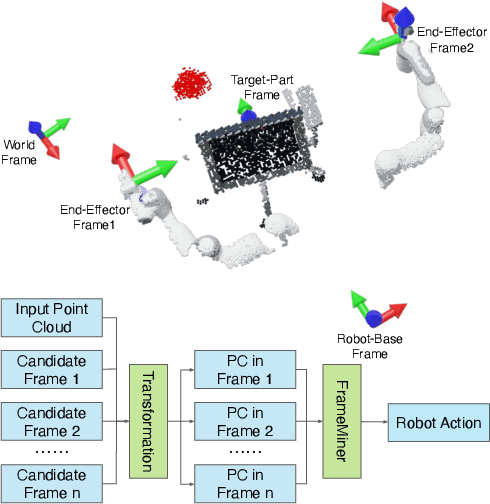
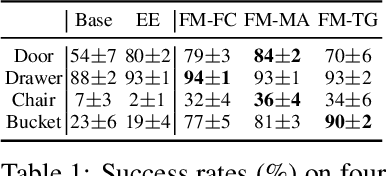
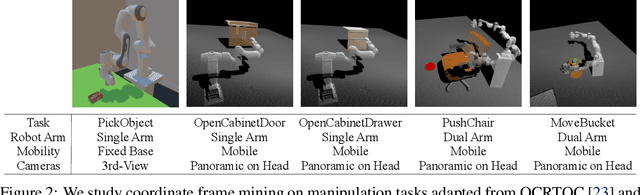
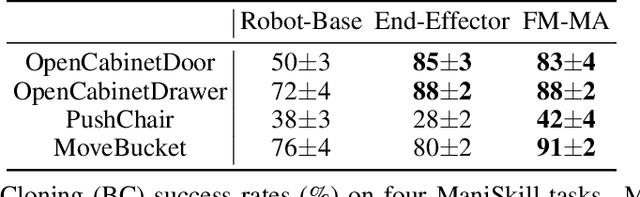
We study how choices of input point cloud coordinate frames impact learning of manipulation skills from 3D point clouds. There exist a variety of coordinate frame choices to normalize captured robot-object-interaction point clouds. We find that different frames have a profound effect on agent learning performance, and the trend is similar across 3D backbone networks. In particular, the end-effector frame and the target-part frame achieve higher training efficiency than the commonly used world frame and robot-base frame in many tasks, intuitively because they provide helpful alignments among point clouds across time steps and thus can simplify visual module learning. Moreover, the well-performing frames vary across tasks, and some tasks may benefit from multiple frame candidates. We thus propose FrameMiners to adaptively select candidate frames and fuse their merits in a task-agnostic manner. Experimentally, FrameMiners achieves on-par or significantly higher performance than the best single-frame version on five fully physical manipulation tasks adapted from ManiSkill and OCRTOC. Without changing existing camera placements or adding extra cameras, point cloud frame mining can serve as a free lunch to improve 3D manipulation learning.
Quo Vadis: Is Trajectory Forecasting the Key Towards Long-Term Multi-Object Tracking?
Oct 14, 2022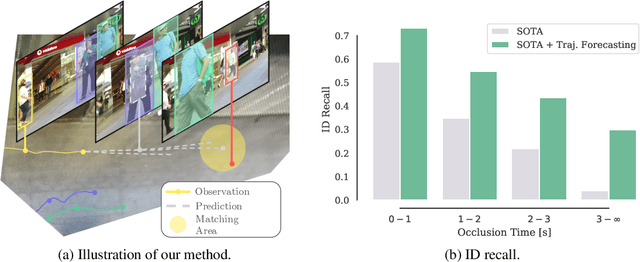
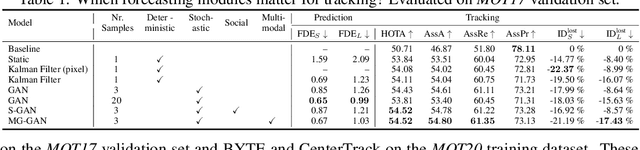
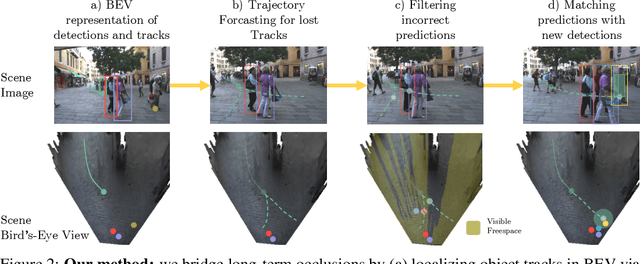
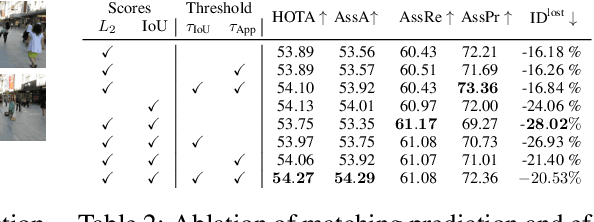
Recent developments in monocular multi-object tracking have been very successful in tracking visible objects and bridging short occlusion gaps, mainly relying on data-driven appearance models. While we have significantly advanced short-term tracking performance, bridging longer occlusion gaps remains elusive: state-of-the-art object trackers only bridge less than 10% of occlusions longer than three seconds. We suggest that the missing key is reasoning about future trajectories over a longer time horizon. Intuitively, the longer the occlusion gap, the larger the search space for possible associations. In this paper, we show that even a small yet diverse set of trajectory predictions for moving agents will significantly reduce this search space and thus improve long-term tracking robustness. Our experiments suggest that the crucial components of our approach are reasoning in a bird's-eye view space and generating a small yet diverse set of forecasts while accounting for their localization uncertainty. This way, we can advance state-of-the-art trackers on the MOTChallenge dataset and significantly improve their long-term tracking performance. This paper's source code and experimental data are available at https://github.com/dendorferpatrick/QuoVadis.