 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RAFT: Adapting Language Model to Domain Specific RAG
Mar 15, 2024

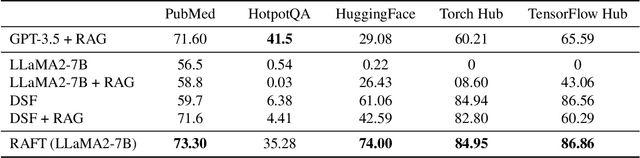
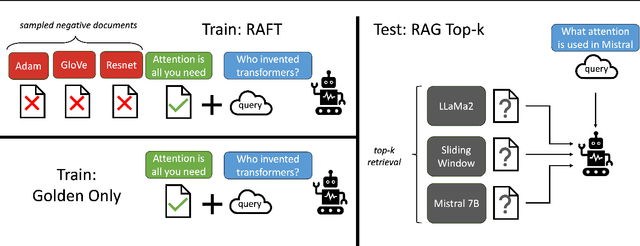
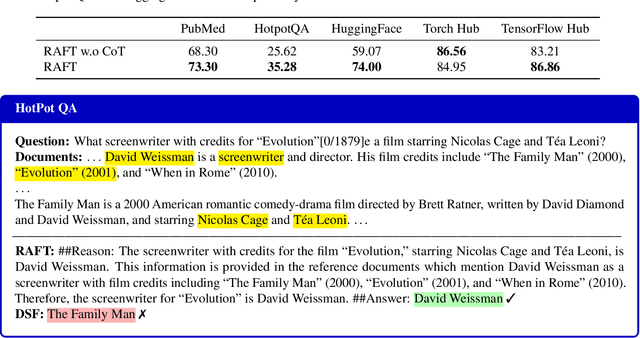
Pretraining Large Language Models (LLMs) on large corpora of textual data is now a standard paradigm. When using these LLMs for many downstream applications, it is common to additionally bake in new knowledge (e.g., time-critical news, or private domain knowledge) into the pretrained model either through RAG-based-prompting, or fine-tuning. However, the optimal methodology for the model to gain such new knowledge remains an open question. In this paper, we present Retrieval Augmented FineTuning (RAFT), a training recipe that improves the model's ability to answer questions in a "open-book" in-domain settings. In RAFT, given a question, and a set of retrieved documents, we train the model to ignore those documents that don't help in answering the question, which we call, distractor documents. RAFT accomplishes this by citing verbatim the right sequence from the relevant document that would help answer the question. This coupled with RAFT's chain-of-thought-style response helps improve the model's ability to reason. In domain-specific RAG, RAFT consistently improves the model's performance across PubMed, HotpotQA, and Gorilla datasets, presenting a post-training recipe to improve pre-trained LLMs to in-domain RAG. RAFT's code and demo are open-sourced at github.com/ShishirPatil/gorilla.
Lifelong Person Re-Identification with Backward-Compatibility
Mar 15, 2024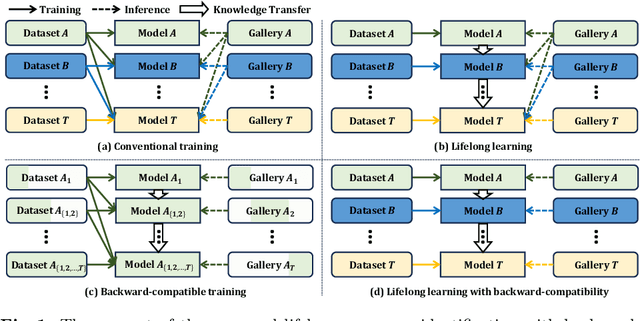
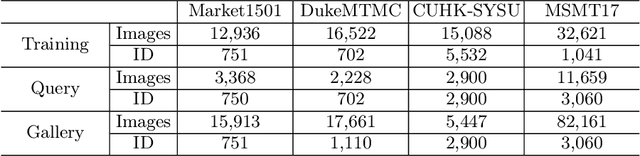
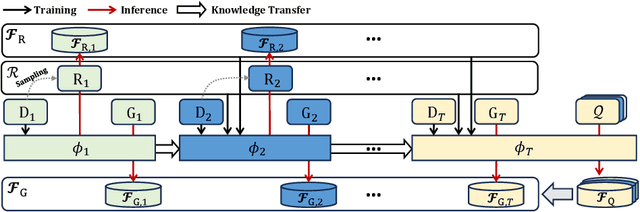
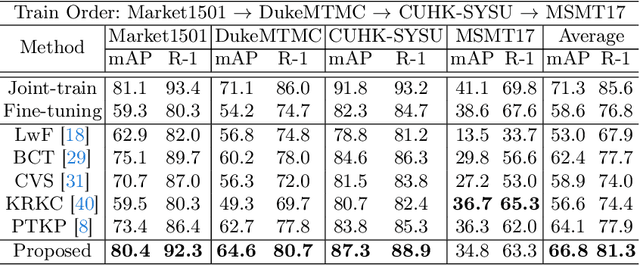
Lifelong person re-identification (LReID) assumes a practical scenario where the model is sequentially trained on continuously incoming datasets while alleviating the catastrophic forgetting in the old datasets. However, not only the training datasets but also the gallery images are incrementally accumulated, that requires a huge amount of computational complexity and storage space to extract the features at the inference phase. In this paper, we address the above mentioned problem by incorporating the backward-compatibility to LReID for the first time. We train the model using the continuously incoming datasets while maintaining the model's compatibility toward the previously