 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning through Verifiable Forecast Actions: Consistency-Grounded RL for Financial LLMs
May 21, 2026Financial markets are characterized by extreme non-stationarity, low signal-to-noise ratios, and strong dependence on external information such as news, company fundamentals, and macroeconomic signals. Yet, existing approaches either abstract time-series into text or decouple forecasting from language-based reasoning, leading to a fundamental mismatch between qualitative reasoning and quantitative outcomes. To address this, we introduce StockR1, a time-series-enhanced LLM that unifies stock forecasting and financial reasoning through a verifiable forecast action. Based on a tool-call design, the model first emits a forecast action, which is a structured and interpretable representation of its qualitative market outlook. It then invokes a time-series decoder conditioned on this action to generate distributional future trajectories, leading to more informed question answering and financial reasoning. We optimize the full pipeline with reinforcement learning, where rewards jointly reflect answer validity, forecast accuracy, and consistency between generated actions and observed time-series dynamics. In addition, rewards are reweighted by a sample-level uncertainty scalar, encouraging the model to accommodate varying uncertainty in market dynamics. We evaluate StockR1 on financial question answering and stock forecasting over a large-scale 10-year benchmark. Our method consistently outperforms time-series baselines and general-purpose LLMs, improving reasoning accuracy by 17.7% (4B) and 25.9% (8B). These findings demonstrate that structuring the forecast actions establishes a powerful synergy between language reasoning and temporal prediction, enabling LLMs to reason through verifiable, interpretable, and numerically grounded decisions.
CLAD: A Clustered Label-Agnostic Federated Learning Framework for Joint Anomaly Detection and Attack Classification
May 07, 2026The rapid expansion of the Internet of Things (IoT) and Industrial IoT (IIoT) has created a massive, heterogeneous attack surface that challenges traditional network security mechanisms. While Federated Learning (FL) offers a privacy-preserving alternative to centralized Intrusion Detection Systems (IDS), standard approaches struggle to generalize across diverse device behaviors and typically fail to utilize the vast amounts of unlabeled data present in realistic edge environments. To bridge these gaps, we propose CLAD, a holistic framework that seamlessly incorporates Clustered Federated Learning (CFL) with a novel Dual-Mode Micro-Architecture ($\text{DM}^2\text{A}$). This unified approach simultaneously tackles the two primary bottlenecks of IoT security: device heterogeneity and label scarcity. The $\text{DM}^2\text{A}$ component features a shared encoder followed by two branches, enabling joint unsupervised anomaly detection and supervised attack classification; this allows the framework to harvest intelligence from both labeled and unlabeled clients. Concurrently, the clustering component dynamically groups devices with congruent traffic patterns, preventing global model divergence. By carefully combining these elements, CLAD ensures that no data is discarded and distinct operational patterns are preserved. Extensive evaluations demonstrate that this integrated approach significantly outperforms state-of-the-art baselines, achieving a 30% relative improvement in detection performance in scenarios with 80% unlabeled clients, with only half the communication cost.
A Family of Open Time-Series Foundation Models for the Radio Access Network
Apr 05, 2026The Radio Access Network (RAN) is evolving into a programmable and disaggregated infrastructure that increasingly relies on AI-native algorithms for optimization and closed-loop control. However, current RAN intelligence is still largely built from task-specific models tailored to individual functions, resulting in model fragmentation, limited knowledge sharing across tasks, poor generalization, and increased system complexity. To address these limitations, we introduce TimeRAN, a unified multi-task learning framework for time-series modeling in the RAN. TimeRAN leverages a lightweight time-series foundation model with few task-specific heads to learn transferable representations that can be efficiently adapted across diverse tasks with limited supervision. To enable large-scale pretraining, we further curate and open-source TimeRAN DataPile, the largest time-series corpus for RAN analytics to date, comprising over 355K time series and 0.56B measurements across diverse telemetry sources, protocol layers, and deployment scenarios. We evaluate TimeRAN across a comprehensive set of RAN analytics tasks, including anomaly detection, classification, forecasting, and imputation, and show that it achieves state-of-the-art performance with minimal or no task-specific fine-tuning. Finally, we integrate TimeRAN into a proof-of-concept 5G testbed and demonstrate that it operates efficiently with limited resource requirements in real-world scenarios.
HypRAG: Hyperbolic Dense Retrieval for Retrieval Augmented Generation
Feb 08, 2026Embedding geometry plays a fundamental role in retrieval quality, yet dense retrievers for retrieval-augmented generation (RAG) remain largely confined to Euclidean space. However, natural language exhibits hierarchical structure from broad topics to specific entities that Euclidean embeddings fail to preserve, causing semantically distant documents to appear spuriously similar and increasing hallucination risk. To address these limitations, we introduce hyperbolic dense retrieval, developing two model variants in the Lorentz model of hyperbolic space: HyTE-FH, a fully hyperbolic transformer, and HyTE-H, a hybrid architecture projecting pre-trained Euclidean embeddings into hyperbolic space. To prevent representational collapse during sequence aggregation, we introduce the Outward Einstein Midpoint, a geometry-aware pooling operator that provably preserves hierarchical structure. On MTEB, HyTE-FH outperforms equivalent Euclidean baselines, while on RAGBench, HyTE-H achieves up to 29% gains over Euclidean baselines in context relevance and answer relevance using substantially smaller models than current state-of-the-art retrievers. Our analysis also reveals that hyperbolic representations encode document specificity through norm-based separation, with over 20% radial increase from general to specific concepts, a property absent in Euclidean embeddings, underscoring the critical role of geometric inductive bias in faithful RAG systems.