trained old models without re-computing the features of the old gallery images. To this end, we devise the cross-model compatibility loss based on the contrastive learning with respect to the replay features across all the old datasets. Moreover, we also develop the knowledge consolidation method based on the part classification to learn the shared representation across different datasets for the backward-compatibility. We suggest a more practical methodology for performance evaluation as well where all the gallery and query images are considered together. Experimental results demonstrate that the proposed method achieves a significantly higher performance of the backward-compatibility compared with the existing methods. It is a promising tool for more practical scenarios of LReID.
TRG-Net: An Interpretable and Controllable Rain Generator
Mar 15, 2024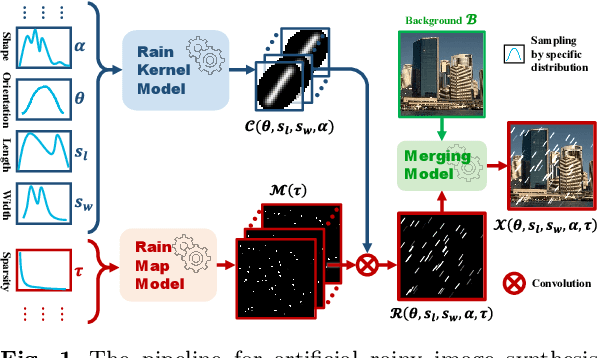
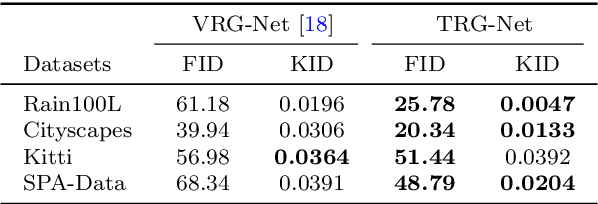
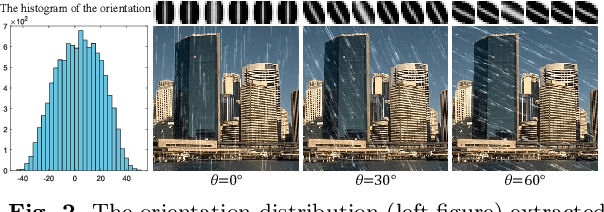
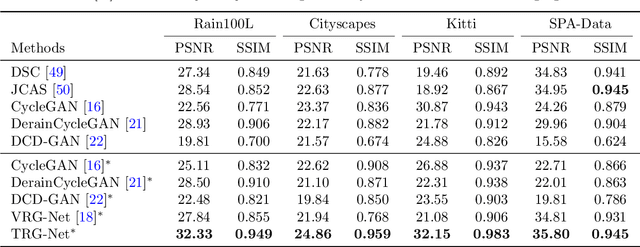
Exploring and modeling rain generation mechanism is critical for augmenting paired data to ease training of rainy image processing models. Against this task, this study proposes a novel deep learning based rain generator, which fully takes the physical generation mechanism underlying rains into consideration and well encodes the learning of the fundamental rain factors (i.e., shape, orientation, length, width and sparsity) explicitly into the deep network. Its significance lies in that the generator not only elaborately design essential elements of the rain to simulate expected rains, like conventional artificial strategies, but also finely adapt to complicated and diverse practical rainy images, like deep learning methods. By rationally adopting filter parameterization technique, we first time achieve a deep network that is finely controllable with respect to rain factors and able to learn the distribution of these factors purely from data. Our unpaired generation experiments demonstrate that the rain generated by the proposed rain generator is not only of higher quality, but also more effective for deraining and downstream tasks compared to current state-of-the-art rain generation methods. Besides, the paired data augmentation experiments, including both in-distribution and out-of-distribution (OOD), further validate the diversity of samples generated by our model for in-distribution deraining and OOD generalization tasks.
Comprehensive Study Of Predictive Maintenance In Industries Using Classification Models And LSTM Model
Mar 15, 2024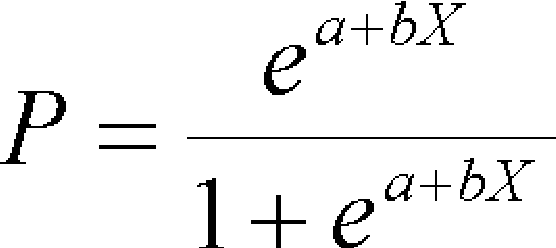
In today's technology-driven era, the imperative for predictive maintenance and advanced diagnostics extends beyond aviation to encompass the identification of damages, failures, and operational defects in rotating and moving machines. Implementing such services not only curtails maintenance costs but also extends machine lifespan, ensuring heightened operational efficiency. Moreover, it serves as a preventive measure against potential accidents or catastrophic events. The advent of Artificial Intelligence (AI) has revolutionized maintenance across industries, enabling more accurate and efficient prediction and analysis of machine failures, thereby conserving time and resources. Our proposed study aims to delve into various machine learning classification techniques, including Support Vector Machine (SVM), Random Forest, Logistic Regression, and Convolutional Neural Network LSTM-Based, for predicting and analyzing machine performance. SVM classifies data into different categories based on their positions in a multidimensional space, while Random Forest employs ensemble learning to create multiple decision trees for classification. Logistic Regression predicts the probability of binary outcomes using input data. The primary objective of the study is to assess these algorithms' performance in predicting and analyzing machine performance, considering factors such as accuracy, precision, recall, and F1 score. The findings will aid maintenance experts in selecting the most suitable machine learning algorithm for effective prediction and analysis of machine performance.
Generation is better than Modification: Combating High Class Homophily Variance in Graph Anomaly Detection
Mar 15, 2024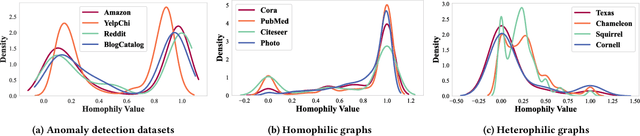
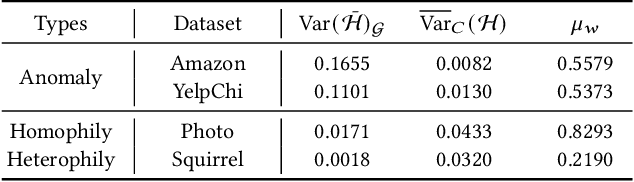
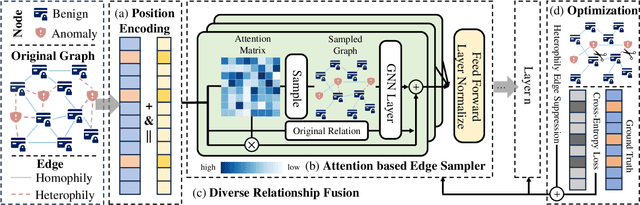
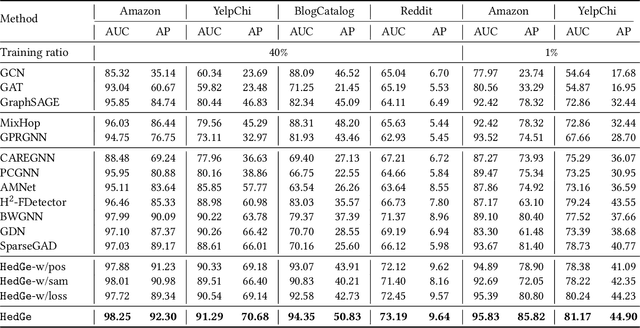