Fin-RATE: A Real-world Financial Analytics and Tracking Evaluation Benchmark for LLMs on SEC Filings
Feb 07, 2026With increasing deployment of Large Language Models (LLMs) in the finance domain, LLMs are increasingly expected to parse complex regulatory disclosures. However, existing benchmarks often focus on isolated details, failing to reflect the complexity of professional analysis that requires synthesizing information across multiple documents, reporting periods, and corporate entities. They do not distinguish whether errors stem from retrieval failures, generation flaws, finance-specific reasoning mistakes, or misunderstanding of the query or context. This makes it difficult to pinpoint performance bottlenecks. To bridge these gaps, we introduce Fin-RATE, a benchmark built on U.S. Securities and Exchange Commission (SEC) filings and mirror financial analyst workflows through three pathways: detail-oriented reasoning within individual disclosures, cross-entity comparison under shared topics, and longitudinal tracking of the same firm across reporting periods. We benchmark 17 leading LLMs, spanning open-source, closed-source, and finance-specialized models, under both ground-truth context and retrieval-augmented settings. Results show substantial performance degradation, with accuracy dropping by 18.60% and 14.35% as tasks shift from single-document reasoning to longitudinal and cross-entity analysis. This is driven by rising comparison hallucinations, time and entity mismatches, and mirrored by declines in reasoning and factuality--limitations that prior benchmarks have yet to formally categorize or quantify.
Multi-Modal Time Series Prediction via Mixture of Modulated Experts
Jan 29, 2026Real-world time series exhibit complex and evolving dynamics, making accurate forecasting extremely challenging. Recent multi-modal forecasting methods leverage textual information such as news reports to improve prediction, but most rely on token-level fusion that mixes temporal patches with language tokens in a shared embedding space. However, such fusion can be ill-suited when high-quality time-text pairs are scarce and when time series exhibit substantial variation in scale and characteristics, thus complicating cross-modal alignment. In parallel, Mixture-of-Experts (MoE) architectures have proven effective for both time series modeling and multi-modal learning, yet many existing MoE-based modality integration methods still depend on token-level fusion. To address this, we propose Expert Modulation, a new paradigm for multi-modal time series prediction that conditions both routing and expert computation on textual signals, enabling direct and efficient cross-modal control over expert behavior. Through comprehensive theoretical analysis and experiments, our proposed method demonstrates substantial improvements in multi-modal time series prediction. The current code is available at https://github.com/BruceZhangReve/MoME
JamShield: A Machine Learning Detection System for Over-the-Air Jamming Attacks
Jul 15, 2025Wireless networks are vulnerable to jamming attacks due to the shared communication medium, which can severely degrade performance and disrupt services. Despite extensive research, current jamming detection methods often rely on simulated data or proprietary over-the-air datasets with limited cross-layer features, failing to accurately represent the real state of a network and thus limiting their effectiveness in real-world scenarios. To address these challenges, we introduce JamShield, a dynamic jamming detection system trained on our own collected over-the-air and publicly available dataset. It utilizes hybrid feature selection to prioritize relevant features for accurate and efficient detection. Additionally, it includes an auto-classification module that dynamically adjusts the classification algorithm in real-time based on current network conditions. Our experimental results demonstrate significant improvements in detection rate, precision, and recall, along with reduced false alarms and misdetections compared to state-of-the-art detection algorithms, making JamShield a robust and reliable solution for detecting jamming attacks in real-world wireless networks.
TRACE: Grounding Time Series in Context for Multimodal Embedding and Retrieval
Jun 10, 2025The ubiquity of dynamic data in domains such as weather, healthcare, and energy underscores a growing need for effective interpretation and retrieval of time-series data. These data are inherently tied to domain-specific contexts, such as clinical notes or weather narratives, making cross-modal retrieval essential not only for downstream tasks but also for developing robust time-series foundation models by retrieval-augmented generation (RAG). Despite the increasing demand, time-series retrieval remains largely underexplored. Existing methods often lack semantic grounding, struggle to align heterogeneous modalities, and have limited capacity for handling multi-channel signals. To address this gap, we propose TRACE, a generic multimodal retriever that grounds time-series embeddings in aligned textual context. TRACE enables fine-grained channel-level alignment and employs hard negative mining to facilitate semantically meaningful retrieval. It supports flexible cross-modal retrieval modes, including Text-to-Timeseries and Timeseries-to-Text, effectively linking linguistic descriptions with complex temporal patterns. By retrieving semantically relevant pairs, TRACE enriches downstream models with informative context, leading to improved predictive accuracy and interpretability. Beyond a static retrieval engine, TRACE also serves as a powerful standalone encoder, with lightweight task-specific tuning that refines context-aware representations while maintaining strong cross-modal alignment. These representations achieve state-of-the-art performance on downstream forecasting and classification tasks. Extensive experiments across multiple domains highlight its dual utility, as both an effective encoder for downstream applications and a general-purpose retriever to enhance time-series models.