Graph-based anomaly detection is currently an important research topic in the field of graph neural networks (GNNs). We find that in graph anomaly detection, the homophily distribution differences between different classes are significantly greater than those in homophilic and heterophilic graphs. For the first time, we introduce a new metric called Class Homophily Variance, which quantitatively describes this phenomenon. To mitigate its impact, we propose a novel GNN model named Homophily Edge Generation Graph Neural Network (HedGe). Previous works typically focused on pruning, selecting or connecting on original relationships, and we refer to these methods as modifications. Different from these works, our method emphasizes generating new relationships with low class homophily variance, using the original relationships as an auxiliary. HedGe samples homophily adjacency matrices from scratch using a self-attention mechanism, and leverages nodes that are relevant in the feature space but not directly connected in the original graph. Additionally, we modify the loss function to punish the generation of unnecessary heterophilic edges by the model. Extensive comparison experiments demonstrate that HedGe achieved the best performance across multiple benchmark datasets, including anomaly detection and edgeless node classification. The proposed model also improves the robustness under the novel Heterophily Attack with increased class homophily variance on other graph classification tasks.
CSDNet: Detect Salient Object in Depth-Thermal via A Lightweight Cross Shallow and Deep Perception Network
Mar 15, 2024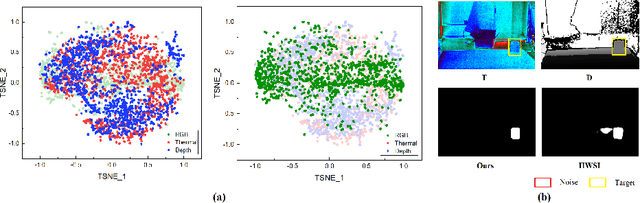
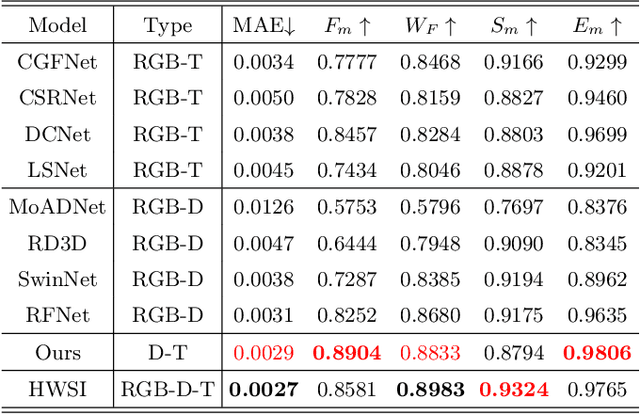
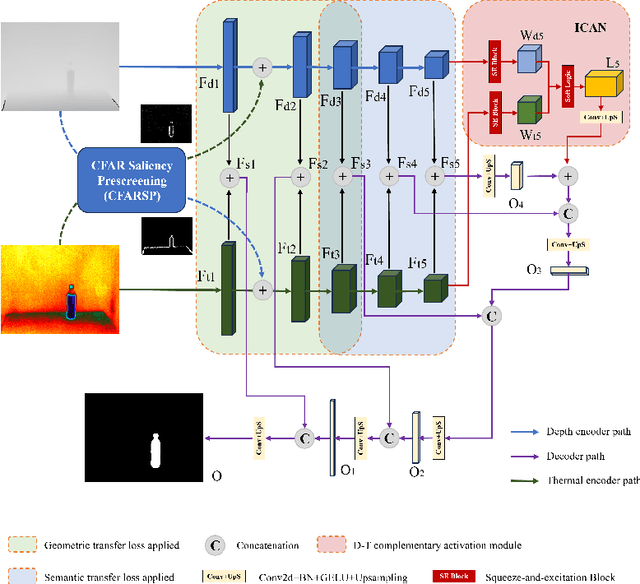
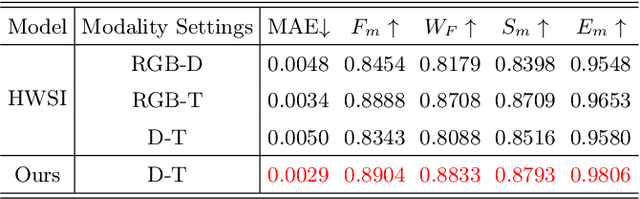
While we enjoy the richness and informativeness of multimodal data, it also introduces interference and redundancy of information. To achieve optimal domain interpretation with limited resources, we propose CSDNet, a lightweight \textbf{C}ross \textbf{S}hallow and \textbf{D}eep Perception \textbf{Net}work designed to integrate two modalities with less coherence, thereby discarding redundant information or even modality. We implement our CSDNet for Salient Object Detection (SOD) task in robotic perception. The proposed method capitalises on spatial information prescreening and implicit coherence navigation across shallow and deep layers of the depth-thermal (D-T) modality, prioritising integration over fusion to maximise the scene interpretation. To further refine the descriptive capabilities of the encoder for the less-known D-T modalities, we also propose SAMAEP to guide an effective feature mapping to the generalised feature space. Our approach is tested on the VDT-2048 dataset, leveraging the D-T modality outperforms those of SOTA methods using RGB-T or RGB-D modalities for the first time, achieves comparable performance with the RGB-D-T triple-modality benchmark method with 5.97 times faster at runtime and demanding 0.0036 times fewer FLOPs. Demonstrates the proposed CSDNet effectively integrates the information from the D-T modality. The code will be released upon acceptance.
Robust Shape Fitting for 3D Scene Abstraction
Mar 15, 2024
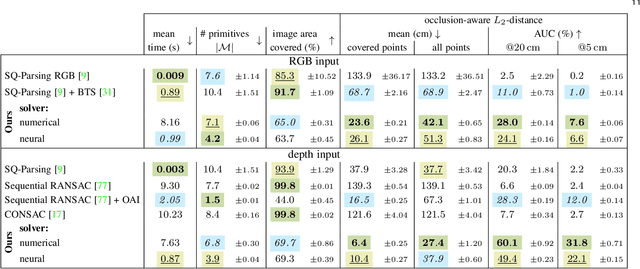
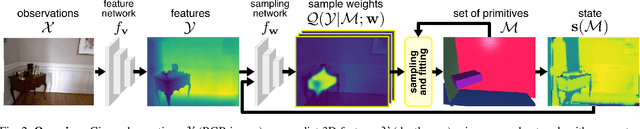

Humans perceive and construct the world as an arrangement of simple parametric models. In particular, we can often describe man-made environments using volumetric primitives such as cuboids or cylinders. Inferring these primitives is important for attaining high-level, abstract scene descriptions. Previous approaches for primitive-based abstraction estimate shape parameters directly and are only able to reproduce simple objects. In contrast, we propose a robust estimator for primitive fitting, which meaningfully abstracts complex real-world environments using cuboids. A RANSAC estimator guided by a neural network fits these primitives to a depth map. We condition the network on previously detected parts of the scene, parsing it one-by-one. To obtain cuboids from single RGB images, we additionally optimise a depth estimation CNN end-to-end. Naively minimising point-to-primitive distances leads to large or spurious cuboids occluding parts of the scene. We thus propose an improved occlusion-aware distance metric correctly handling opaque scenes. Furthermore, we present a neural network based cuboid solver which provides more parsimonious scene abstractions while also reducing inference time. The proposed algorithm does not require labour-intensive labels, such as cuboid annotations, for training. Results on the NYU Depth v2 dataset demonstrate that the proposed algorithm successfully abstracts cluttered real-world 3D scene layouts.