HELM: Hyperbolic Large Language Models via Mixture-of-Curvature Experts
May 30, 2025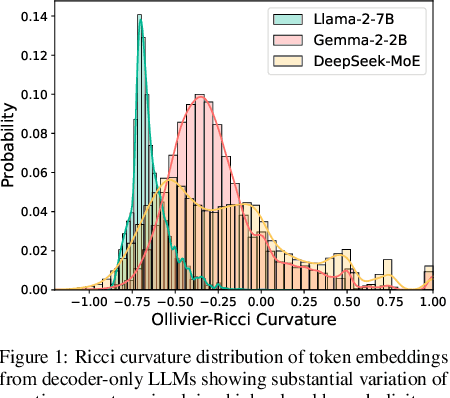
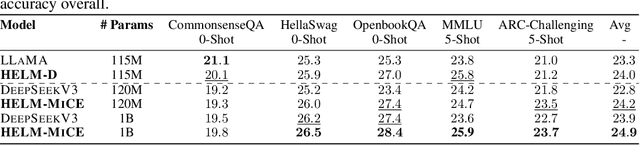
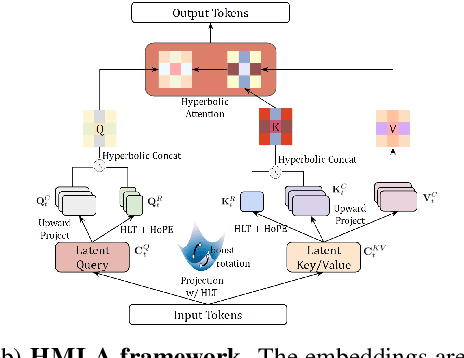

Large language models (LLMs) have shown great success in text modeling tasks across domains. However, natural language exhibits inherent semantic hierarchies and nuanced geometric structure, which current LLMs do not capture completely owing to their reliance on Euclidean operations. Recent studies have also shown that not respecting the geometry of token embeddings leads to training instabilities and degradation of generative capabilities. These findings suggest that shifting to non-Euclidean geometries can better align language models with the underlying geometry of text. We thus propose to operate fully in Hyperbolic space, known for its expansive, scale-free, and low-distortion properties. We thus introduce HELM, a family of HypErbolic Large Language Models, offering a geometric rethinking of the Transformer-based LLM that addresses the representational inflexibility, missing set of necessary operations, and poor scalability of existing hyperbolic LMs. We additionally introduce a Mixture-of-Curvature Experts model, HELM-MICE, where each expert operates in a distinct curvature space to encode more fine-grained geometric structure from text, as well as a dense model, HELM-D. For HELM-MICE, we further develop hyperbolic Multi-Head Latent Attention (HMLA) for efficient, reduced-KV-cache training and inference. For both models, we develop essential hyperbolic equivalents of rotary positional encodings and RMS normalization. We are the first to train fully hyperbolic LLMs at billion-parameter scale, and evaluate them on well-known benchmarks such as MMLU and ARC, spanning STEM problem-solving, general knowledge, and commonsense reasoning. Our results show consistent gains from our HELM architectures -- up to 4% -- over popular Euclidean architectures used in LLaMA and DeepSeek, highlighting the efficacy and enhanced reasoning afforded by hyperbolic geometry in large-scale LM pretraining.
Ethereum Price Prediction Employing Large Language Models for Short-term and Few-shot Forecasting
Mar 29, 2025Cryptocurrencies have transformed financial markets with their innovative blockchain technology and volatile price movements, presenting both challenges and opportunities for predictive analytics. Ethereum, being one of the leading cryptocurrencies, has experienced significant market fluctuations, making its price prediction an attractive yet complex problem. This paper presents a comprehensive study on the effectiveness of Large Language Models (LLMs) in predicting Ethereum prices for short-term and few-shot forecasting scenarios. The main challenge in training models for time series analysis is the lack of data. We address this by leveraging a novel approach that adapts existing pre-trained LLMs on natural language or images from billions of tokens to the unique characteristics of Ethereum price time series data. Through thorough experimentation and comparison with traditional and contemporary models, our results demonstrate that selectively freezing certain layers of pre-trained LLMs achieves state-of-the-art performance in this domain. This approach consistently surpasses benchmarks across multiple metrics, including Mean Squared Error (MSE), Mean Absolute Error (MAE), and Root Mean Squared Error (RMSE), demonstrating its effectiveness and robustness. Our research not only contributes to the existing body of knowledge on LLMs but also provides practical insights in the cryptocurrency prediction domain. The adaptability of pre-trained LLMs to handle the nature of Ethereum prices suggests a promising direction for future research, potentially including the integration of sentiment analysis to further refine forecasting accuracy.