Introducing Adaptive Continuous Adversarial Training (ACAT) to Enhance ML Robustness
Mar 15, 2024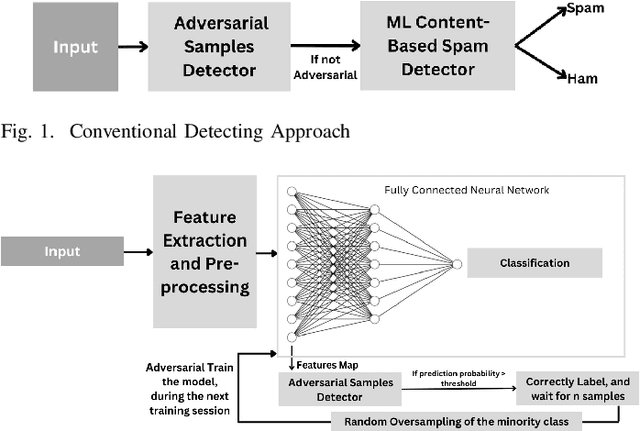
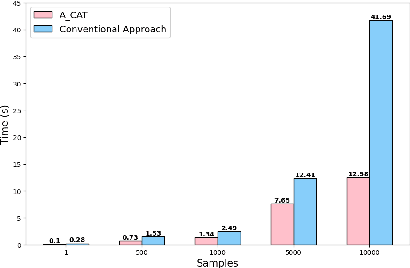
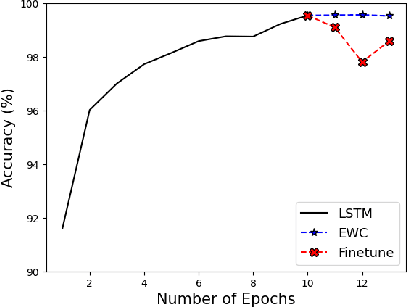
Machine Learning (ML) is susceptible to adversarial attacks that aim to trick ML models, making them produce faulty predictions. Adversarial training was found to increase the robustness of ML models against these attacks. However, in network and cybersecurity, obtaining labeled training and adversarial training data is challenging and costly. Furthermore, concept drift deepens the challenge, particularly in dynamic domains like network and cybersecurity, and requires various models to conduct periodic retraining. This letter introduces Adaptive Continuous Adversarial Training (ACAT) to continuously integrate adversarial training samples into the model during ongoing learning sessions, using real-world detected adversarial data, to enhance model resilience against evolving adversarial threats. ACAT is an adaptive defense mechanism that utilizes periodic retraining to effectively counter adversarial attacks while mitigating catastrophic forgetting. Our approach also reduces the total time required for adversarial sample detection, especially in environments such as network security where the rate of attacks could be very high. Traditional detection processes that involve two stages may result in lengthy procedures. Experimental results using a SPAM detection dataset demonstrate that with ACAT, the accuracy of the SPAM filter increased from 69% to over 88% after just three retraining sessions. Furthermore, ACAT outperforms conventional adversarial sample detectors, providing faster decision times, up to four times faster in some cases.
Cardiac valve event timing in echocardiography using deep learning and triplane recordings
Mar 15, 2024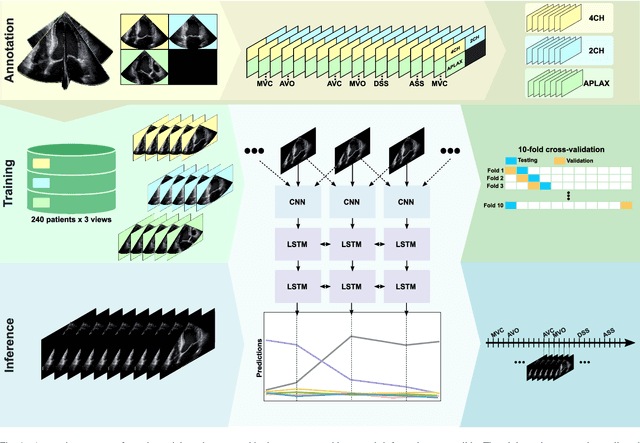
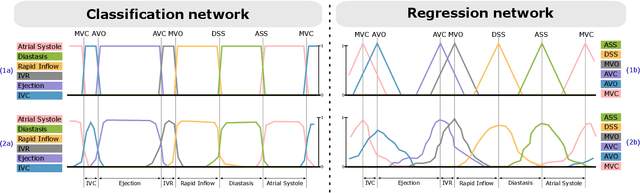
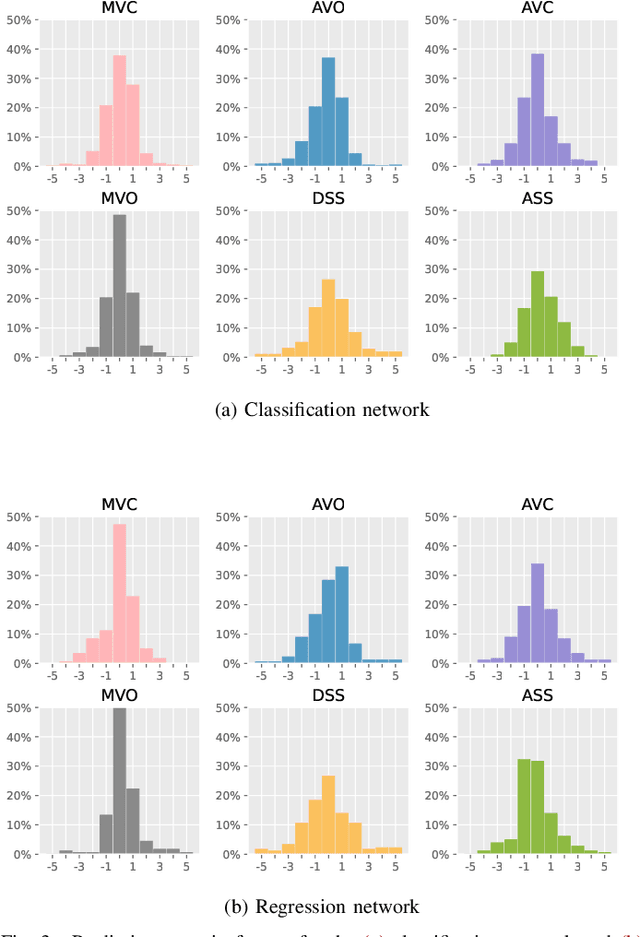

Cardiac valve event timing plays a crucial role when conducting clinical measurements using echocardiography. However, established automated approaches are limited by the need of external electrocardiogram sensors, and manual measurements often rely on timing from different cardiac cycles. Recent methods have applied deep learning to cardiac timing, but they have mainly been restricted to only detecting two key time points, namely end-diastole (ED) and end-systole (ES). In this work, we propose a deep learning approach that leverages triplane recordings to enhance detection of valve events in echocardiography. Our method demonstrates improved performance detecting six different events, including valve events conventionally associated with ED and ES. Of all events, we achieve an average absolute frame difference (aFD) of maximum 1.4 frames (29 ms) for start of diastasis, down to 0.6 frames (12 ms) for mitral valve opening when performing a ten-fold cross-validation with test splits on triplane data from 240 patients. On an external independent test consisting of apical long-axis data from 180 other patients, the worst performing event detection had an aFD of 1.8 (30 ms). The proposed approach has the potential to significantly impact clinical practice by enabling more accurate, rapid and comprehensive event detection, leading to improved clinical measurements.
Data Interpreter: An LLM Agent For Data Science
Mar 12, 2024Large Language Model (LLM)-based agents have demonstrated remarkable effectiveness. However, their performance can be compromised in data science scenarios that require real-time data adjustment, expertise in optimization due to complex dependencies among various tasks, and the ability to identify logical errors for precise reasoning. In this study, we introduce the Data Interpreter, a solution designed to solve with code that emphasizes three pivotal techniques to augment problem-solving in data science: 1) dynamic planning with hierarchical graph structures for real-time data adaptability;2) tool integration dynamically to enhance code proficiency during execution, enriching the requisite expertise;3) logical inconsistency identification in feedback, and efficiency enhancement through experience recording. We evaluate the Data Interpreter on various data science and real-world tasks. Compared to open-source baselines, it demonstrated superior performance, exhibiting significant improvements in machine learning tasks, increasing from 0.86 to 0.95. Additionally, it showed a 26% increase in the MATH dataset and a remarkable 112% improvement in open-ended tasks. The solution will be released at https://github.com/geekan/MetaGPT.